宣传 网站建设方案,seo推广排名重要吗,贵州软件定制,做一个app需要学什么原文地址 原文代码 pytorch实现1 pytorch实现2 详细讲解 文章目录EfficientNet中存在的问题NAS 搜索EfficientNetV2 网络结构codeEfficientNet中存在的问题
训练图像尺寸大时#xff0c;训练速度非常慢。train size 512, batch 24时#xff0c;V100 out of memory在网络浅… 原文地址 原文代码 pytorch实现1 pytorch实现2 详细讲解 文章目录EfficientNet中存在的问题NAS 搜索EfficientNetV2 网络结构codeEfficientNet中存在的问题
训练图像尺寸大时训练速度非常慢。train size 512, batch 24时V100 out of memory在网络浅层中使用Depthwise convolutions速度会很慢。因此将原本EfficientNet中的conv1x1 and depthwise conv3x3 (MBConv)替换成conv3x3 (Fused-MBCon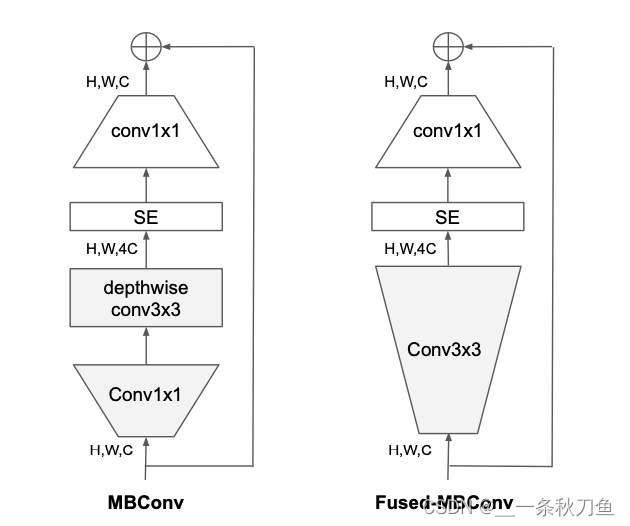 v)。但如果将所有的conv1x1 and depthwise conv3x3都替换成conv3x3后会明显增加参数数量降低训练速度因此使用NAS技术去搜索两者的最佳组合。 同等放大每个stage是次优的因为每个stage对网络的训练速度以及参数量贡献不同。
NAS 搜索
与EfficientNet相同但这次的NAS搜索采用了联合优化策略联合了accuracy, parameter efficiency, training efficiency三个标准。设计空间包括
convolutional operation types {MBConv, Fused-MBConv}number of layerskernel size {3x3, 5x5}expansion ration {1,4,6} 同时随机采样1000个models并且对每个models进行了10个epochs的训练。搜索奖励结合了模型准确率A标准训练一个step所需要的时间S和参数量P A⋅S−0.07⋅P−0.05A \cdot S^{-0.07} \cdot P^{-0.05} A⋅S−0.07⋅P−0.05
EfficientNetV2 网络结构 与EfficientNet相比EfficientNetV2有以下区别
在浅层网络中大量运用了MBConv和新加入的fused-MBConv使用了较小的expansion ratio可以达到较小的内存访问开销偏向于kernel3x3但这需要增加层数来弥补小kernel感受野的不足移除了last stride-1 stage但是这是由于NAS搜索出来的所以是作者的猜测可能是在参数量和访存开销的优化。
code
# 使用的是https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/blob/master/pytorch_classification/Test11_efficientnetV2/model.py 中的代码from collections import OrderedDict
from functools import partial
from typing import Callable, Optionalimport torch.nn as nn
import torch
from torch import Tensordef drop_path(x, drop_prob: float 0., training: bool False):Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).Deep Networks with Stochastic Depth, https://arxiv.org/pdf/1603.09382.pdfThis function is taken from the rwightman.It can be seen here:https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py#L140if drop_prob 0. or not training:return xkeep_prob 1 - drop_probshape (x.shape[0],) (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNetsrandom_tensor keep_prob torch.rand(shape, dtypex.dtype, devicex.device)random_tensor.floor_() # binarizeoutput x.div(keep_prob) * random_tensorreturn outputclass DropPath(nn.Module):Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).Deep Networks with Stochastic Depth, https://arxiv.org/pdf/1603.09382.pdfdef __init__(self, drop_probNone):super(DropPath, self).__init__()self.drop_prob drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)class ConvBNAct(nn.Module):def __init__(self,in_planes: int,out_planes: int,kernel_size: int 3,stride: int 1,groups: int 1,norm_layer: Optional[Callable[..., nn.Module]] None,activation_layer: Optional[Callable[..., nn.Module]] None):super(ConvBNAct, self).__init__()padding (kernel_size - 1) // 2if norm_layer is None:norm_layer nn.BatchNorm2dif activation_layer is None:activation_layer nn.SiLU # alias Swish (torch1.7)self.conv nn.Conv2d(in_channelsin_planes,out_channelsout_planes,kernel_sizekernel_size,stridestride,paddingpadding,groupsgroups,biasFalse)self.bn norm_layer(out_planes)self.act activation_layer()def forward(self, x):result self.conv(x)result self.bn(result)result self.act(result)return resultclass SqueezeExcite(nn.Module):def __init__(self,input_c: int, # block input channelexpand_c: int, # block expand channelse_ratio: float 0.25):super(SqueezeExcite, self).__init__()squeeze_c int(input_c * se_ratio)self.conv_reduce nn.Conv2d(expand_c, squeeze_c, 1)self.act1 nn.SiLU() # alias Swishself.conv_expand nn.Conv2d(squeeze_c, expand_c, 1)self.act2 nn.Sigmoid()def forward(self, x: Tensor) - Tensor:scale x.mean((2, 3), keepdimTrue)scale self.conv_reduce(scale)scale self.act1(scale)scale self.conv_expand(scale)scale self.act2(scale)return scale * xclass MBConv(nn.Module):def __init__(self,kernel_size: int,input_c: int,out_c: int,expand_ratio: int,stride: int,se_ratio: float,drop_rate: float,norm_layer: Callable[..., nn.Module]):super(MBConv, self).__init__()if stride not in [1, 2]:raise ValueError(illegal stride value.)self.has_shortcut (stride 1 and input_c out_c)activation_layer nn.SiLU # alias Swishexpanded_c input_c * expand_ratio# 在EfficientNetV2中MBConv中不存在expansion1的情况所以conv_pw肯定存在assert expand_ratio ! 1# Point-wise expansionself.expand_conv ConvBNAct(input_c,expanded_c,kernel_size1,norm_layernorm_layer,activation_layeractivation_layer)# Depth-wise convolutionself.dwconv ConvBNAct(expanded_c,expanded_c,kernel_sizekernel_size,stridestride,groupsexpanded_c,norm_layernorm_layer,activation_layeractivation_layer)self.se SqueezeExcite(input_c, expanded_c, se_ratio) if se_ratio 0 else nn.Identity()# Point-wise linear projectionself.project_conv ConvBNAct(expanded_c,out_planesout_c,kernel_size1,norm_layernorm_layer,activation_layernn.Identity) # 注意这里没有激活函数所有传入Identityself.out_channels out_c# 只有在使用shortcut连接时才使用dropout层self.drop_rate drop_rateif self.has_shortcut and drop_rate 0:self.dropout DropPath(drop_rate)def forward(self, x: Tensor) - Tensor:result self.expand_conv(x)result self.dwconv(result)result self.se(result)result self.project_conv(result)if self.has_shortcut:if self.drop_rate 0:result self.dropout(result)result xreturn resultclass FusedMBConv(nn.Module):def __init__(self,kernel_size: int,input_c: int,out_c: int,expand_ratio: int,stride: int,se_ratio: float,drop_rate: float,norm_layer: Callable[..., nn.Module]):super(FusedMBConv, self).__init__()assert stride in [1, 2]assert se_ratio 0self.has_shortcut stride 1 and input_c out_cself.drop_rate drop_rateself.has_expansion expand_ratio ! 1activation_layer nn.SiLU # alias Swishexpanded_c input_c * expand_ratio# 只有当expand ratio不等于1时才有expand convif self.has_expansion:# Expansion convolutionself.expand_conv ConvBNAct(input_c,expanded_c,kernel_sizekernel_size,stridestride,norm_layernorm_layer,activation_layeractivation_layer)self.project_conv ConvBNAct(expanded_c,out_c,kernel_size1,norm_layernorm_layer,activation_layernn.Identity) # 注意没有激活函数else:# 当只有project_conv时的情况self.project_conv ConvBNAct(input_c,out_c,kernel_sizekernel_size,stridestride,norm_layernorm_layer,activation_layeractivation_layer) # 注意有激活函数self.out_channels out_c# 只有在使用shortcut连接时才使用dropout层self.drop_rate drop_rateif self.has_shortcut and drop_rate 0:self.dropout DropPath(drop_rate)def forward(self, x: Tensor) - Tensor:if self.has_expansion:result self.expand_conv(x)result self.project_conv(result)else:result self.project_conv(x)if self.has_shortcut:if self.drop_rate 0:result self.dropout(result)result xreturn resultclass EfficientNetV2(nn.Module):def __init__(self,model_cnf: list,num_classes: int 1000,num_features: int 1280,dropout_rate: float 0.2,drop_connect_rate: float 0.2):super(EfficientNetV2, self).__init__()for cnf in model_cnf:assert len(cnf) 8norm_layer partial(nn.BatchNorm2d, eps1e-3, momentum0.1)stem_filter_num model_cnf[0][4]self.stem ConvBNAct(3,stem_filter_num,kernel_size3,stride2,norm_layernorm_layer) # 激活函数默认是SiLUtotal_blocks sum([i[0] for i in model_cnf])block_id 0blocks []for cnf in model_cnf:repeats cnf[0]op FusedMBConv if cnf[-2] 0 else MBConvfor i in range(repeats):blocks.append(op(kernel_sizecnf[1],input_ccnf[4] if i 0 else cnf[5],out_ccnf[5],expand_ratiocnf[3],stridecnf[2] if i 0 else 1,se_ratiocnf[-1],drop_ratedrop_connect_rate * block_id / total_blocks,norm_layernorm_layer))block_id 1self.blocks nn.Sequential(*blocks)head_input_c model_cnf[-1][-3]head OrderedDict()head.update({project_conv: ConvBNAct(head_input_c,num_features,kernel_size1,norm_layernorm_layer)}) # 激活函数默认是SiLUhead.update({avgpool: nn.AdaptiveAvgPool2d(1)})head.update({flatten: nn.Flatten()})if dropout_rate 0:head.update({dropout: nn.Dropout(pdropout_rate, inplaceTrue)})head.update({classifier: nn.Linear(num_features, num_classes)})self.head nn.Sequential(head)# initial weightsfor m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, modefan_out)if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.BatchNorm2d):nn.init.ones_(m.weight)nn.init.zeros_(m.bias)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.zeros_(m.bias)def forward(self, x: Tensor) - Tensor:x self.stem(x)x self.blocks(x)x self.head(x)return xdef efficientnetv2_s(num_classes: int 1000):EfficientNetV2https://arxiv.org/abs/2104.00298# train_size: 300, eval_size: 384# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratiomodel_config [[2, 3, 1, 1, 24, 24, 0, 0],[4, 3, 2, 4, 24, 48, 0, 0],[4, 3, 2, 4, 48, 64, 0, 0],[6, 3, 2, 4, 64, 128, 1, 0.25],[9, 3, 1, 6, 128, 160, 1, 0.25],[15, 3, 2, 6, 160, 256, 1, 0.25]]model EfficientNetV2(model_cnfmodel_config,num_classesnum_classes,dropout_rate0.2)return modeldef efficientnetv2_m(num_classes: int 1000):EfficientNetV2https://arxiv.org/abs/2104.00298# train_size: 384, eval_size: 480# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratiomodel_config [[3, 3, 1, 1, 24, 24, 0, 0],[5, 3, 2, 4, 24, 48, 0, 0],[5, 3, 2, 4, 48, 80, 0, 0],[7, 3, 2, 4, 80, 160, 1, 0.25],[14, 3, 1, 6, 160, 176, 1, 0.25],[18, 3, 2, 6, 176, 304, 1, 0.25],[5, 3, 1, 6, 304, 512, 1, 0.25]]model EfficientNetV2(model_cnfmodel_config,num_classesnum_classes,dropout_rate0.3)return modeldef efficientnetv2_l(num_classes: int 1000):EfficientNetV2https://arxiv.org/abs/2104.00298# train_size: 384, eval_size: 480# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratiomodel_config [[4, 3, 1, 1, 32, 32, 0, 0],[7, 3, 2, 4, 32, 64, 0, 0],[7, 3, 2, 4, 64, 96, 0, 0],[10, 3, 2, 4, 96, 192, 1, 0.25],[19, 3, 1, 6, 192, 224, 1, 0.25],[25, 3, 2, 6, 224, 384, 1, 0.25],[7, 3, 1, 6, 384, 640, 1, 0.25]]model EfficientNetV2(model_cnfmodel_config,num_classesnum_classes,dropout_rate0.4)return modelfrom torchsummary import summary
device torch.device(cuda:0 if torch.cuda.is_available() else cpu)
model efficientnetv2_l()
model model.to(device)
summary(model, (3,256,256))使用torchsummary输出结果: Total params: 118,515,272
Trainable params: 118,515,272
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 1576.33
Params size (MB): 452.10
Estimated Total Size (MB): 2029.18
----------------------------------------------------------------