做网站的周记seo快速排名源码
前置概念导入
-
协同过滤(Collaborative Filtering):这是一种推荐系统的方法,依据用户之间或物品之间的相似性来进行推荐。协同过滤通常分为两种主要类型:用户基于(user-based)和物品基于(item-based)协同过滤。用户基于协同过滤关注于找出相似用户的偏好来推荐物品,而物品基于协同过滤则是通过比较物品之间的相似性来进行推荐。
-
矩阵分解(Matrix Factorization):这是协同过滤的一种实现方式,尤其用于处理用户-物品评分矩阵中的缺失数据。矩阵分解通过将大的用户-物品矩阵分解为用户潜在因子矩阵和物品潜在因子矩阵的乘积,以揭示用户和物品的潜在特征。矩阵分解使得系统能够预测未知评分,从而为用户提供个性化推荐。
交替最小二乘法
对矩阵进行分解,有很多种方式,比如奇异值分解(SVD),SVD++和交替最小二乘法(ALS)等,Spark MLlib中推荐算法使用的是ALS方式。
交替最小二乘法ALS(Alternating Least Squares, )是一种用于矩阵分解的优化算法,主要用于推荐系统中的协同过滤。其核心思想是通过迭代过程交替固定用户和物品的潜在因子,然后最小化实际观测到的评分与预测评分之间的差异。具体来说,ALS的思想可以分为以下几个步骤:
初始化:随机初始化用户矩阵U和物品矩阵V的潜在因子。
固定一个因子:在每次迭代中,先固定一个因子(例如,先固定用户因子U),只优化另一个因子(物品因子V)。
最小化误差:通过最小化观测到的评分和通过当前因子乘积预测的评分之间的误差来更新固定的因子。
交替优化:然后固定物品因子V,优化用户因子U。重复这个步骤直到收敛,即两者的更新不再导致总误差显著减少。
正则化:为了防止过拟合,在优化过程中通常会加入正则化项,以平衡模型的复杂度和训练数据的拟合程度。
收敛:当达到预设的迭代次数或者误差减少到一个阈值以下时,算法结束。
交替最小二乘法的一个关键优点是它能够有效地处理大规模、稀疏的数据集,并且易于并行化,这使得它特别适合分布式计算环境,如Apache Spark。此外,由于每次迭代中只固定一个因子,这简化了优化问题,使得每一步的计算都是一个简单的最小二乘问题,可以高效解决。
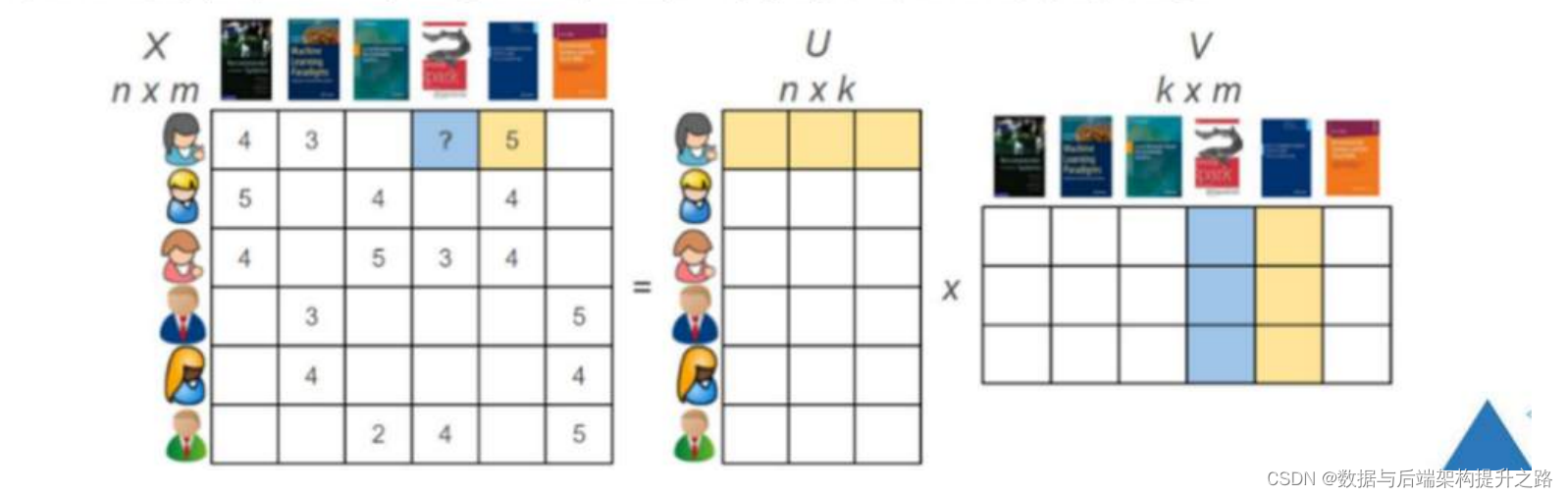
假设我们有以下的用户-物品评分矩阵,其中未知项用 "?" 表示:
用户\物品 物品1 物品2 物品3
用户A 5 ? 3
用户B 4 ? ?
用户C ? 2 4
我们想要分解这个矩阵为两个低秩矩阵(用户因子矩阵 U 和物品因子矩阵 V),假设我们选择的潜在因子的数量是 2。初始化 U 和 V 可能如下所示:
U (2x3) = | ua1 ua2 |
| ub1 ub2 |
| uc1 uc2 |V (2x3) = | va1 va2 va3 |
| vb1 vb2 vb3 |
假定我们先固定物品因子 V,优化用户因子 U。对于用户A和物品3的组合,我们的目标是最小化实际评分(3)和预测评分(ua1 * va3 + ua2 * vb3)的误差。通过最小二乘法优化 ua1 和 ua2。
然后,我们固定用户因子 U,优化物品因子 V。同样地,我们要最小化实际评分和预测评分的误差,这一次是通过优化 va1, va2, va3, vb1, vb2, vb3。
假设经过一次迭代后,U 和 V 更新如下:
U (2x3) = | 0.9 1.1 |
| 0.8 0.9 |
| 1.0 0.8 |V (2x3) = | 1.2 0.9 1.3 |
| 1.1 1.0 1.2 |
接下来,我们会计算预测评分矩阵,目标是得到 U 和 V 的乘积,这个乘积能够近似原始的评分矩阵。当 U 和 V 的更新使得总误差不再显著减少,或者达到预设的迭代次数,或者误差减少到一个预设的阈值以下时,我们可以认为模型已经收敛,此时的 U 和 V 就是我们通过 ALS 算法得到的矩阵分解结果。这些结果可以用来预测缺失的评分,为用户提供推荐。在这个例子中,U 的每一行对应一个用户的潜在因子表示,而 V 的每一列对应一个物品的潜在因子表示。