常州做网站公司哪家好安徽网站设计
postgresql 的递归查询功能很强大,可以实现传统 sql 无法实现的事情。那递归查询的执行逻辑是什么呢?在递归查询中,我们一般会用到 union 或者 union all,他们两者之间的区别是什么呢?
递归查询的执行逻辑
递归查询的基本语法如下
WITH RECURSIVE ctename AS (SELECT /* non-recursive branch, cannot reference "ctename" */UNION [ALL]SELECT /* recursive branch referencing "ctename" */
)
SELECT ...
FROM ctename ...其本身也是一个CTE,可以将复杂的查询逻辑进行分离,让整个查询的逻辑更加清晰。对于递归查询而言,分为两部分:
- 非递归部分。即例子中的 UNION [ALL] 的上半部分
- 递归部分。即例子中的 UNION [ALL] 的下半部分
递归查询的逻辑如下:
- 计算非递归部分,其结果将作为递归查询的数据集,也是初始数据集
- 在第一步计算出来的数据上,执行递归部分,新查询出的数据将作为下次递归执行的数据集。也就是说,每次递归使用的数据集都是上次递归的结果
- 直到没有新的数据产生后,递归结束
- 将每一次递归的数据进行聚合,就拿到了最终的数据集
UNION 和 UNION ALL
- UNION: 会将本次递归查询到的数据进行内部去重,也会和之前递归查询出的数据进行去重
- UNION ALL: 不会对数据进行去重
举个例子
// 创建表
create table document_directories
(id bigserial not null,name text not null,created_at timestamp with time zone default CURRENT_TIMESTAMP not null,updated_at timestamp with time zone default CURRENT_TIMESTAMP not null,parent_id bigint default 0 not null
);// 插入示例数据,有两条数据是一样的
INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (1, '中国', '2020-03-28 15:55:27.137439', '2020-03-28 15:55:27.137439', 0);
INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (2, '上海', '2020-03-28 15:55:40.894773', '2020-03-28 15:55:40.894773', 1);
INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (3, '北京', '2020-03-28 15:55:53.631493', '2020-03-28 15:55:53.631493', 1);
INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (4, '南京', '2020-03-28 15:56:05.496985', '2020-03-28 15:56:05.496985', 1);
INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (5, '浦东新区', '2020-03-28 15:56:24.824672', '2020-03-28 15:56:24.824672', 2);
INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (6, '徐汇区', '2020-03-28 15:56:39.664924', '2020-03-28 15:56:39.664924', 2);
INSERT INTO public.document_directories (id, name, created_at, updated_at, parent_id) VALUES (6, '徐汇区', '2020-03-28 15:56:39.664924', '2020-03-28 15:56:39.664924', 2);使用 UNION ALL 进行数据查询
with recursive sub_shanghai as (select id, name, parent_idfrom document_directorieswhere id=2union allselect dd.id, dd.name, dd.parent_idfrom document_directories ddjoin sub_shanghai on dd.parent_id=sub_shanghai.id)select * from sub_shanghai;结果如下
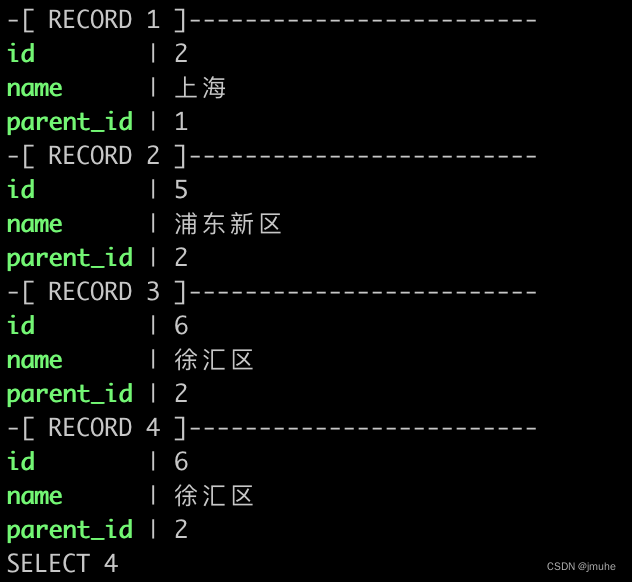
使用 UNION 进行查询
with recursive sub_shanghai as (select id, name, parent_idfrom document_directorieswhere id=2unionselect dd.id, dd.name, dd.parent_idfrom document_directories ddjoin sub_shanghai on dd.parent_id=sub_shanghai.id)select * from sub_shanghai;得到结果如下

我们修改下原始数据,再看下去重逻辑的区别
update document_directories set parent_id = 2 where id=2;当我们使用 UNION 进行递归查询时,结果并没有发生变化。但是当我们使用 UNION ALL 进行查询时,会一直执行。这是因为 UNION ALL 不会将数据进行去重,而每次递归查询的时候,总归能查询到 {"id": 5, name:"上海", "parent_id": 2} 这条数据,所以递归就没有终止条件。
从而也验证了,UNION 不但会将本次递归查询的数据进行内部去重,也会和之前的递归结果进行去重。