wap手机网站制作平台怎样推广
平台:window10,python3.11.4,pycharm
框架:keras
编写日期:20230903
数据集:英语,自编,训练集和测试集分别有4个样本,标签有积极和消极两种
环境搭建
新建文件夹,进入目录
创建虚拟环境
virtualenv venv激活虚拟环境
venv\Scripts\activate安装依赖库
pip install tensorflow代码编写
目录下创建main.py,进入pycharm打开文件夹,编写代码
包引入
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import SimpleRNN, Dense数据集处理
# 训练集
train_texts = ['I love this movie','This is the worst film I have ever seen.','An enjoyable and thought-provoking experience.',"I think it is boring"]train_labels = np.array([1, 0, 1, 0]) # 0代表消极,1代表积极# 测试集
test_texts = ["What a waste of my time","One of the best movies I've seen in a long time","Amazing acting!","This movie look awful"]
test_labels = np.array([0, 1, 1, 0])# 构建分词器
tokenizer = Tokenizer(num_words=100)
# 用训练集与测试集训练分词器
tokenizer.fit_on_texts(train_texts + test_texts)
# 数据集序列化,将文本转成数字,便于机器处理
train_sequences = tokenizer.texts_to_sequences(train_texts)
test_sequences = tokenizer.texts_to_sequences(test_texts)
# 数据填充到20,超过的就截断,post:在末尾填充
# 由于每个训练文本有不同的单词数,需要统一
train_data = pad_sequences(train_sequences, maxlen=20, padding='post')
test_data = pad_sequences(test_sequences, maxlen=20, padding='post')模型搭建和训练
# 创建一个线性模型容器
model = Sequential()
#添加RNN层,神经元数量为100,输入数据形状为(20,1)
model.add(SimpleRNN(100, input_shape=(20, 1)))
# 添加1个输出,激活函数为sigmoid的全连接层
model.add(Dense(1, activation='sigmoid'))
# 优化器:Adam,损失计算方法:二元交叉熵,评估依据:准确率
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 输出模型结构
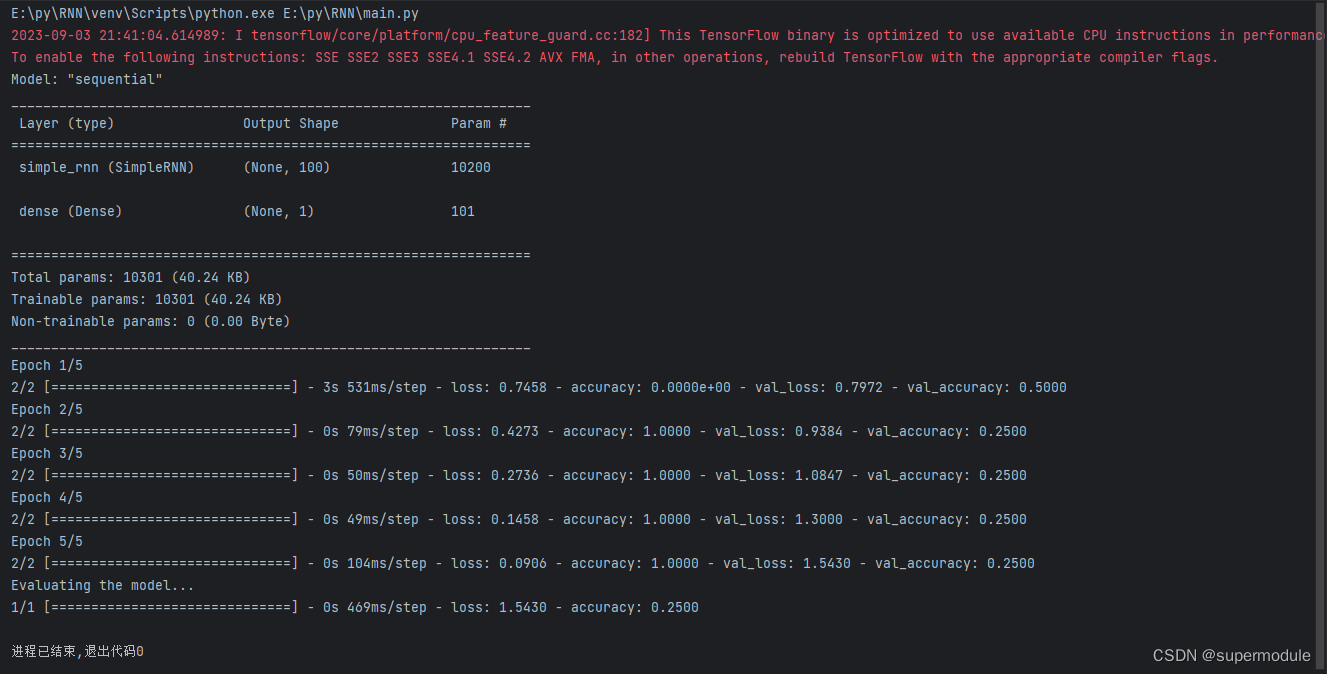
model.summary()
#训练模型,训练5轮,每次训练2个样本
model.fit(train_data, train_labels, epochs=5, batch_size=2, validation_data=(test_data, test_labels))
模型评估
# 打印评估信息
print('Evaluating the model...')
#进行评估
model.evaluate(test_data, test_labels)所有代码集合
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import SimpleRNN, Densetrain_texts = ['I love this movie','This is the worst film I have ever seen.','An enjoyable and thought-provoking experience.',"I think it is boring"]
train_labels = np.array([1, 0, 1, 0])test_texts = ["What a waste of my time","One of the best movies I've seen in a long time","Amazing acting!","This movie look awful"]
test_labels = np.array([0, 1, 1, 0])tokenizer = Tokenizer(num_words=1000)
tokenizer.fit_on_texts(train_texts + test_texts)train_sequences = tokenizer.texts_to_sequences(train_texts)
test_sequences = tokenizer.texts_to_sequences(test_texts)train_data = pad_sequences(train_sequences, maxlen=20, padding='post')
test_data = pad_sequences(test_sequences, maxlen=20, padding='post')model = Sequential()
model.add(SimpleRNN(100, input_shape=(20, 1)))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()model.fit(train_data, train_labels, epochs=5, batch_size=2, validation_data=(test_data, test_labels))print('Evaluating the model...')
model.evaluate(test_data, test_labels)
运行图片截取
文件目录
控制台