家居网站建设公司排名如何免费推广网站
目录
- 爬取思路
- 代码思路
- 1.拿到主页面的源代码. 然后提取到子页面的链接地址, href
- 2.通过href拿到子页面的内容. 从子页面中找到图片的下载地址 img -> src
- 3.下载图片
- 3. 完整实现代码
- 总结
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
爬取思路
一个壁纸网站
https://www.umei.cc/bizhitupian/weimeibizhi/
大体思路
我们要找到这个a标签中的图片的高清大图的下载url
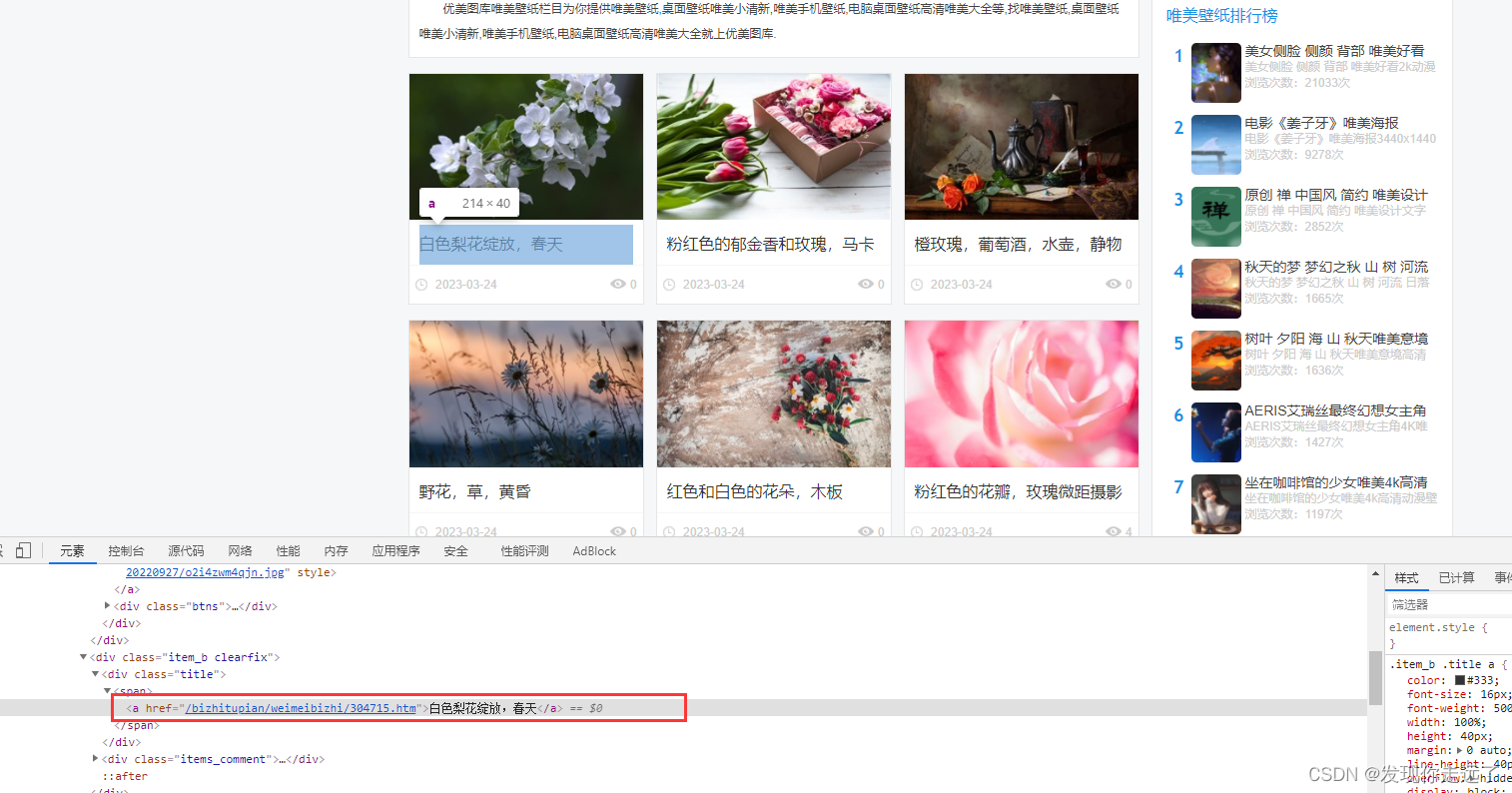
分析发现每个页面a标签上一级都在class=img的div标签包裹下,那我们就抓取所有的这类div标签,然后在for遍历时在每个div中找到a标签,通过get方法得到其中的href地址。
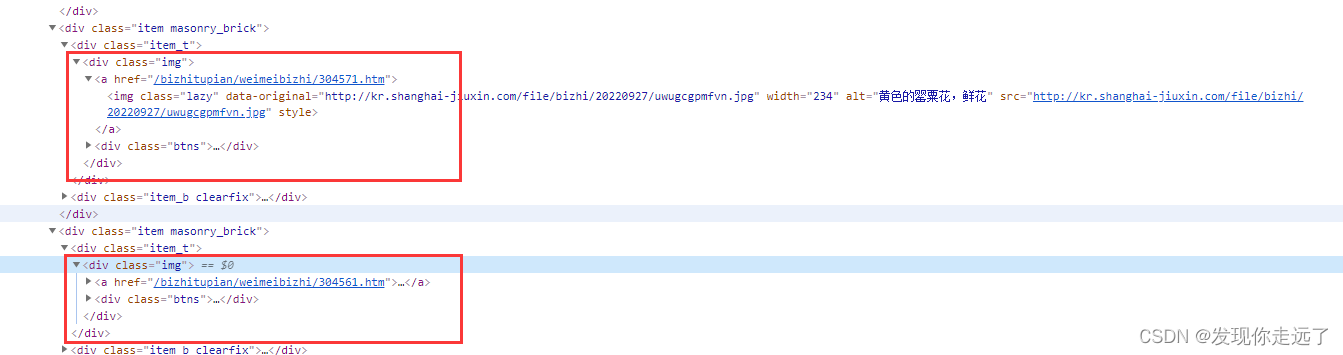
我们比对两张大图的url发现都在div class="big-pic"包裹下


注意我们得到的href还需要加上访问前缀"https://www.umei.cc/"+href这才组成了完整的下载地址。
代码思路
1.拿到主页面的源代码. 然后提取到子页面的链接地址, href
import requests
from bs4 import BeautifulSoup
import timeurl = "https://www.umei.cc/bizhitupian/weimeibizhi/"
resp = requests.get(url)
resp.encoding = 'utf-8' # 处理乱码# print(resp.text)
# 把源代码交给bs
main_page = BeautifulSoup(resp.text, "html.parser")
alist = main_page.find_all("div", class_="img")
print(alist)
2.通过href拿到子页面的内容. 从子页面中找到图片的下载地址 img -> src
href = a.find("a").get('href') # 直接通过get就可以拿到属性的值# 拿到子页面的源代码child_page_resp = requests.get("https://www.umei.cc/"+href)#组合得到子页面图片地址child_page_resp.encoding = 'utf-8'child_page_text = child_page_resp.text# 从子页面中拿到图片的下载路径child_page = BeautifulSoup(child_page_text, "html.parser")child_page_div = child_page.find("div", class_="big-pic")img = child_page_div.find("img")src = img.get("src")
3.下载图片
# 下载图片img_resp = requests.get(src)# img_resp.content # 这里拿到的是字节img_name = src.split("/")[-1] # 拿到url中的最后一个/以后的内容with open("img/"+img_name, mode="wb") as f:f.write(img_resp.content) # 图片内容写入文件print("over!!!", img_name)time.sleep(1)#休息延迟
3. 完整实现代码
import requests
from bs4 import BeautifulSoup
import timeurl = "https://www.umei.cc/bizhitupian/weimeibizhi/"
resp = requests.get(url)
resp.encoding = 'utf-8' # 处理乱码# print(resp.text)
# 把源代码交给bs
main_page = BeautifulSoup(resp.text, "html.parser")
alist = main_page.find_all("div", class_="img")
print(alist)
for a in alist[0:10]:#爬取前面10张如果去掉 [0:10] 就表示爬取当前页面的所有,比较慢,不建议使用。也可能会影响网站的负载href = a.find("a").get('href') # 直接通过get就可以拿到属性的值# 拿到子页面的源代码child_page_resp = requests.get("https://www.umei.cc/"+href)#组合得到子页面图片地址child_page_resp.encoding = 'utf-8'child_page_text = child_page_resp.text# 从子页面中拿到图片的下载路径child_page = BeautifulSoup(child_page_text, "html.parser")child_page_div = child_page.find("div", class_="big-pic")img = child_page_div.find("img")src = img.get("src")# 下载图片img_resp = requests.get(src)# img_resp.content # 这里拿到的是字节img_name = src.split("/")[-1] # 拿到url中的最后一个/以后的内容with open("img/"+img_name, mode="wb") as f:f.write(img_resp.content) # 图片内容写入文件print("over!!!", img_name)time.sleep(1)#休息延迟print("all over!!!")爬取结果
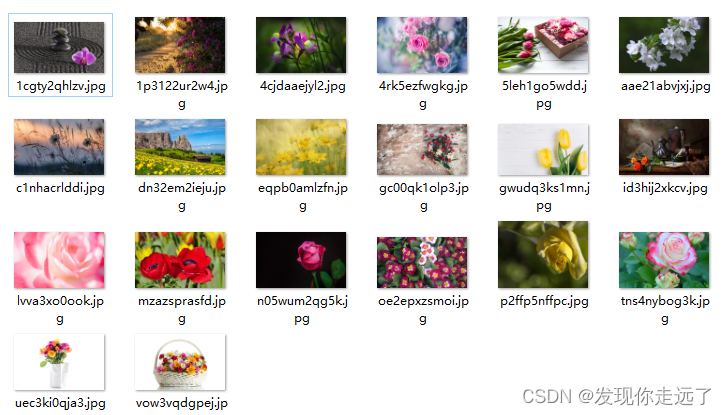
高清大图
总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2023 mzh
Crated:2023-3-1
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
『未完待续』