货代找客户的网站淘宝关键词查询工具哪个好
以下记录自己对transformer的学习笔记,可能自己看得懂【久了自己也忘了看不懂】,别人看起来有点乱。以后再优化文档~
小伙伴请直接去看学习资源:
Transformer的理解T-1_哔哩哔哩_bilibili
-
首先,时序处理:一些模型的出现。
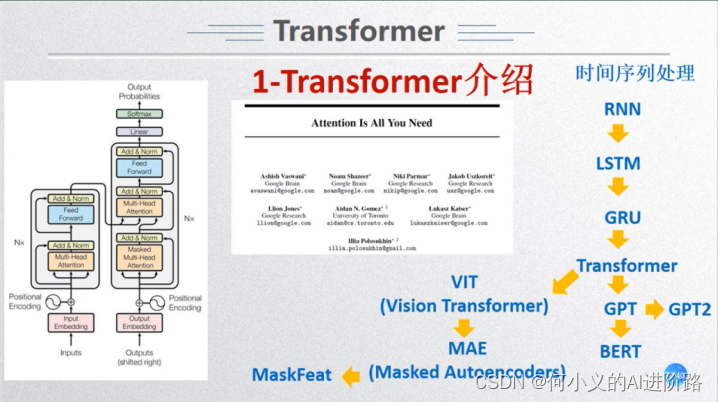
NLP方面继续:
GPT2 -> GPT3 -> GPT4, chatGPT
图像方面:
分类:VIT , Swin Transformer, TNT(TRM in TRM)
检测:DERT等基于trm的目标检测模型;
分割:VisTR等基于trm的图像分割模型(A Survey of Visual Transformers)
预训练模型进阶【大一统,CV大模型初步】:MAE -> SAM(segment anything)
- Transformer
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30. ( 谷歌 NIPS 2017)
Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行。并且Transformer可以增加到非常深的深度,充分发掘DNN模型的特性,但是模型本身很简洁,提升模型准确率。

- Inputs:比如一句话,四个词语!
- Input Embedding: 四个词语,每个embedding成512维! X:4*512 [x1,x2,x3,x4] 分别:1*512
- Positional Encoding: 位置编码 【一句话中每个词之间有一种相对位置,同一个词不同位置,让每一个位置都有不同的编码,才更有意义 最终用:Final Embedding.】


pos:第几个位置,i:第几个编码维度,d-model:同embedding一致的总维度,如512
奇数维度sin,偶数维度cos 【公式:第几个位置的第几维度,得到一个position值】

纵坐标:位置, 横坐标:维度
对于Multi-Head Attention:


Q(query),K(key),V(value): 每一个词语的每一个q k v都是1*512 来源:
q1 = x1*Wq = [1 512] * [512 512] = [1 512] k1和v1同理!【第2-4个词同理】
QKT = [4 512]*[512 4] = [4 4] 根号dk为常熟,负责缩减值。
*V = [4 4] * [4*512] = [4 512] 因此,最终self-attation值还是4*512 = X:4*512


值得一提的是当有多个句子,每个句子有不同的数量的词语,计算中矩阵需要进行补充掩码!
比如5个有的只有3个。不够的全都掩码到5个!

有的是Q-padding, 有的是K-padding 【常用】 三个句子3个词4个词5个词最终都是5*512!
对于多头注意力的体现?
假如Q K V 4*512 分层成4*256与 4*256 【图中是三份,这里两份】
每个4*256分别计算自己的四个样本词的自注意力,最后它们再concat合并起来!


对于:Masked Multi-head attention
不同于encoder中,对输入数据X的自注意力计算,decoder中是需要逐个预测output的输出的,因此第一次保留第一个词语开始符<sos>,掩盖住后面的,第二次保留前两个词语,掩盖住后边的,知道最后得到结束符<eos>,预测结束。

这里的mask方式是对V构造上三角掩盖:
补充句子长度一致q-padding或者k-padding,掩掉句子长度
这里decoder是每次预测结果掩盖后边句子,是把QKT掩盖构造的上三角矩阵,再乘V!

对于结构中剩余模块:多头注意力后的短接,归一化,前馈神经网络,最后线性层+softmax等等。最终输出Output Probability比如:4*C的矩阵,C是类别数量。
Visual Transformer
Dosovitskiy A , Beyer L , Kolesnikov A ,et al.An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale[C]//International Conference on Learning Representations.2021. (谷歌)
问题:transformer 从NLP到 CV???


复杂度高,且每个像素值作为一个token并不合理!!!
>>> 思路:
图片分块固定大小,线性嵌入特征+位置编码特征,喂给TRM的encoder~
增加可扩展的分类token


优点:有局部,合起来也有全局!
vit中TRM与TRM原论文有点结构上的变化:norm提前了,而且没有PAD掩码【猜测是样本图resize统一,分割出来的token是一样的】
具体的如下步骤:


一些VIT的细节解释:
首先,输出特征怎么利用:
一般可以两种⽅式,⼀种是使⽤【CLS】token,另⼀种就是对所有tokens的输出做⼀个平均
最后选择加一个分类用的token-0:因为计算中也会和每一个算自注意力【不用每个token的高阶encoder输出再合并特征接全连接层了,用token0的也行,隐藏着特征带有全图全局信息了的了】

一些计算过程:

P:图片块分辨率,H*W/P*P = N数量,图分成了N块 【要看论文,一开始博主讲的P2块】
C:每块图通道,比如3,
D:维度,比如 512 【代码中:一块图P*P*3->conv+fc->D维embedding】
E:输入特征【N*D】比如 N=9块,这里9*512 Epos:位置编码特征,维度保持一致D!【这里是10*512】
Z0:VIT里边的patch+position的综合embedding了【加Xclass的token-0】
MSA:多头注意力,LN:norm 加后边的Zl-1:残差机制
MLP一行同理1 以上在图中也可以loop循环堆叠。