建设多语言网站整站快速排名
目录
HQL语法优化之任务并行度
优化说明
Map端并行度
Reduce端并行度
优化案例
HQL语法优化之任务并行度
优化说明
对于分布式计算任务来说,设置一个合理的并行度至关重要。Hive的计算任务依赖于MapReduce框架来完成,因此并行度的调整需要从Map端和Reduce端两方面考虑。
Map端并行度
Map端的并行度指的是Map任务的数量,这通常是由输入文件的切片数决定的。在大多数情况下,Map端的并行度无需手动调整。但在以下特殊情况下,可以考虑调整Map端并行度:
-
查询的表中存在大量小文件 按照Hadoop默认的切片策略,每个小文件会被分配给一个独立的map task进行处理。如果查询的表包含大量的小文件,则会导致启动大量的map task,造成计算资源的浪费。为了解决这个问题,可以使用Hive提供的CombineHiveInputFormat,将多个小文件合并成一个切片,从而减少map task的数量。相关参数如下:
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -
Map端有复杂的查询逻辑 如果SQL语句中包含了复杂的查询逻辑,如正则替换、JSON解析等,那么Map端的计算可能会相对较慢。在这种情况下,如果计算资源充足,可以考虑增加Map端的并行度,使每个map task处理的数据量减少,以加快计算速度。相关参数如下:
-- 一个切片的最大值 set mapreduce.input.fileinputformat.split.maxsize=256000000;
Reduce端并行度
Reduce端的并行度是指Reduce任务的数量。与Map端相比,Reduce端的并行度更为关键。Reduce端的并行度可以由用户指定,也可以由Hive根据输入文件的大小自动估算。Reduce端并行度的相关参数如下:
set mapreduce.job.reduces;(指定Reduce端并行度,默认值为-1,表示用户未指定)set hive.exec.reducers.max;(Reduce端并行度最大值)set hive.exec.reducers.bytes.per.reducer;(单个Reduce Task计算的数据量,用于估算Reduce并行度)
Reduce端并行度的确定逻辑如下:
如果指定了参数mapreduce.job.reduces的值为一个非负整数,则Reduce并行度为该指定值。否则,Hive将自行估算Reduce并行度,估算逻辑如下:
假设Job输入的文件大小为totalInputBytes, 参数hive.exec.reducers.bytes.per.reducer的值为bytesPerReducer, 参数hive.exec.reducers.max的值为maxReducers,
则Reduce端的并行度为:
Reduce并行度=min(⌈totalInputBytesbytesPerReducer⌉,maxReducers)Reduce并行度=min(⌈bytesPerReducertotalInputBytes⌉,maxReducers)
由于Hive自行估算Reduce并行度时,是基于整个MR Job输入文件大小的,因此在某些情况下,其估计的并行度可能并不准确。此时,用户需要根据实际情况来指定Reduce并行度。
优化案例
示例SQL语句
hive (default)> select province_id, count(*) from order_detail group by province_id;优化前 上述SQL语句在不指定Reduce并行度时,Hive自行估算并行度的逻辑如下:
假设totalInputBytes = 1136009934, bytesPerReducer = 256000000, maxReducers = 1009,
经计算,Reduce并行度为:
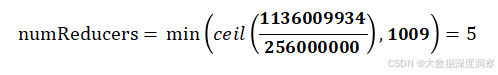
优化思路 上述SQL语句在默认情况下,会进行map-side聚合,即Reduce端接收到的数据已经是Map端聚合后的结果。观察任务执行过程会发现,每个Map端输出的数据只有34条记录,共有5个map task。
这意味着Reduce端实际上只会接收170(34 * 5)条记录。因此理论上Reduce端并行度设置为1就足够了。在这种情况下,用户可以通过以下参数自行设置Reduce端并行度为1:
-- 指定Reduce端并行度,默认值为-1,表示用户未指定
set mapreduce.job.reduces=1;