个人网站可以做经营性的吗今日头条十大热点

一、说明
我已经解释了什么是注意力机制,以及与转换器相关的一些重要关键字和块,例如自我注意、查询、键和值以及多头注意力。在这一部分中,我将解释这些注意力块如何帮助创建转换器网络,注意、自我注意、多头注意、蒙面多头注意力、变形金刚、BERT 和 GPT。
二、内容:
- RNN 的挑战以及转换器模型如何帮助克服这些挑战(在第 1 部分中介绍)
- 注意力机制 — 自我注意、查询、键、值、多头注意(在第 1 部分中介绍)
- 变压器网络
- GPT 的基础知识(将在第 3 部分中介绍)
- BERT的基础知识(将在第3部分中介绍)
三. 变压器网络
论文 — 注意力就是你所需要的一切 (2017)
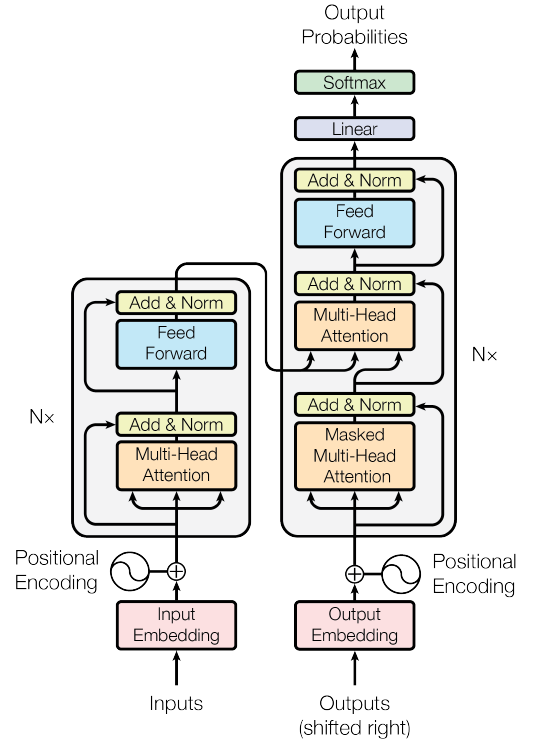
图1.The Transformer Network(来源:图片来源于原文)
图 1 显示了变压器网络。这个网络已经取代了RNN,成为NLP甚至计算机视觉(视觉变压器)的最佳模型。
网络包含两部分 — 编码器和解码器。
在机器翻译中,编码器用于对初始句子进行编码,解码器用于生成翻译后的句子。转换器的编码器可以并行处理整个句子,使其比RNN更快,更好 - RNN一次处理句子的一个单词。
3.1 编码器块

图2.变压器网络的编码器部分(来源:图片来自原文)
编码器网络从输入开始。在这里,整个句子立即被喂食。然后将它们嵌入到“输入嵌入”块中。然后将“位置编码”添加到句子中的每个单词中。这种编码对于理解句子中每个单词的位置至关重要。如果没有位置嵌入,模型会将整个句子视为一个装满单词的袋子,没有任何序列或含义。
详细地:
3.1.1 输入嵌入
— 句子中的单词“dog”可以使用嵌入空间来获取向量嵌入。嵌入只是将任何语言中的单词转换为其向量表示。示例如图 3 所示。在嵌入空间中,相似的单词具有相似的嵌入,例如,单词“cat”和单词“kitty”在嵌入空间中会非常接近,而单词“cat”和“emotion”会在空间中落得更远。

图3.输入嵌入(来源:作者创建的图像)
3.1.2 位置编码
不同句子中的单词可以有不同的含义。例如,单词 dog in a.我养了一只可爱的狗(动物/宠物 - 位置 5)和 b。你真是一条懒狗!(无价值-位置4),有不同的含义。为了帮助进行位置编码。它是一个向量,根据单词在句子中的上下文和位置提供信息。
在任何句子中,单词一个接一个地出现,具有重要意义。如果句子中的单词混乱,那么句子将没有意义。但是当转换器加载句子时,它不会按顺序加载,而是并行加载它们。由于变压器架构在并行加载时不包括单词的顺序,因此我们必须明确定义单词在句子中的位置。这有助于转换器理解句子中的一个单词在另一个单词之后。这就是位置嵌入派上用场的地方。这是一种定义单词位置的矢量编码。在进入注意力网络之前,此位置嵌入被添加到输入嵌入中。图 4 给出了输入嵌入和位置嵌入的直观理解,然后再将其输入到注意力网络中。

图4.直观理解位置嵌入(来源:作者创建的图像)
有多种方法可以定义这些位置嵌入。例如,在原始论文《注意力是你所需要的一切》中,作者使用交替的正弦和余弦函数来定义嵌入,如图5所示。

图5.原论文中使用的位置嵌入(来源:原论文图片)
尽管此嵌入适用于文本数据,但此嵌入不适用于图像数据。因此,可以有多种方式嵌入对象的位置(文本/图像),并且可以在训练过程中固定或学习它们。基本思想是,这种嵌入允许转换器架构理解单词在句子中的位置,而不是通过混淆单词来弄乱含义。
在单词/输入嵌入和位置嵌入完成后,嵌入然后流入编码器最重要的部分,其中包含两个重要块 - “多头注意力”块和“前馈”网络。
3.1.3 多头注意力
这是魔术发生的主要块。要了解多头注意力,请访问此链接 — 2.4 多头注意力。
作为输入,该块接收一个包含子向量(句子中的单词)的向量(句子)。然后,多头注意力计算每个位置与矢量其他位置之间的注意力。

图6.缩放点积注意力(来源:图片来自原始论文)
上图显示了缩放的点积注意力。这与自我注意完全相同,增加了两个块(比例和蒙版)。要详细了解Sef-Attention,请访问此链接 — 2.1 自我关注。
如图 6 所示,缩放注意力完全相同,只是它在第一个矩阵乘法 (Matmul) 之后增加了一个刻度。
缩放比例如下所示,

缩放后的输出将进入遮罩层。这是一个可选层,对机器翻译很有用。

图7.注意力块(来源:作者创建的图像)
图 7 显示了注意力块的神经网络表示。词嵌入首先传递到一些线性层中。这些线性层没有“偏差”项,因此只不过是矩阵乘法。其中一个层表示为“键”,另一个表示为“查询”,最后一个层表示为“值”。如果在键和查询之间执行矩阵乘法,然后规范化,我们得到权重。然后将这些权重乘以值并相加,得到最终的注意力向量。这个块现在可以在神经网络中使用,被称为注意力块。可以添加多个这样的注意力块以提供更多上下文。最好的部分是,我们可以获得梯度反向传播来更新注意力块(键、查询、值的权重)。
多头注意力接收多个键、查询和值,通过多个缩放的点积注意力块馈送它,最后连接注意力以给我们一个最终输出。如图 8 所示。

图8.多头注意力(来源:作者创建的图像)
更简单的解释:主向量(句子)包含子向量(单词)——每个单词都有一个位置嵌入。注意力计算将每个单词视为一个“查询”,并找到一些与句子中其他一些单词对应的“键”,然后采用相应“值”的凸组合。在多头注意力中,选择多个值、查询和键,以提供多重关注(更好的单词嵌入与上下文)。这些多个注意力被连接起来以给出最终的注意力值(来自所有多个注意力的所有单词的上下文组合),这比使用单个注意力块要好得多。
在简单的单词,多头注意力的想法是采用一个单词嵌入,将其与其他一些单词嵌入(或多个单词)结合使用注意力(或多个注意力)来为该单词产生更好的嵌入(嵌入周围单词的更多上下文)。
这个想法是计算每个查询的多个注意力,具有不同的权重。
3.1.4 添加和规范和前馈
下一个块是“添加和规范”,它接收原始单词嵌入的残差连接,将其添加到多头注意力的嵌入中,然后将其归一化为零均值和方差 1。
这被馈送到一个“前馈”块,该块的输出端也有一个“添加和规范”块。
整个多头注意力和前馈块在编码器块中重复n次(超参数)。
3.2 解码器块

图9.变压器网络的解码器部分(Souce:图片来自原始论文)
编码器的输出又是一系列嵌入,每个位置一个嵌入,其中每个位置嵌入不仅包含原始单词在该位置的嵌入,还包含有关其他单词的信息,这些信息是它使用注意力学习的。
然后将其馈送到变压器网络的解码器部分,如图9所示。解码器的目的是产生一些输出。在论文《注意力是你所需要的一切》中,这个解码器被用于句子翻译(比如从英语到法语)。因此,编码器将接收英语句子,解码器将其翻译成法语。在其他应用程序中,网络的解码器部分不是必需的,因此我不会过多地阐述它。
解码器块中的步骤 —
1.在句子翻译中,解码器块接收法语句子(用于英语到法语翻译)。像编码器一样,这里我们添加一个词嵌入和一个位置嵌入,并将其馈送到多头注意力块。
2.自注意力块会为法语句子中的每个单词生成一个注意力向量,以显示句子中一个单词与另一个单词的相关性。
3.然后将法语句子中的注意力向量与英语句子中的注意力向量进行比较。这是英语到法语单词映射发生的部分。
4.在最后几层中,解码器预测英语单词到最佳可能的法语单词的翻译。
5.整个过程重复多次,以获得整个文本数据的翻译。
用于上述每个步骤的模块如图 10 所示。

图 10.不同解码器块在句子翻译中的作用(来源:作者创建的图像)
解码器中有一个新块 - 蒙面多头注意力。所有其他块,我们之前已经在编码器中看到过。
3.2.1Mask多头注意力
这是一个多头注意力块,其中某些值被屏蔽。屏蔽值的概率为空或未选中。
例如,在解码时,输出值应仅取决于以前的输出,而不依赖于未来的输出。然后我们屏蔽未来的输出。
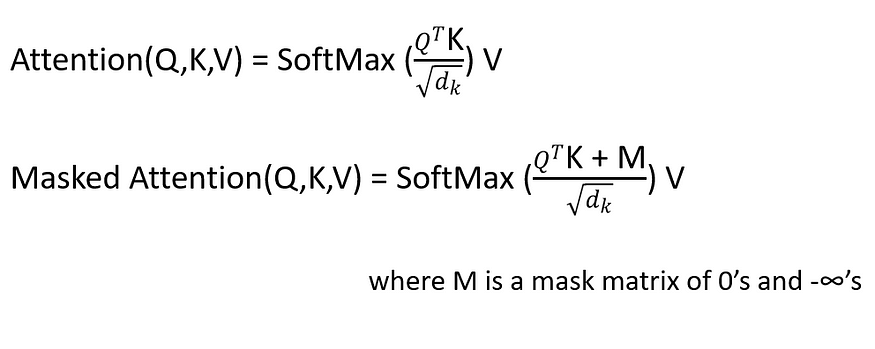
3.3 结果和结论

图 11.结果(来源:原始论文图片)
在论文中,将英语到德语和英语到法语之间的语言翻译与其他最先进的语言模型进行了比较。BLEU是语言翻译比较中使用的度量。从图 11 中,我们看到大型转换器模型在这两个翻译任务中都获得了更高的BLEU分数。他们还显着改善的是培训成本。
总之,变压器模型可以降低计算成本,同时仍然获得最先进的结果。
在这一部分中,我解释了变压器网络的编码器和解码器块,以及如何在语言翻译中使用每个块。在下一部分也是最后一部分(第 3 部分),我将讨论一些最近变得非常有名的重要变压器网络,例如 BERT(来自变压器的双向编码器表示)和 GPT(通用变压器)。
四、引用
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 6000–6010.