怎么做网站推广wifi优化大师下载

☁️主页 Nowl
🔥专栏《机器学习实战》 《机器学习》
📑君子坐而论道,少年起而行之
文章目录
交叉验证
保留交叉验证
k-折交叉验证
留一交叉验证
混淆矩阵
精度与召回率
介绍
精度
召回率
区别
使用代码
偏差与方差
介绍
区别
交叉验证
保留交叉验证
介绍
将数据集划分为两部分,训练集与测试集,这也是简单任务中常用的方法,其实没有很好地体现交叉验证的思想
使用代码
# 导入库
from sklearn.model_selection import train_test_split# 划分训练集与测试集,参数分别为总数据集,测试集的比例
train, test = train_test_split(data, test_size=0.2)k-折交叉验证
介绍
将数据集划分为k个子集,每次采用k-1个子集作为训练集,剩下的一个作为测试集,然后再重新选择,使每一个子集都做一次测试集,所以整个过程总共训练k次,得到k组结果,最后将这k组结果取平均,得到最终结果,这就是交叉验证的思想

使用代码
# 导入库
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score# 设置K值,这里假设K=5
k_fold = KFold(n_splits=5, shuffle=True, random_state=42)# 初始化模型,这里以随机森林为例
model = RandomForestClassifier()# 使用K折交叉验证
scores = cross_val_score(model, X, y, cv=k_fold)留一交叉验证
介绍
与k折验证思想一致,只是子集的数量和数据集的大小一样,往往在数据集较小的时候使用这种方法
混淆矩阵
介绍
在分类任务中,我们可以用混淆矩阵来判断模型的性能,混淆矩阵记录了A类被分为B类的次数,以下是一个动物识别任务的混淆矩阵,要知道cat被预测成了几次dog,那么就查看混淆矩阵的第1行第2列

使用代码
# 导入库
from sklearn.metrics import confusion_matrix# 打印混淆矩阵,参数为真实结果与预测结果
print(confusion_matrix(y, y_pred))精度与召回率
介绍

要解释精度与召回率,我们先定义几个量
TP:模型预测为正且真实值为正的数量
FP:模型预测为正且真实值为负的数量
FN:模型预测为负且真实值为正的数量
精度
精度就是模型正确预测的正类在所有预测为正类中的比例
召回率
召回率就是模型正确预测的正类在所有正类中的比例
区别
可能还是有点混淆?其实精度高就是宁愿不预测,也不愿意预测错,召回率高就是宁愿预测错,也不愿意遗漏正类,我们具体来看两个场景
在地震预测中,我们是要提高召回率还是精度?显而易见,召回率,因为我们宁愿预测器错误地提醒我们,也不愿意当地震来临时它不报警
那么在食品检测中呢?当然要提高精度,因为我们宁愿健康的食品被误判为不合格,也不愿意有不合格的食品进入市场
召回率与精度两个指标不可兼得,我们要根据具体任务做出取舍
使用代码
# 导入库
from sklearn.metrics import precision_score, recall_score# 使用精度评估函数,参数是真实结果与预测结果
print(precision_score(y, y_pred))# 使用召回率评估函数,参数是真实结果与预测结果
print(recall_score(y, y_pred))偏差与方差
介绍
偏差衡量一个模型预测结果和真实值的差距,偏差高往往代表模型欠拟合
方差衡量模型在不同数据集上预测的差异,方差高往往代表模型过拟合
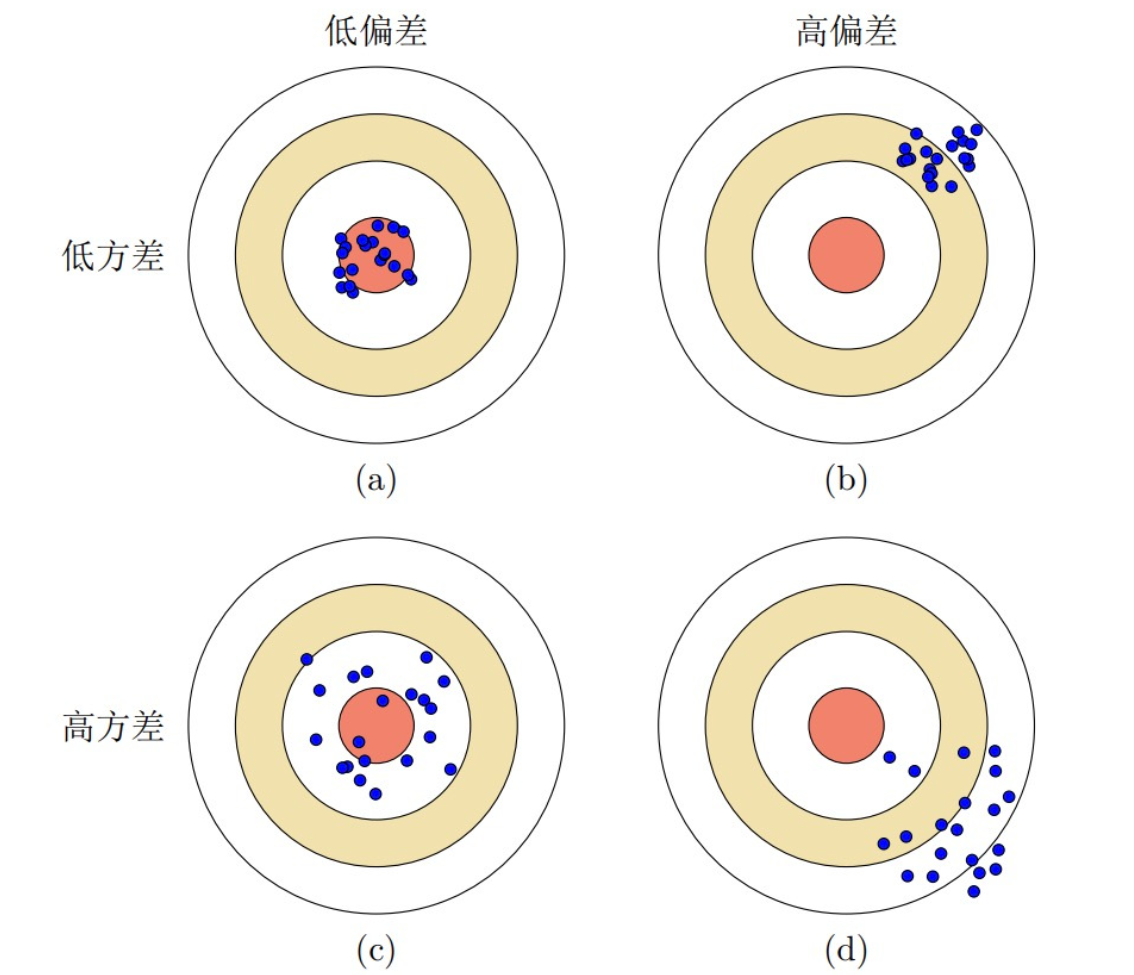
区别
具有高偏差的模型对训练数据和新数据的表现都较差,因为它们未能捕捉到数据的复杂性。
具有高方差的模型在训练数据上可能表现得很好,但对新数据的泛化能力差,因为它们过于依赖于训练数据的细节。
结语
机器学习模型性能测量对于评估模型的质量、选择最佳模型、调整模型超参数以及在实际应用中预测新数据都具有重要意义。
-
评估模型质量: 通过性能测量,你可以了解模型在训练数据上的表现如何。这有助于判断模型是否足够复杂以捕捉数据中的模式,同时又不过度拟合训练数据。
-
选择最佳模型: 在比较不同模型时,性能测量是选择最佳模型的关键因素。你可以通过比较模型在相同任务上的性能指标来确定哪个模型更适合你的问题。
-
调整模型超参数: 通过观察模型在不同超参数设置下的性能,你可以调整超参数以提高模型的性能。性能测量可以指导你在超参数搜索空间中寻找最佳设置。
-
评估泛化能力: 模型在训练数据上表现良好并不一定意味着它在新数据上也能表现良好。性能测量帮助你评估模型的泛化能力,即模型对未见过的数据的预测能力。
-
支持业务决策: 在实际应用中,模型的性能直接关系到业务的决策。例如,在医疗领域,一个精确的疾病预测模型可能影响患者的治疗计划。
-
改进模型: 通过分析性能测量的结果,你可以识别模型的弱点,并采取相应的措施来改进模型,例如增加训练数据、特征工程、选择更合适的模型等。
觉得有用的话就订阅下本专栏吧,感谢阅读