网站域名价格百度注册页面
1.1 子集I

思路可以简单概括为 二叉树,每一次分叉要么选择一个元素,要么选择空,总共有n次,因此到n+1进行保存结果,返回。像这样:

#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
int n;
vector<int >temp;
vector<vector<int> > result;
void DFS(int m){if (m == n+1){result.push_back(temp);return ;}//选择元素mtemp.push_back(m);DFS(m+1);//继续递归temp.pop_back();//返回//选择空DFS(m+1);
}bool cmp(vector<int > &a,vector<int > &b){if (a.size()!=b.size())return a.size()<b.size();return a<b;
}
int main(){scanf("%d",&n);DFS(1);sort(result.begin(),result.end(),cmp);for (int i=0;i<result.size();i++){for (int j=0;j<result[i].size();j++){if (j==result[i].size()-1)printf("%d",result[i][j]);else printf("%d ",result[i][j]);}printf("\n");}return 0;
}最后自己编写比较函数,简单来说,vector大小相同时,可以直接按照< >这些比较符号进行比较。大小不同时,则按照vector大小进行排序,这里按照题目要求均是小于。
1.2 子集II

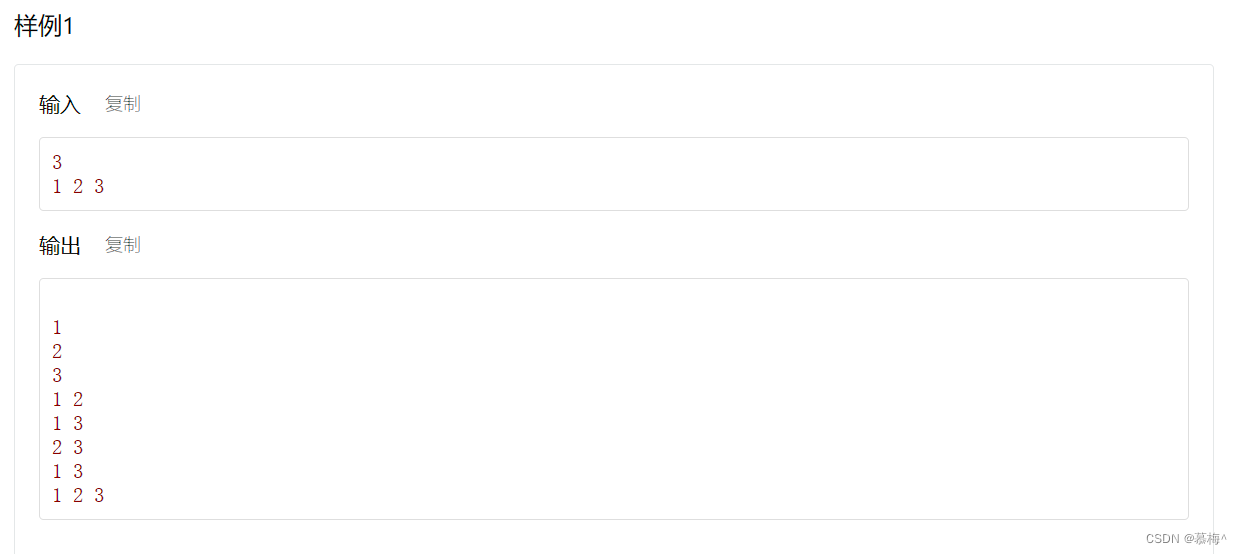

区别在于,自己给定一些元素,进行排序。
那么只需要用一个数组存储这些元素,在压栈/出栈时,换成对应的数组元素即可,思路一致。
代码几乎没有变化。
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
vector<int> temp;
vector<vector<int> > result;
const int N =15;
int q[N];
int n;
void DFS(int m){if (m==n+1){result.push_back(temp);return ;}temp.push_back(q[m]);DFS(m+1);temp.pop_back();DFS(m+1);
}
bool cmp(vector<int> &a ,vector<int> &b){if (a.size()!= b.size())return a.size()<b.size();return a<b;
}
int main(){scanf("%d",&n);for (int i=1;i<=n;i++)scanf("%d",&q[i]);DFS(1);sort(result.begin(),result.end(),cmp);for (int i=0;i<result.size();i++){for (int j=0;j<result[i].size();j++){if (j==result[i].size()-1)printf("%d",result[i][j]);else printf("%d ",result[i][j]);}printf("\n");}return 0;}1.3 子集III


思路还是二叉树深搜递归,但是由于会出现重复的数,按照之前的输出会重复输出一些值,例如样例里的1的子集都会输出两边,因为代码并没有认为第一个1与第二个1是不同的。
首先输入的序列是升序的,因此我们可以连续地处理这些重复的元素。
例如 2 3 3 3 5
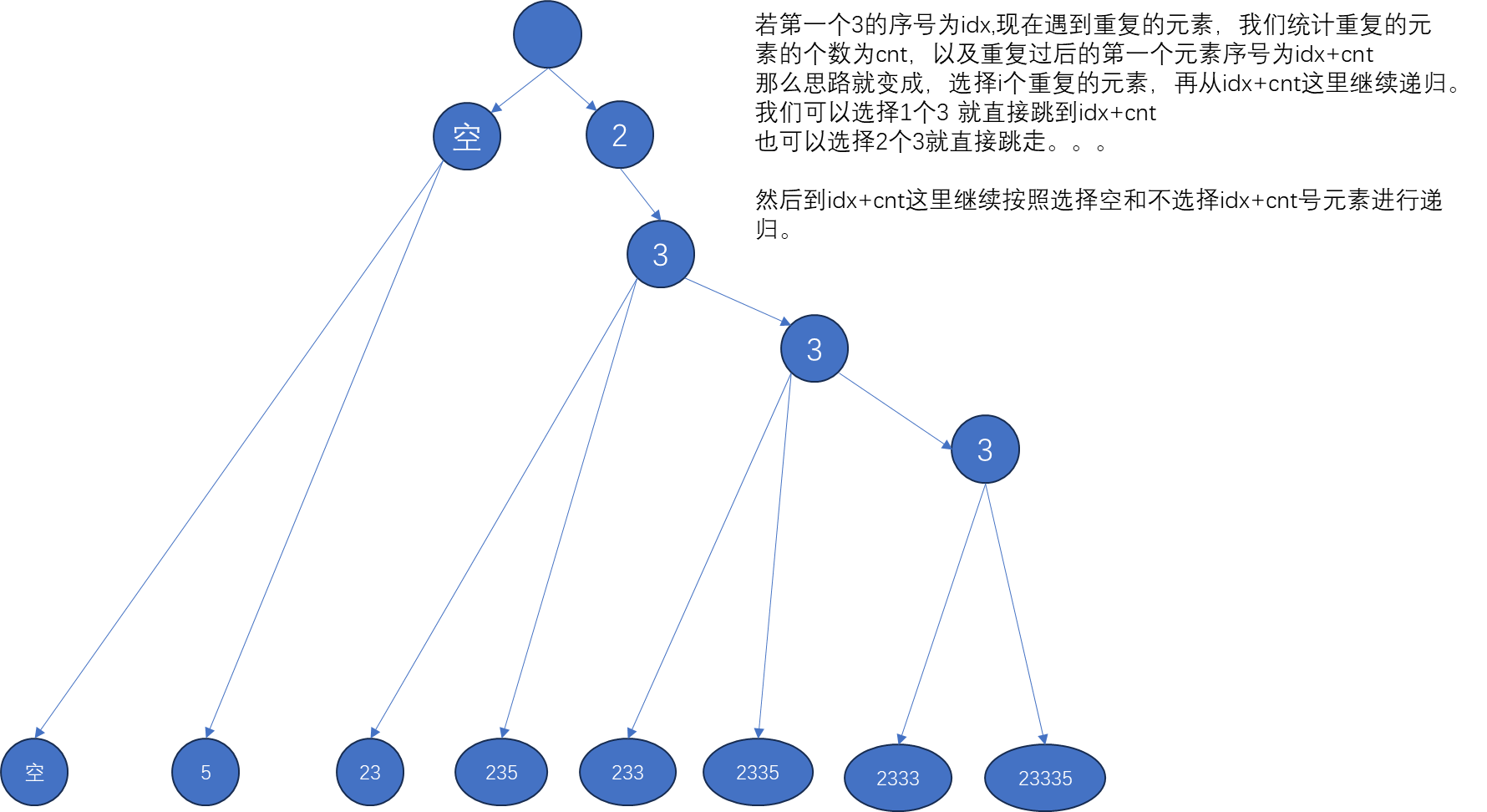
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
vector<int> temp;
vector<vector<int> > result;
const int N =15;
int q[N];
int n;
void DFS(int idx){if (idx==n+1){result.push_back(temp);return ;}int cnt=1;while (idx<n && q[idx]==q[idx+1]){cnt++;idx++;}//经过该循环,idx = 最后一个重复元素的序号,cnt为重复元素的个数// 选择空 DFS(idx+1);//选择重复元素for (int i=1;i<=cnt;i++){temp.push_back(q[idx]);DFS(idx+1);// 选择重复的元素为 1 2 3 ....cnt个}//在这个循环中,我们将之前添加到 temp 中的元素逐个移除,//以回溯到不添加这些重复元素的情况for (int i=1;i<=cnt;i++){temp.pop_back();}
}
bool cmp(vector<int> &a ,vector<int> &b){if (a.size()!= b.size())return a.size()<b.size();return a<b;
}
int main(){scanf("%d",&n);for (int i=1;i<=n;i++)scanf("%d",&q[i]);DFS(1);sort(result.begin(),result.end(),cmp);for (int i=0;i<result.size();i++){for (int j=0;j<result[i].size();j++){if (j==result[i].size()-1)printf("%d",result[i][j]);else printf("%d ",result[i][j]);}printf("\n");}return 0;}2.1 全排列I

思路很简单,给个图:

设置个q[]表示其是否被使用过,依次递归,返回时再赋值0;
#include <cstdio>
#include <algorithm>
#include <vector>
using namespace std;
vector<int> temp;
vector<vector<int> > result;
int n;
const int N = 10;
int q[N]={0};
void DFS(int m){if (m == n+1){result.push_back(temp);}for (int i=1;i<=n;i++){if (!q[i]){temp.push_back(i);q[i]=1;DFS(m+1);q[i]=0;temp.pop_back();}}}
bool cmp(vector<int> &a ,vector<int> &b){if (a.size()!=a.size())return a.size()<b.size();return a<b;
}
int main(){scanf("%d",&n);DFS(1);sort(result.begin(),result.end(),cmp);for (int i=0;i<result.size();i++){for (int j=0;j<result[i].size();j++){if (j==result[i].size()-1)printf("%d",result[i][j]);else printf("%d ",result[i][j]);}printf("\n");}return 0;}2.2 全排列II
思路依旧简单,全排列I是用i作为正整数,这次是给定正整数压栈和出栈,q[]来储存输入的数,flag[]来表示其是否被使用过,代码相同
#include <cstdio>
#include <algorithm>
#include <vector>using namespace std;
int n;
const int N=10;
int q[N];
int flag[N] = {0};
vector<int> temp;
vector<vector<int> > result;
void DFS(int m){if (m==n+1){result.push_back(temp);}for (int i=1;i<=n;i++){if (!flag[i]){temp.push_back(q[i]);flag[i]=1;DFS(m+1);flag[i]=0;temp.pop_back();}}}
bool cmp(vector<int> &a,vector<int> &b){if (a.size()!=b.size())return a.size()<b.size();return a<b;
}
int main(){scanf("%d",&n);for (int i=1;i<=n;i++)scanf("%d",&q[i]);DFS(1);sort(result.begin(),result.end(),cmp);for (int i=0;i<result.size();i++){for (int j=0;j<result[i].size();j++){if (j==result[i].size()-1)printf("%d",result[i][j]);else printf("%d ",result[i][j]);}printf("\n");}return 0;}2.3 全排列III


如果按照之前的思路,那么样例1会出现大量重复,与子集的解决方法类似,不过是这里是记录每个数的个数,使用cnt[]进行计算,并且每个数只记录一次;
1 1 3 : 只取最后一个重复的id进行记录次数,像这样:cnt[1] = 0 cnt[2]=2 cnt[3] =1
那么全排列就很简单,每次的全排列对于q[i]的数只能用cnt[i]次数。
那么每次for循环
for (int i=1;i<=n;i++){if (cnt[i]){temp.push_back(q[i]);cnt[i]--;DFS(m+1);cnt[i]++;temp.pop_back();}}只能用一次重复的值
#include <cstdio>
#include <algorithm>
#include <vector>using namespace std;
int n;
const int N = 10;
int q[N];
int cnt[N]={0};
vector<int> temp;
vector<vector<int> >result;
void DFS(int m){if (m==n+1){result.push_back(temp);return ;}for (int i=1;i<=n;i++){if (cnt[i]){temp.push_back(q[i]);cnt[i]--;DFS(m+1);cnt[i]++;temp.pop_back();}}
}
bool cmp(vector<int> &a,vector<int> &b){if (a.size()!=b.size())return a.size()<b.size();return a<b;
}
int main(){scanf("%d",&n);for (int i=1;i<=n;i++)scanf("%d",&q[i]);for (int i=1;i<=n;i++){int j=i;cnt[i]=1;while (j<=n && q[j]==q[j+1]){cnt[i]++;j++;}i = j;}DFS(1);sort(result.begin(),result.end(),cmp);for (int i=0;i<result.size();i++){for (int j=0;j<result[i].size();j++){if (j==result[i].size()-1)printf("%d",result[i][j]);else printf("%d ",result[i][j]);}printf("\n");}return 0;}3.1 组合I

和全排列很像,不过全排列是有顺序的(样例中3 4 和4 3在全排列均是有效的),而组合是无序的,因此我们在挑选的时候可以人为地进行有序限制,从而不会重复。
思路与这道递归题类似
[递归] 自然数分解之方案数_慕梅^的博客-CSDN博客
我们保证后一个数要大于前一个这样的要求,那么就可实现组合题。
样例2中 两个数x y 满足(x<y)
那我们的DFS(int m),m则是后面的数需要大于的序号
DFS(0)可以作为入口
#include <cstdio>
#include <algorithm>
#include <vector>using namespace std;
int n,k;
const int N = 15;vector<int> temp;
vector<vector<int> > result;void DFS(int m){if (temp.size()==k){//递归的出口则改为vector <int> temp的大小==kresult.push_back(temp);return ;}for (int i=m+1;i<=n;i++){//循环从 序号m+1开始temp.push_back(i);DFS(i);//将i作为参数进行下一次的递归temp.pop_back();}return ;}
bool cmp(vector<int> &a,vector<int> &b){if (a.size()!=b.size())return a.size()<b.size();return a<b;
}
int main(){scanf("%d%d",&n,&k);DFS(0);sort(result.begin(),result.end(),cmp);for (int i=0;i<result.size();i++){for (int j=0;j<result[i].size();j++){if (j==result[i].size()-1)printf("%d",result[i][j]);else printf("%d ",result[i][j]);}printf("\n");}return 0;}
3.2 组合II
需要自己输入序列,思路不变

#include <cstdio>
#include <algorithm>
#include <vector>using namespace std;
int n,k;
const int N = 15;
int q[N];
vector<int> temp;
vector<vector<int> > result;void DFS(int m){if (temp.size()==k){result.push_back(temp);return ;}for (int i=m+1;i<=n;i++){temp.push_back(q[i]);DFS(i);temp.pop_back();}
}
bool cmp(vector<int> &a,vector<int> &b){if (a.size()!=b.size())return a.size()<b.size();return a<b;
}
int main(){scanf("%d%d",&n,&k);for (int i=1;i<=n;i++)scanf("%d",&q[i]);DFS(0);sort(result.begin(),result.end(),cmp);for (int i=0;i<result.size();i++){for (int j=0;j<result[i].size();j++){if (j==result[i].size()-1)printf("%d",result[i][j]);else printf("%d ",result[i][j]);}printf("\n");}return 0;}
3.3 组合III
可以借鉴全排列的思想,使用cnt来进行计数
#include <cstdio>
#include <algorithm>
#include <vector>using namespace std;
int n,k;
const int N = 15;
int q[N];
int cnt[N]={0};
vector<int> temp;
vector<vector<int> > result;void DFS(int m){if (temp.size()==k){result.push_back(temp);return ;}for (int i=m;i<=n;i++){//i从m开始,因为有重复的元素。if (cnt[i]){cnt[i]--;temp.push_back(q[i]);DFS(i);cnt[i]++;temp.pop_back();}}
}
bool cmp(vector<int> &a,vector<int> &b){if (a.size()!=b.size())return a.size()<b.size();return a<b;
}
int main(){scanf("%d%d",&n,&k);for (int i=1;i<=n;i++)scanf("%d",&q[i]);for (int i=1;i<=n;i++){int j = i;cnt[i] = 1;while ((j+1)<=n&&q[j]==q[j+1]){cnt[i]++;j++;}i = j;}DFS(0);sort(result.begin(),result.end(),cmp);for (int i=0;i<result.size();i++){for (int j=0;j<result[i].size();j++){if (j==result[i].size()-1)printf("%d",result[i][j]);else printf("%d ",result[i][j]);}printf("\n");}return 0;}
不过与前两个组合不同的是
for (int i=m+1;i<=n;i++){条件因改为
for (int i=m;i<=n;i++){如果不该与,之前的序列都是没有重复的元素,因此可以下一次的序号需要+1以保证大于前面的数,然而这里有重复的元素,因此从m开始。