b2c网站维护公司网站建设哪个好
今日已办
Collector 指标聚合
由于没有找到 Prometheus 官方提供的可以聚合指定时间区间内的聚合函数,所以自己对接Prometheus的api来聚合指定容器的cpu_avg、cpu_99th、mem_avg
实现成功后对接小组成员测试完提供的时间序列和相关容器,将数据记录在表格中
- SpringBoot RestController
- Jackson json serialization
- data aggregation
/*** @author xzx* @date 2023/8/29*/
@RestController
@RequestMapping("/prometheus")
public class PrometheusController {@GetMappingpublic ResponseResult GetMetrics(@RequestParam String ip,@RequestParam String containerName,@RequestParam String startDay,@RequestParam String startHour,@RequestParam String startMinute,@RequestParam String startSecond,@RequestParam String endDay,@RequestParam String endHour,@RequestParam String endMinute,@RequestParam String endSecond,@RequestParam int idx) {String queryCpu = "sum(irate(container_cpu_usage_seconds_total{name=\"" + containerName + "\"}[5m])) without (cpu)";String start = startDay + "T" + startHour + ":" + startMinute + ":" + startSecond + ".000Z";String end = endDay + "T" + endHour + ":" + endMinute + ":" + endSecond + ".000Z";List<List<Object>> cpuValues = getValues(ip, start, end, queryCpu, idx);List<Double> cpuList = new ArrayList<>();Double sum = (double) 0;for (List<Object> value : cpuValues) {if (value.size() == 2) {Double v = Convert.toDouble(value.get(1));sum += v;cpuList.add(v);}}Collections.sort(cpuList);String queryMem = "container_memory_usage_bytes{name=\"" + containerName + "\"}";List<List<Object>> memValues = getValues(ip, start, end, queryMem, 0);long memSum = 0;for (List<Object> value : memValues) {if (value.size() == 2) {memSum += Convert.toLong(value.get(1));}}PrometheusMetricsData data = new PrometheusMetricsData().setCpu95th(cpuList.get(Convert.toInt(0.95 * cpuList.size())) * 100).setCpuAvg(sum / Convert.toDouble(cpuValues.size()) * 100).setMemAvg(memSum / memValues.size());return ResponseResult.okResult(data);}private List<List<Object>> getValues(String ip, String start, String end, String queryCpu, int idx) {String body = HttpRequest.get("http://" + ip + "/prometheus/api/v1/query_range?query=" + queryCpu + "&start=" + start + "&end=" + end + "&step=1s").timeout(20000).execute().body();PrometheusRespDto prometheusRespDto = JSONUtil.toBean(body, PrometheusRespDto.class);List<PromResult> result = prometheusRespDto.getData().getResult();List<List<Object>> values = result.get(idx).getValues();return values;}}测试
确定测试方案
我们打算在 10 万到 100万之间摸一个不会丢的量以及合适的并发量,作为不同 collector 测存储和查询的前提
我们能不能固定一个数量,然后使用相同的代码来上报相同的trace(只是可以控制线程睡眠时间)来调整耗时,让两种collector都能完整的上报所有数据,保证不回丢失,最后来计算存储大小

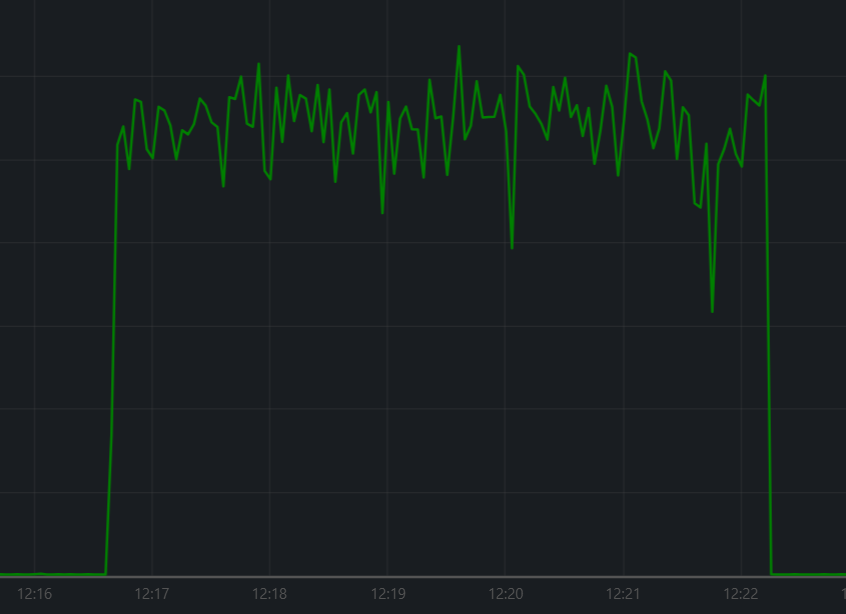

编写测试函数
func TestTraceSpan(t *testing.T) {ctx := context.Background()res, err := resource.New(ctx,resource.WithFromEnv(),resource.WithProcess(),resource.WithTelemetrySDK(),resource.WithHost(),resource.WithAttributes(attribute.String("service.name", "test-service"),attribute.String("library.language", "go"),),)if err != nil {return}otel.SetTextMapPropagator(propagation.NewCompositeTextMapPropagator(propagation.TraceContext{}, propagation.Baggage{}))tracerProviderShutDown := otelclient.InitTraceProvider(res, ctx)defer tracerProviderShutDown()testTracer := otel.Tracer("test_demo", trace.WithInstrumentationAttributes(attribute.String("demo.author", "xzx")))group := sync.WaitGroup{}for i := 0; i < 50; i++ {group.Add(1)go func(num int) {for j := 0; j < 4000; j++ {rootCtx, span := testTracer.Start(ctx, "demo_root_span"+string(rune(num)), trace.WithSpanKind(trace.SpanKindProducer), trace.WithAttributes(attribute.String("user.username", uuid.NewString())))for k := 0; k < 4; k++ {_, subSpan := testTracer.Start(rootCtx, "demo_sub_span", trace.WithSpanKind(trace.SpanKindInternal))if subSpan.IsRecording() {subSpan.SetAttributes(attribute.String("user.uuid", uuid.NewString()),attribute.Int64("user.ip", int64(uuid.New().ID())))}time.Sleep(10 * time.Millisecond)subSpan.End()}time.Sleep(time.Millisecond * 41)span.End()}group.Done()}(i)}group.Wait()
}
汇总进度和问题
- es 的监控平台的 文档数 和 kibana 的数据条数不一致,最后以 kibana 的 hits 为基准
- 测试上报最终的数据丢失,测试不准确,由于并发数太多了,大多数据都存储在内存中,由于超时被丢弃
- 官方的 otel-collector 的数据库和表创建耗费时间长
- 协助测试组员的记录来聚合容器指标,记录表格内容,完成 trace-collector、metric-collector的测试结果表格
- clickhouse的数据**“幻读”**
- 存在副本
- 同步时间较长,写入后需要一段时间后才能看到另一个节点的数据拷贝
- 删除通过SQL
DROP Database database_name SYNC无法drop所有节点的数据库,故删除后一段时间后又会查询到该数据库的数据
- 测试周期较长,测试结果的采集不够自动化,测试样例和次数不太丰富,由于前期的测试方案方向和方法不正确,走了很多外路,不过在组员的努力和导师的指导下跌跌撞撞勉强完成测试结果
- 。。。
明日待办
- PPT制作
- 录制Showcase视频
- 绘制Showcase表格和图像
- 输出测试结果的总结