专注苏州网站优化大型网站seo课程
1.最近帮别人爬取了东方财富股吧的帖子和评论,网址如下:http://mguba.eastmoney.com/mguba/list/zssh000300
2.爬取字段如下所示:
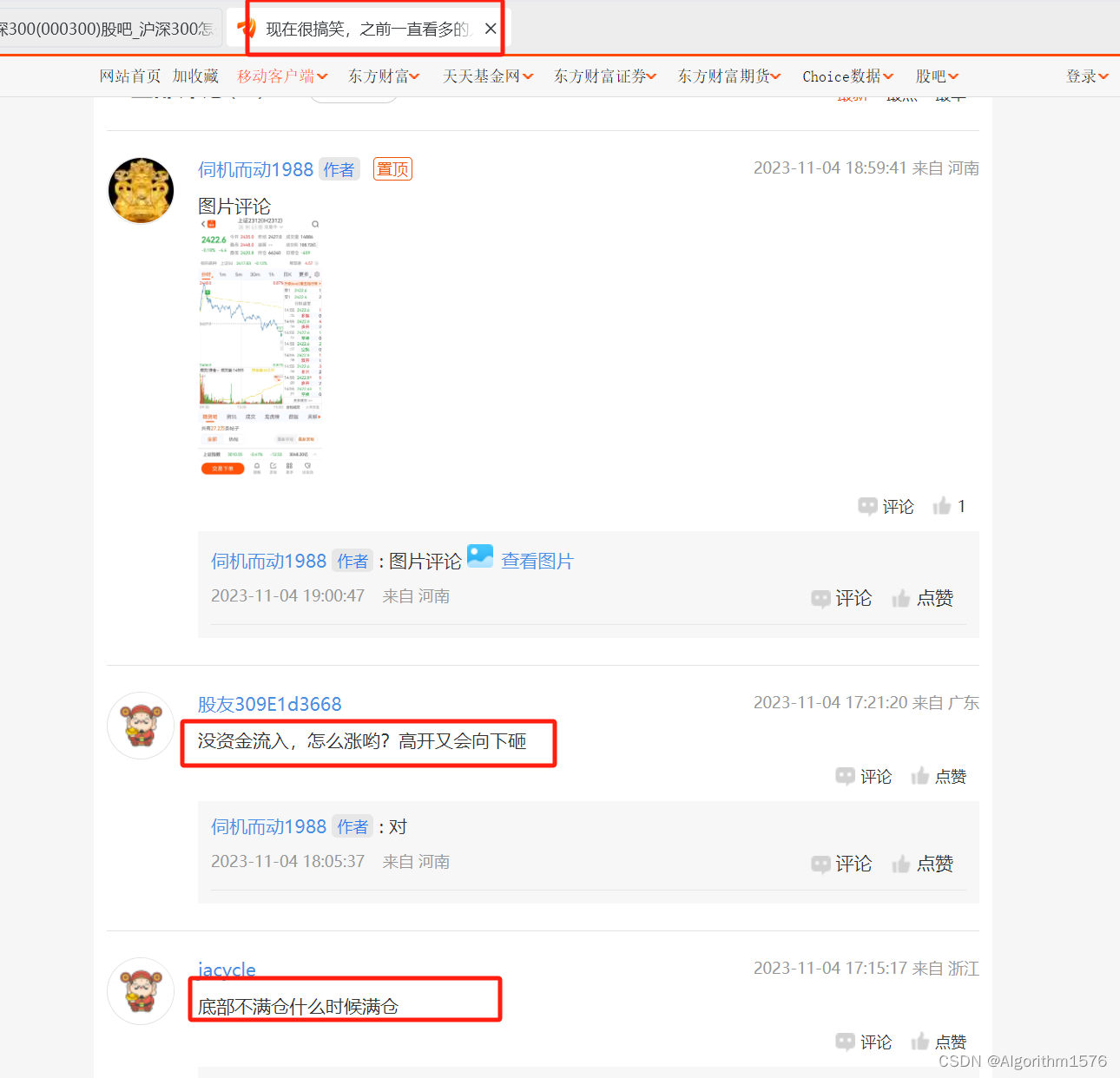
3.爬虫的大致思路如下:客户要求爬取评论数大于5的帖子,首先获取帖子链接,然后根据链接的列表进行遍历,爬取相应的信息:
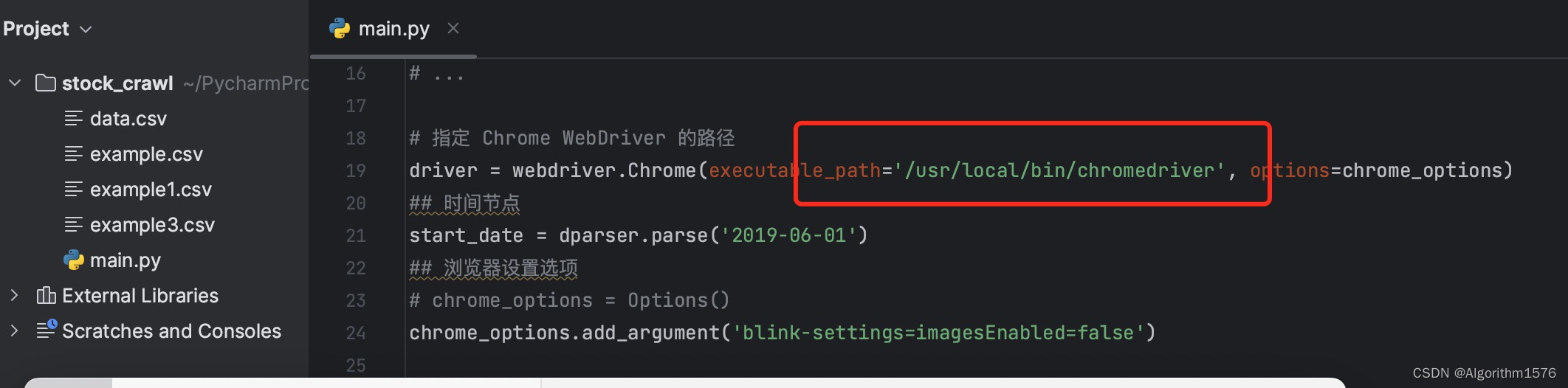
4.对于刚入门的朋友可以修改,如下chromedriver的地址,在相关第三方库都安装的情况下运行代码:
5.完整代码如下所示,在修改第二步之后是可以直接运行的,如果不能成功运行可以下面评论,或者私聊我,我会帮你解答。
import csv
import random
import re
import time
from selenium.common.exceptions import TimeoutException, NoSuchElementException
import dateutil.parser as dparser
from random import choice
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECchrome_options = webdriver.ChromeOptions()
# 添加其他选项,如您的用户代理等
# ...# 指定 Chrome WebDriver 的路径
driver = webdriver.Chrome(executable_path='/usr/local/bin/chromedriver', options=chrome_options)
## 时间节点
start_date = dparser.parse('2019-06-01')
## 浏览器设置选项
# chrome_options = Options()
chrome_options.add_argument('blink-settings=imagesEnabled=false')def get_time():'''获取随机时间'''return round(random.uniform(3, 6), 1)def get_user_agent():'''获取随机用户代理'''user_agents = ["Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)","Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)","Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20","Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)","Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"]## 在user_agent列表中随机产生一个代理,作为模拟的浏览器user_agent = choice(user_agents)return user_agentdef get_detail_urls_by_keyword(list_url):'''获取包含特定关键字的留言链接'''user_agent = get_user_agent()chrome_options.add_argument('user-agent=%s' % user_agent)drivertemp = webdriver.Chrome(options=chrome_options)drivertemp.maximize_window()drivertemp.get(list_url)# 循环加载页面或翻页,提取包含特定关键字的留言链接comments_link,link,title = [],[],[]page = 1while True:try:next_page_button = WebDriverWait(drivertemp, 30).until(EC.element_to_be_clickable((By.CLASS_NAME, "nextp")))if page >= 2:breakif next_page_button.is_enabled():next_page_button.click()page += 1else:breakexcept TimeoutException:# 当找不到下一页按钮时,抛出TimeoutException,结束循环breaktime.sleep(3)titles = drivertemp.find_elements_by_xpath('//div[@class="title"]')for element in titles:message_id = element.text.strip().split(':')[-1]title.append(message_id)comment = drivertemp.find_elements_by_xpath('//div[@class="reply"]')for element in comment:message_id = element.text.strip().split(':')[-1]comments_link.append(message_id)links = drivertemp.find_elements_by_xpath('//div[@class="title"]//a[@title]')for element in links:href = element.get_attribute("href")link.append(href)drivertemp.quit()return link,comments_link,titlelist_url = "http://mguba.eastmoney.com/mguba/list/zssh000300"
link, comments_link,title = get_detail_urls_by_keyword(list_url)# print(title)
# print(link)
# print(comments_link)# 示例的 link 和 comments 列表final_link = [] # 用于存储符合条件的链接
final_comments = []
final_title = []
comment_counts = [int(link) for link in comments_link]
# 遍历 link 和 comments 列表,检查 comments 中的元素是否大于 5
for i in range(10,len(link)):if comment_counts[i] > 5:final_link.append(link[i])final_comments.append(comments_link[i])final_title.append(title[i])print(final_title)def get_information(urls):coments_n, date, title, reply, article = [], [], [], [], []for url in urls:'''获取包含特定关键字的留言链接'''user_agent = get_user_agent()chrome_options.add_argument('user-agent=%s' % user_agent)drivertemp = webdriver.Chrome(options=chrome_options)drivertemp.maximize_window()drivertemp.get(url)titles = drivertemp.find_elements_by_xpath('//div[@class="article-head"]//h1[@class="article-title"]')for element in titles:message_id = element.text.strip().split(':')[-1]title.append(message_id)dates = drivertemp.find_elements_by_xpath('//div[@class="article-meta"]//span[@class="txt"]')for element in dates:message_time = element.text.strip()date.append(message_time)articles = drivertemp.find_elements_by_xpath('/html/body/script[20]')for element in articles:message_time = element.get_attribute("text")print(message_time)#match = re.search(r'\"desc\":\"(.*?)\"', message_time)match = re.search(r'(?<=desc:").*?(?=")', message_time)if match:desc = match.group(0)max_line_length = 15desc_lines = [desc[i:i + max_line_length] for i in range(0, len(desc), max_line_length)]desc_text_formatted = "\n".join(desc_lines)article.append(desc_text_formatted)replies = drivertemp.find_elements_by_xpath('//div[@class="short_text"]')Replies = []for element in replies:message_time = element.text.strip().split(':')[-1]Replies.append(message_time)number = len(Replies)coments_n.append(number)Reply = "\n".join([f"{i + 1}. {comment}" for i, comment in enumerate(Replies)])reply.append(Reply)drivertemp.quit()return coments_n , date, title, reply,articlecoments_n, date, title, reply,article = get_information(final_link)print(reply)
print(article)
print(date)# 将这些列表组合成一个包含五个列表的列表
data = list(zip(final_comments, date, title, reply, article))# 指定要保存的CSV文件名
csv_filename = "example3.csv"# 修改字典中的键名称,使其与列名匹配
data = [{"评论数量": c, "日期": d, "帖子标题": t, "帖子的评论": r, "帖子内容": a}for c, d, t, r, a in data
]# 使用csv模块创建CSV文件并写入数据,同时指定列名
with open(csv_filename, 'w', newline='') as csvfile:fieldnames = ["评论数量", "日期", "帖子标题", "帖子的评论", "帖子内容"]writer = csv.DictWriter(csvfile, fieldnames=fieldnames)# 写入列名writer.writeheader()# 写入数据writer.writerows(data)print(f"Data has been written to {csv_filename}")
6.有需要爬取数据的朋友,或者学习技术的朋友都可以联系我,如果觉得对你有帮助,记得点个赞哦!!!!!!