马鞍山网站开发流程下拉框关键词软件
关键词:语音修复、自监督模型、语音合成、语音增强、神经声码器
语音和/或音频修复的目标是增强局部受损的语音和/或音频信号。早期的工作基于信号处理技术,例如线性预测编码、正弦波建模或图模型。最近,语音/音频修复开始使用深度神经网络(DNNs),主要是全监督学习和编解码器架构,编码器输入为掩蔽的信号,解码器生成缺失部分的估计。
我们探讨使用语音SSL模型进行语音修复的情况,即从其周围环境中重建语音信号的缺失部分,也就是完成一个与预文本任务非常相似的下游任务。为此,我们将SSL编码器(即HuBERT)与神经声码器(即HiFiGAN)结合起来,后者扮演解码器的角色。特别地,我们提出了两种解决方案来匹配HuBERT的输出与HiFiGAN的输入,通过冻结一个并微调另一个,反之亦然。
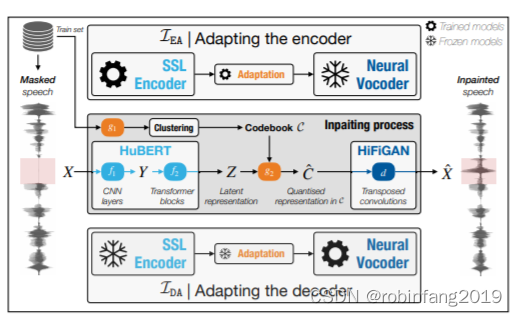
-
1、使用 HuBERT 和 HiFiGAN 进行语音修复的两种方法
使用 HuBERT 和 HiFiGAN 进行语音修复的两种方法:解码器适配 (IDA) 和编码器适配 (EA)。两种方法的主要区别在于谁被冻结谁被微调。
1.1 解码器适配 (IDA)
- HuBERT 模型被冻结: 使用预训练的 HuBERT 模型进行特征提取,不进行任何微调。
- HiFiGAN 模型被微调: 根据 HuBERT 的输出特征对 HiFiGAN 进行微调,使其能够根据 HuBERT 的特征生成语音波形。
1.2 编码器适配 (EA)
- HuBERT 模型被微调: 对 HuBERT 模型进行微调,使其能够直接预测掩码部分的梅尔谱图。
- HiFiGAN 模型被冻结: 使用预训练的 HiFiGAN 模型,根据 HuBERT 预测的梅尔谱图生成语音波形。
2、实验设置
2.1 实施细节
2.1.1 SSL 编码器 HuBERT
使用 Hugging Face 提供的预训练模型 hubert-large-ls960-ft,该模型基于 LibriSpeech 数据集进行微调。
语音输入采样率为 16 kHz,prenet 窗口大小和步长分别为 8960 和 320 个样本,输出维度为 768。
2.1.2 解码器适配 (IDA)
使用 Polyak 等人提出的 speech encoder-decoder 框架,并进行两步适配过程:
- 使用 HuBERT 的输出 Z 作为新的信号表示,并使用 k-means 算法构建代码本。
- 从头训练一个适配的 HiFiGAN 解码器,输入为代码本中向量 ˆcL 的索引。
2.1.3 编码器适配 (EA)
使用 HiFiGAN 的 Mel-spectrogram 作为输入,并冻结其模型。
重新引入 g1 和 g2 模块,并将 HuBERT 的输出适应到 Mel-spectrogram 表示。
使用 k-means 算法构建 Mel-spectrogram 的代码本,并训练 g2 模块来预测量化后的 Mel-spectrogram。
对 f2 模块进行微调,并对 g2 模块从头训练。
2.2 基线
作为基线,我们实现了一个基于线性插值的简单修复方法(ILI)。对于给定的掩蔽信号,它包括计算其Mel频谱图(如第三节所述),并用掩蔽区域前后的最后一个框架和第一个框架之间的线性插值替换掩蔽框架。然后,将插值的Mel频谱图输入到预训练的HiFiGAN声码器以生成22.05 kHz的波形,然后将其下采样到16 kHz。
2.3 评估指标
客观指标
- PESQ (Perceptual Evaluation of Speech Quality): 评估语音质量。
- STOI (Short-Time Objective Intelligibility): 评估语音可懂度。
- CER (Character Error Rate): 评估语音识别准确率。
主观评估:
MUSHRA 测试: 使用 Web Audio Evaluation Tool 进行在线 MUSHRA 测试,评估语音修复质量。
2.4 结果
- 定性分析: IEA 和 IDA 框架在修复质量上均优于 ILI 基准。
- 单说话人情况: IEA 框架在所有指标上均优于 IDA 框架。
- 多说话人情况: IDA 框架在所有指标上均优于 IEA 框架。
- 盲修复: 所有指标均低于知情修复,但趋势相似。
- 与其他研究比较: IEA 和 IDA 框架在知情修复情况下优于其他基于监督学习的方法,尤其是在长掩码情况下。
2.5 数据集
LJ Speech: 一个公共领域的语音数据集,包含13100个短音频剪辑。这些剪辑由单一发言者阅读7本非小说类书籍的段落,每个剪辑都提供了转录。剪辑的长度从1秒到10秒不等,总长度大约为24小时。
下载地址:The LJ Speech Dataset
VCTK: 一个广泛使用的语音数据集,主要用于语音识别、语音合成和语音克隆等领域。该数据集包含110名英语发音者的语音数据,每位发言者大约读出400句句子,这些句子选自报纸、彩虹段落和用于演讲口音存档的一段文字。
下载地址:https://datashare.ed.ac.uk/handle/10283/1942