discuz可以做商城网站吗怎样免费给自己的公司做网站
前期《文档智能》专栏详细中介绍了文档智能解析详细pipline链路技术方案,如下图:
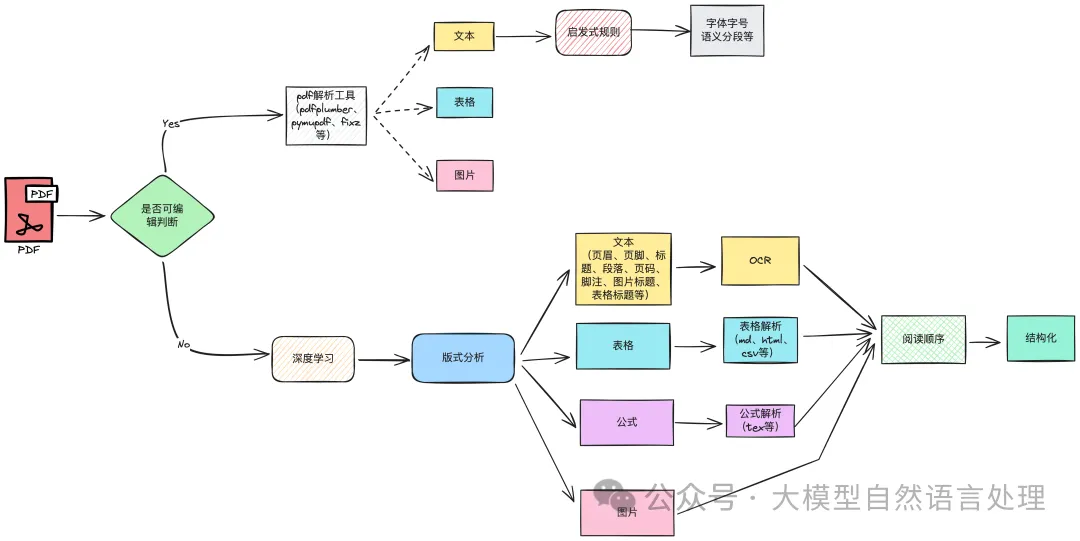
现在来看一个新思路,指出pipline链路依赖大量标注数据、并且会出现错误传播问题,导致解析效果不佳,故提出一个基于布局强化学习(layoutRL)的多模态大模型的端到端的解析框架,通过强化学习(GRPO)的方式训练模型的布局感知能力。(ps:笔者看来,在通用场景下解析效果也能并不会有文中评价的那么好,但这个数据合成思路及强化学习的训练方式可以参考。)
方法
如下图所示,方法分两步走:数据合成和GRPO强化学习训练多模态文档解析模型。

1、数据集构建

为了构建Infinity-Doc-55K,设计了一个双管道框架,结合了合成和真实世界文档生成。数据细节如上图:数据集涵盖了七个不同的文档领域(ps:说实话,这个场景数量还不够多)。
1.1、真实世界数据

这一个还是联合了pipline解析流程中的专家小模型,收集了来自金融报告、医疗记录、学术论文、书籍、杂志和网页等多样化的扫描文档。为了生成标注数据,其中专业模型处理不同的结构元素,如布局块、文本、公式和表格。
- 布局分析:使用视觉布局模型分析整体布局。
- 公式识别:使用专门的公式识别模型处理公式区域。
- 表格解析:使用基于Transformer的表格提取器解析表格。
然后通过交叉验证机制,比较专家模型和VLM的输出,过滤掉不一致的结果,只保留跨模型预测一致的区域的注释作为高置信度的伪GT。
1.2、合成数据
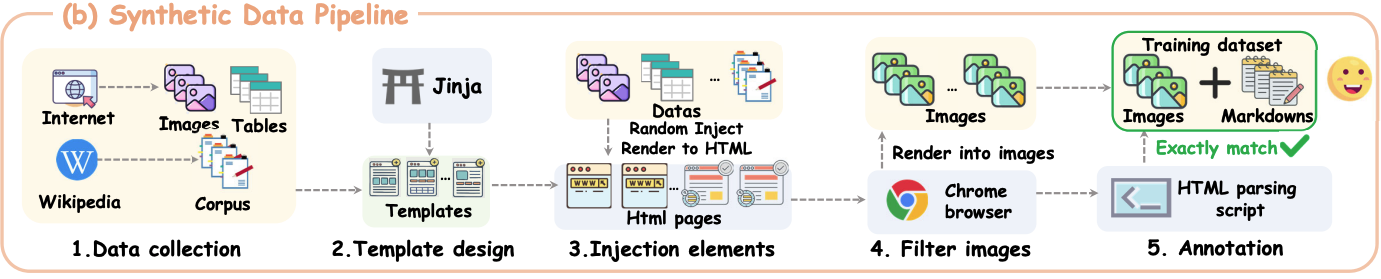
合成数据构建管道通过将采样内容注入预定义的单列、双列或三列HTML布局中,使用Jinja模板从维基百科、网络爬虫和在线语料库中收集文本和图像。这些页面使用浏览器引擎渲染成扫描文档,随后自动过滤掉低质量或重叠的图像。通过解析原始HTML生成对齐的Markdown表示作为真实注释。
2、采用布局感知的强化学习
布局感知的强化学习框架(layoutRL),通过优化多方面的奖励函数来训练模型,使其能够更好地理解和解析文档的布局结构。使用GRPO方法,通过从基于规则的奖励信号中学习训练架构如下:
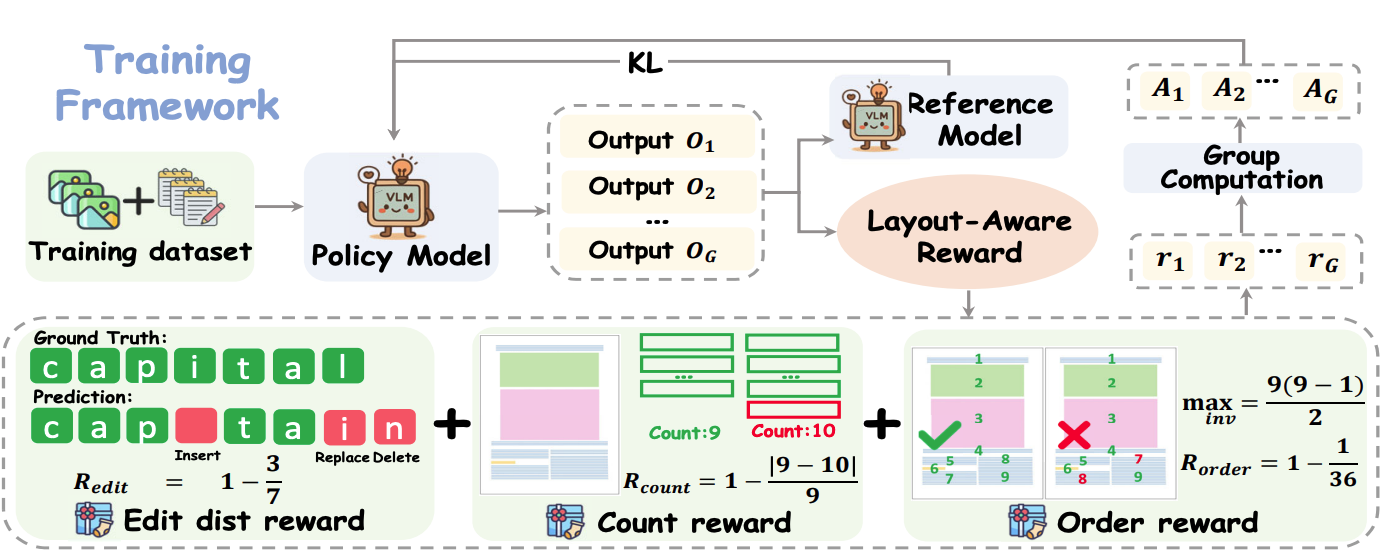
那么这一部分的核心就是奖励函数的设计了。主要分三部分:
2.1、编辑距离奖励
编辑距离奖励基于预测输出与参考输出之间的归一化Levenshtein距离。该奖励通过计算将预测输出转换为参考输出所需的最小插入、删除或替换操作的数量来衡量预测的准确性。
R d i s t = 1 − D ( y , y ^ ) max ( N , M ) R_{dist}=1-\frac{D(y,\hat{y})}{\max(N,M)} Rdist=1−max(N,M)D(y,y^)
其中, N N N 和 M M M 分别是参考和预测序列的长度, D ( y , y ^ ) D(y,\hat{y}) D(y,y^) 是Levenshtein距离。该奖励的范围在[0,1]之间,值越高表示预测与参考的对齐程度越好。
2.2、段落计数奖励
目的是鼓励模型准确地分割段落。该奖励通过比较预测段落数量与参考段落数量的差异来计算:
R c o u n t = 1 − ∣ N Y − N Y ^ ∣ N Y R_{count}=1-\frac{\left|N_{Y}-N_{\hat{Y}}\right|}{N_{Y}} Rcount=1−NY NY−NY^
其中, N Y N_Y NY 和 N Y ^ N_{\hat{Y}} NY^ 分别是参考和预测的段落数量。该奖励惩罚缺失或多余的段落。
2.3、顺序奖励
通过计算预测段落与参考段落之间的顺序反转次数来衡量阅读顺序的保真度。公式如下:
R o r d e r = 1 − D o r d e r max i n v R_{order}=1-\frac{D_{order}}{\max_{inv}} Rorder=1−maxinvDorder
其中, D o r d e r D_{order} Dorder 是顺序反转次数, max i n v \max_{inv} maxinv 是最大可能的反转次数。该奖励鼓励模型保持原始的阅读顺序。
- 最终奖励计算
最终的奖励是上述三个部分的加权和,通过匈牙利算法确定预测与参考段落之间的最佳匹配,然后计算每个匹配对的编辑相似性、段落数量和顺序保真度。公式如下:
R M u l t i − A s p e c t = R d i s t + R c o u n t + R o r d e r R_{Multi-Aspect}=R_{dist}+R_{count}+R_{order} RMulti−Aspect=Rdist+Rcount+Rorder
该设计平衡了内容保真度与结构正确性和顺序保真度,为端到端的文档解析提供监督。
实验评估
-
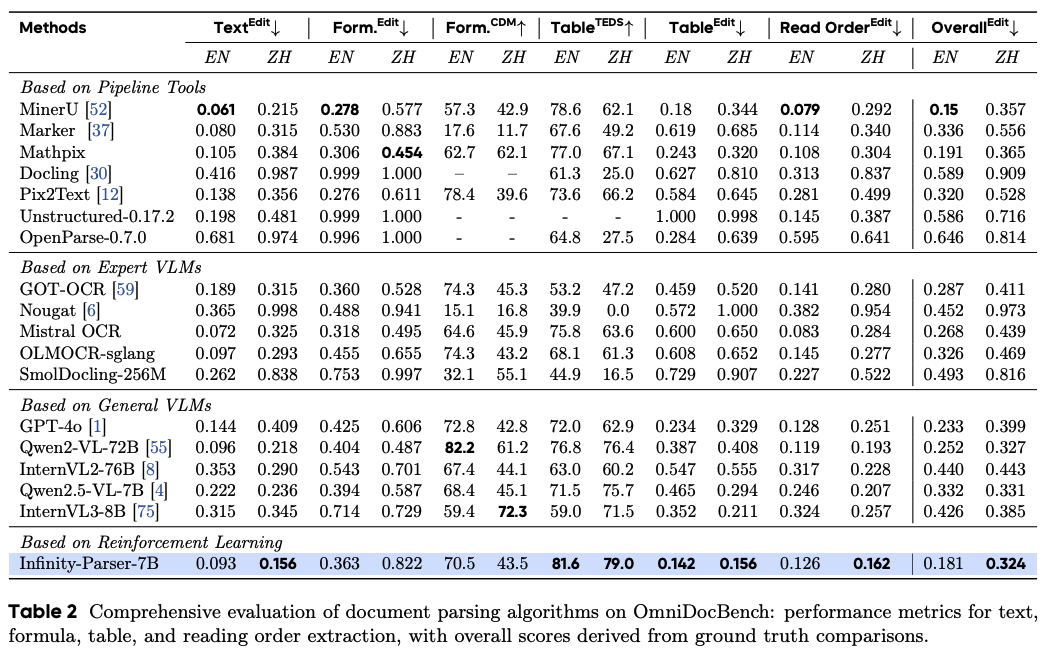
OmniDocBench评估:在OmniDocBench基准上,Infinity-Parser-7B在所有子任务中表现均衡
-
表格识别评估
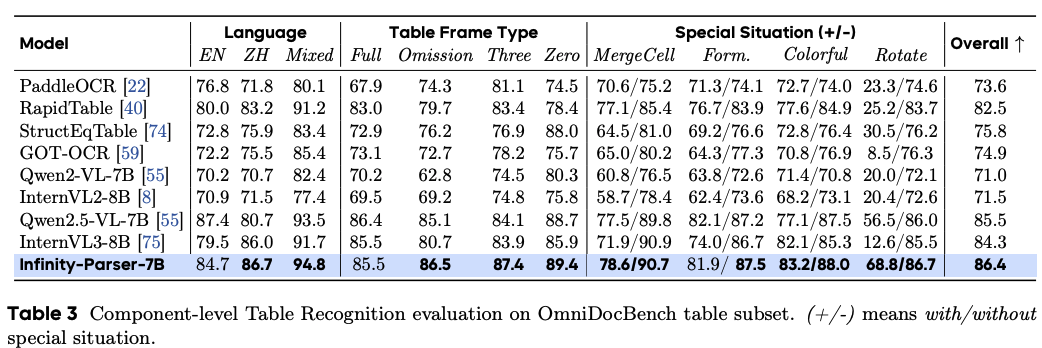
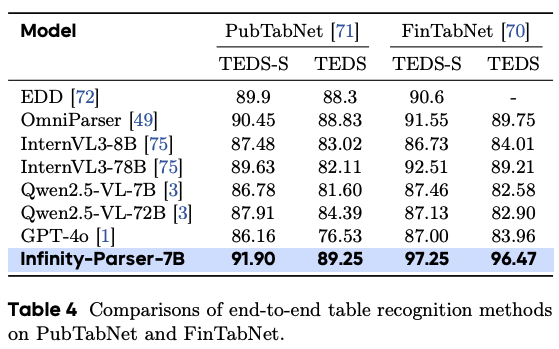
-
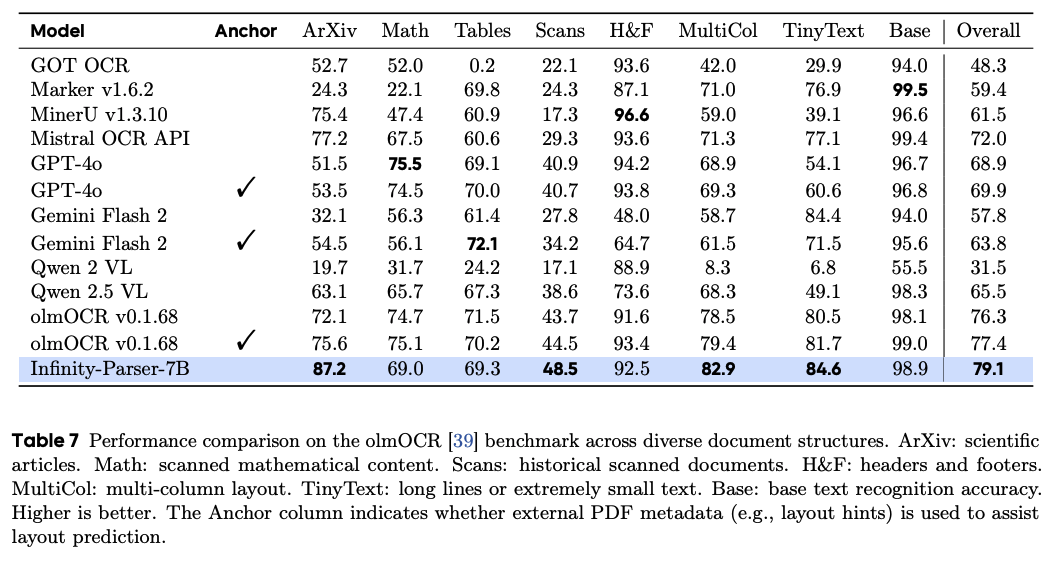
文档级OCR评估
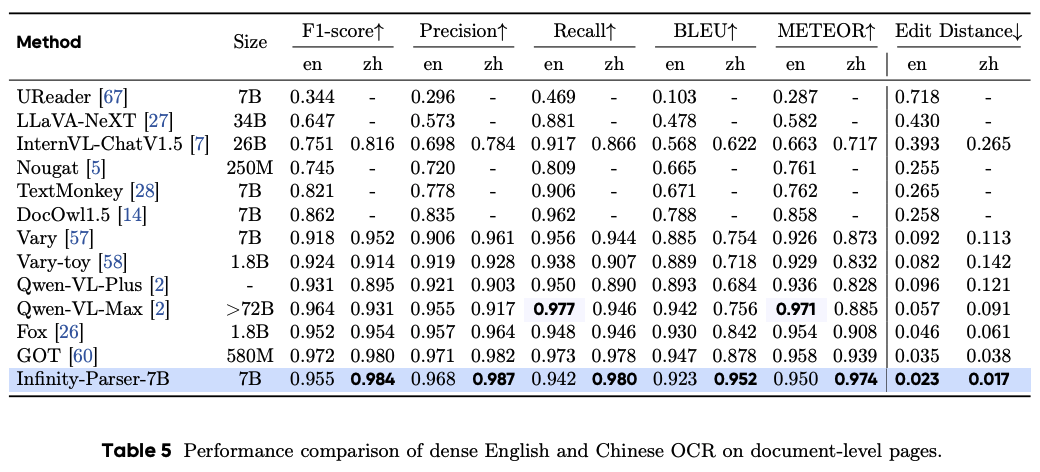
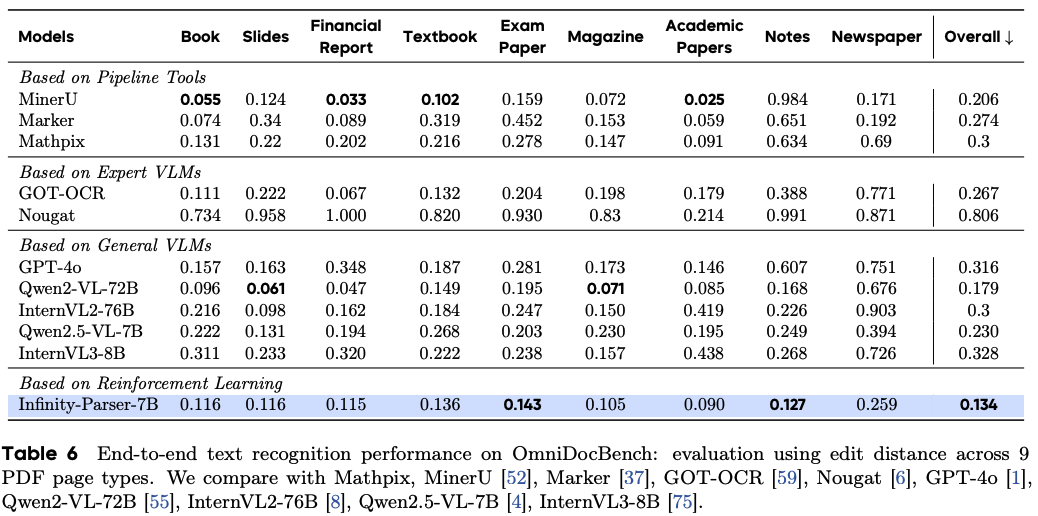

参考文献:Infinity-Parser: Layout-Aware Reinforcement Learning
for Scanned Document Parsing,https://arxiv.org/pdf/2506.03197
repo:https://github.com/infly-ai/INF-MLLM/tree/main/Infinity-Parser