zblog做的商城网站上海有实力的seo推广咨询
写本篇文章,我认为是能把自己所理解的内容分享出来,说不定就有和我一样有这样思维的共同者,希望本篇文章能帮助大家!✨✨
文章目录
- 一、 🌈python介绍和分析
- 二、 🌈http请求
- 三、 🌈http响应
- 四、 🌈教程演示
- 五、🌈获取豆瓣top榜上前250部电影的响应内容
一、 🌈python介绍和分析
Python爬虫,又称网络爬虫或网页抓取程序,是一种自动化程序,它主要用于从互联网上抓取大量信息。这类程序按照预设的规则遍历互联网上的网页,并抽取其中有价值的数据。
思维导图:
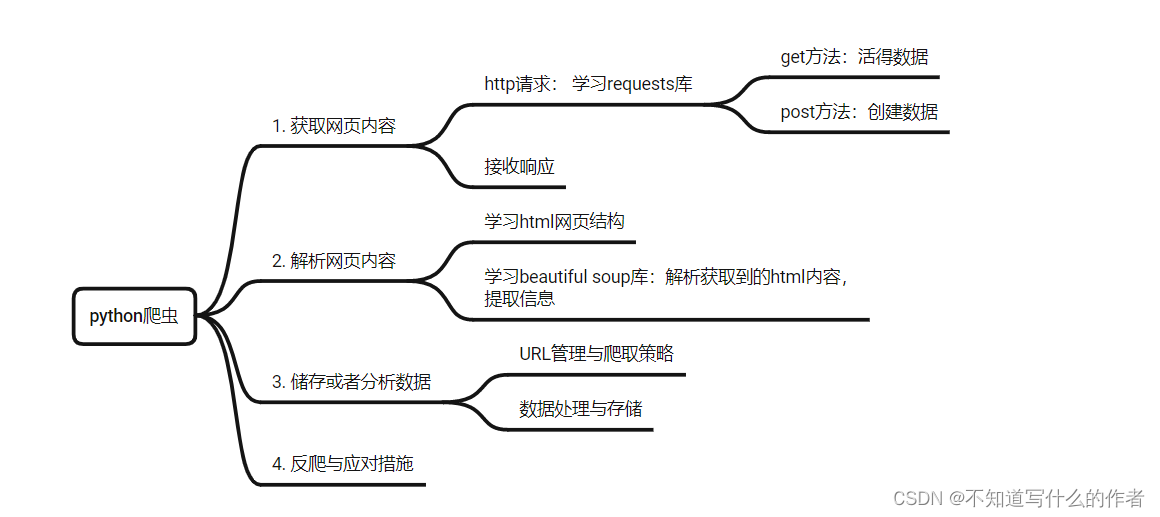
具体内容,Python爬虫通常涉及以下几个核心步骤:
-
发起请求:
- 使用Python中的HTTP库(如
requests)模拟浏览器发送HTTP/HTTPS请求到目标网站,每个请求都包含了URL地址以及可能的请求头信息(如User-Agent、Cookie等)。
- 使用Python中的HTTP库(如
-
接收响应:
- 当服务器接收到请求后,会返回一个HTTP响应,其中包括状态码、响应头和网页内容(通常是HTML,但也可能是JSON、XML或其他格式)。
-
解析内容:
- 使用解析库(如
BeautifulSoup、lxml用于HTML/XML解析,PyQuery、parsel等)对响应内容进行解析,从中提取所需的数据。如果是结构化数据如JSON,可以直接使用Python的json模块解析。
- 使用解析库(如
-
数据处理与存储:
- 抽取后的数据会被进一步处理(清洗、转化等),然后存储在本地文件(如CSV、JSON、TXT等格式)或数据库系统(如MySQL、MongoDB等)中,以便后续分析或构建应用。
-
URL管理与爬取策略:
- 爬虫还需要一个URL管理机制来跟踪已经访问过的链接,避免重复抓取,并决定接下来要抓取哪个URL,这可以通过内存、数据库或队列等方式实现。同时,爬虫还会涉及到一些高级策略,比如深度优先搜索(DFS)、广度优先搜索(BFS)、优先级队列等。
-
反爬与应对措施:
- 针对网站的反爬虫策略,爬虫开发者还可能需要处理cookies、session管理、验证码识别、动态加载内容等问题,甚至采用IP代理池等技术绕过访问限制。
本章节主要讲前面的第一小节:如何获取网页内容
二、 🌈http请求
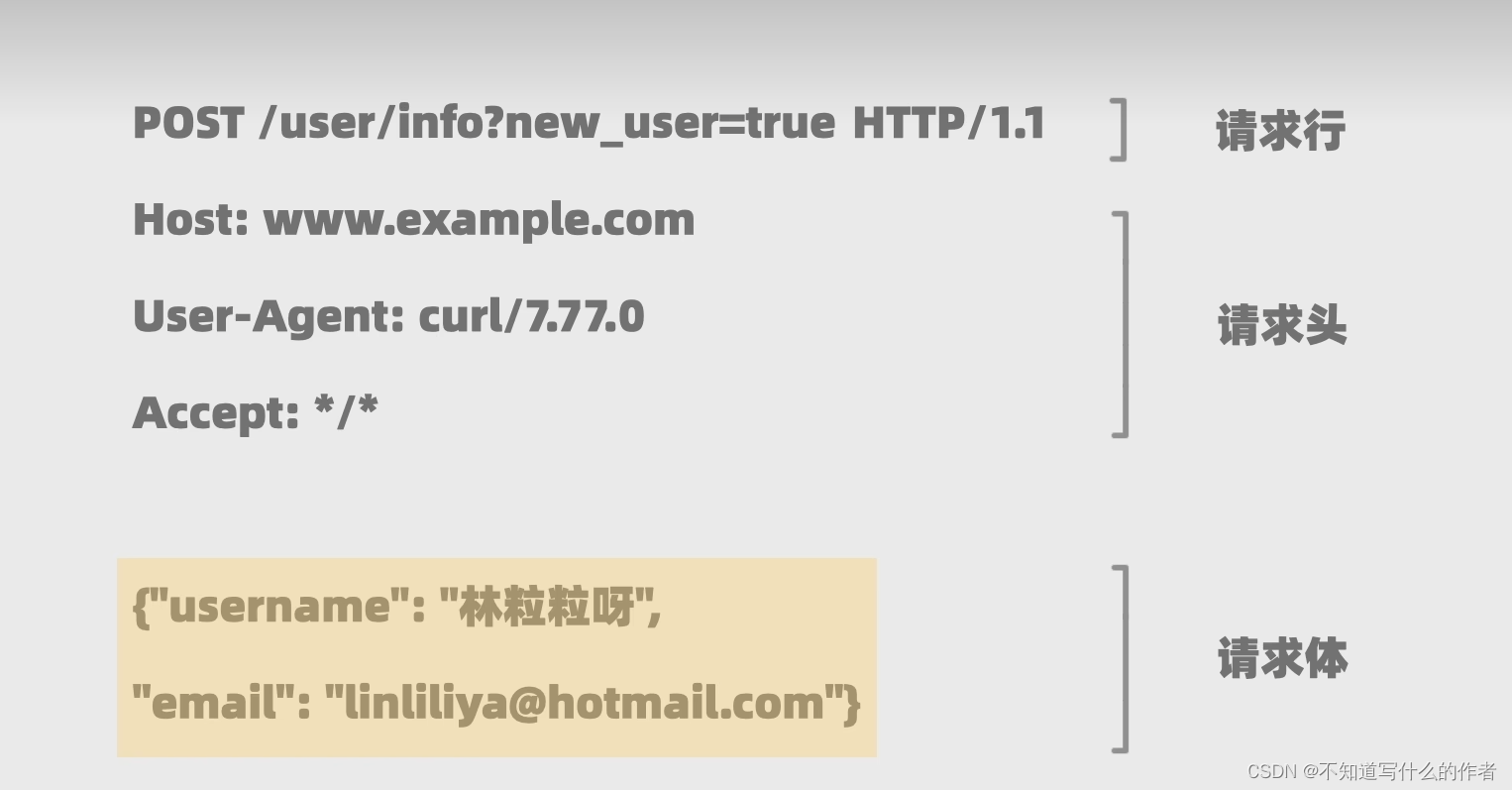
- 请求行:
解析:方法类型 / 资源路径 (后面可跟查询参数)/ 协议版本
- 请求头
解析:域名 / 路径 ?查询参数User-Aent:用来告知服务器客户端的相关信息accept:客户端想接收的响应数据是什么类型的(文件名/类型和任意类型:*/*)
- 请求体
解析:存放客户端传给服务器的其他任意数据get的请求体一般是空的
三、 🌈http响应
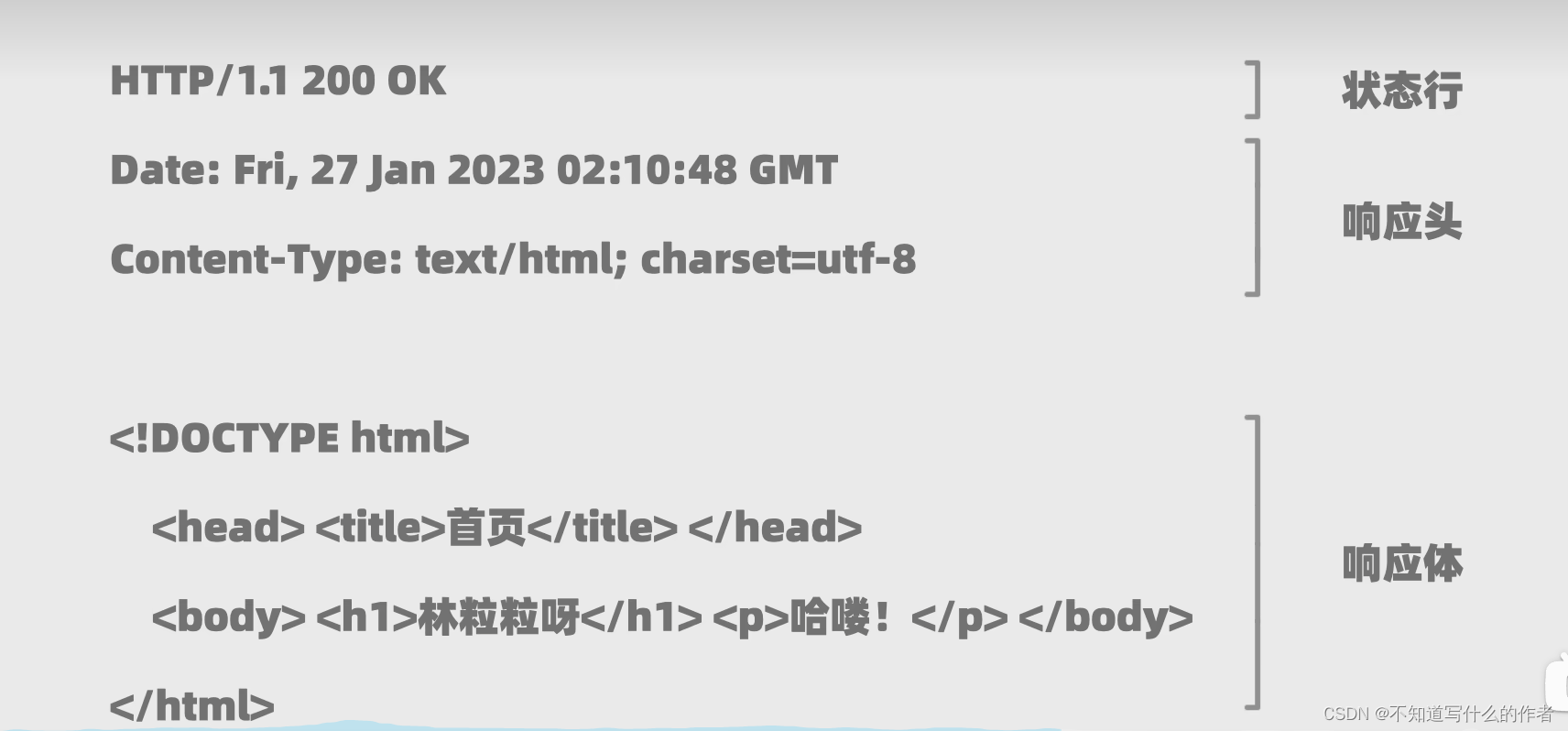
- 状态行
解析:
协议版本 、状态码、状态消息

解析:
状态码和状态消息是对应的:(1)2开头的表示成功,请求已经完成处理(2)3开头的表示重定向,需要进一步的操作(3)4开头的表示客户端错误,比如请求里面有错误 或请求的资源无效等(4)5开头的表示服务器错误,比如出现问题或者正在维护
- 响应头
解析:
Date:生成响应的日期和时间Content-Type:返回内的类型及编码格式
- 响应体
解析:
html网页内容
四、 🌈教程演示
- 安装python第三方库requests,打开终端输入
pip install requests

import requests
# 获取请求网址 https://books.toscrape.com/ ——专门用于爬虫练习的网站
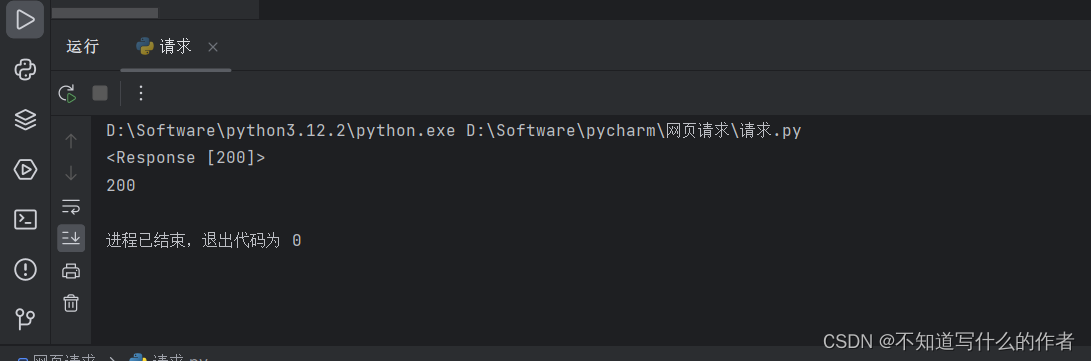
response=requests.get("https://books.toscrape.com/")
print(response)
print(response.status_code) # 检验请求是否成 返回200则成功
如果输出显示的内容是200,则说明该请求成功,其他则是其他原因,具体可参考请求响应错误原因:HTTP 响应状态码
输出:
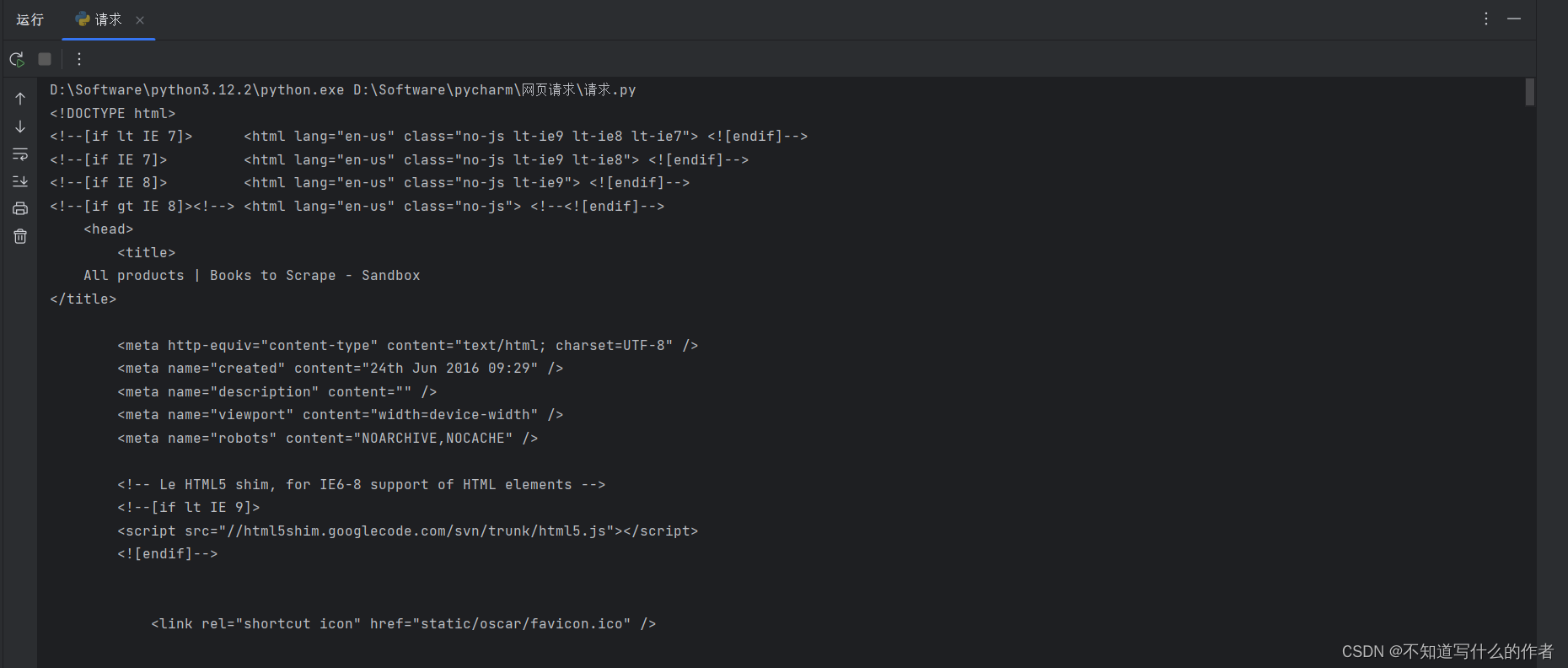
- 利用if语句判断和ok的方法,请求成功则返回网页内容(以html的格式打印输出)
import requests
# 获取请求网址 https://books.toscrape.com/ ——专门用于爬虫练习的网站
response=requests.get("https://books.toscrape.com/")
# 利用判断语句,使用ok的方法获取网页数据
if response.ok:print(response.text) # 获取网页内容
else:print("请求失败")
输出内容:
五、🌈获取豆瓣top榜上前250部电影的响应内容
豆瓣网网址:https://movie.douban.com/top250
- 先看请求情况:
import requests
# 获取豆瓣top榜上前250部电影的响应内容
response=requests.get("https://movie.douban.com/top250")
# 查看获取响应的状态码是什么
print(response.status_code)
输出:
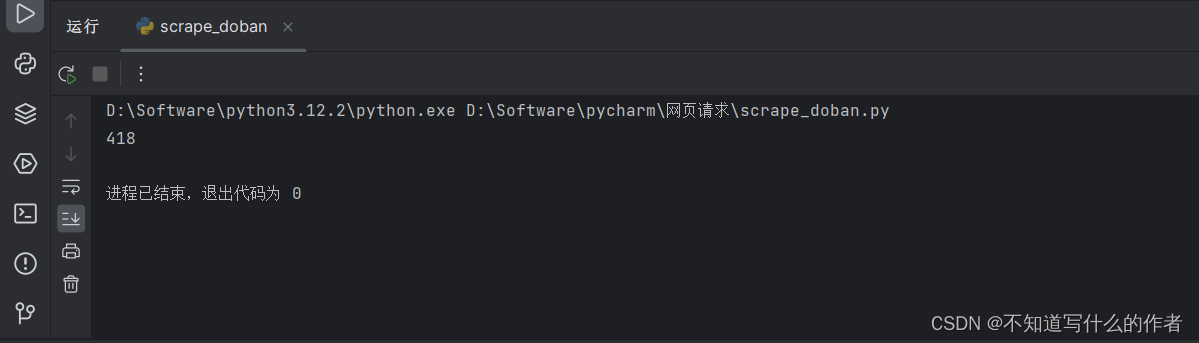
具体什么是418参考:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status/418
- 如何模拟浏览器的构成(请求头)
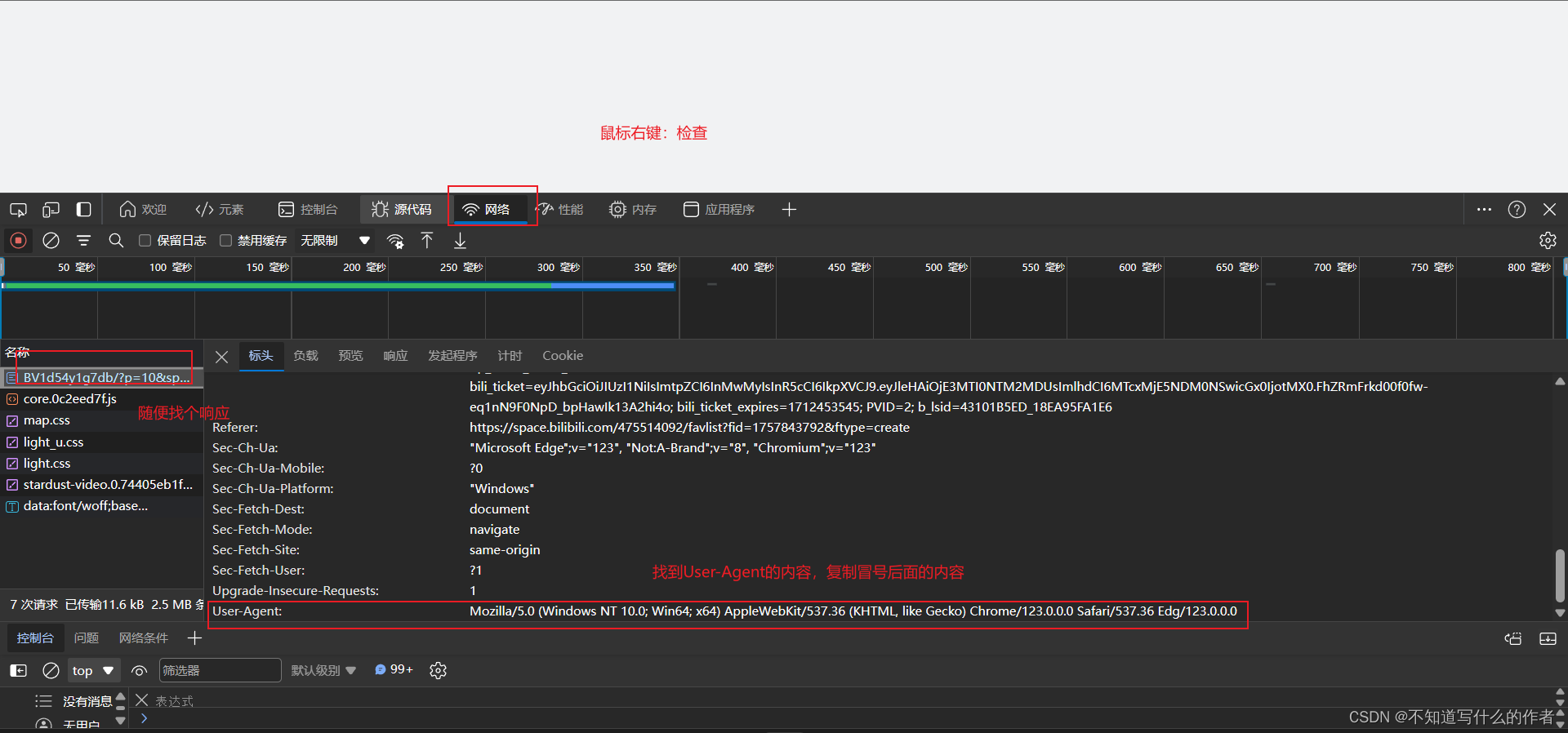
随便找一个网页,进入控制台,鼠标右键——检查或者按F12 ,网络(刷新)——随便点击一个响应——找到Request Headers里面的User-Agent,复制后面的内容写入代码中。
代码块:
import requests# 模拟浏览器的构成(请求头)以字典的形式存储,将复制冒号后的内容填写,
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0"
}
# 获取豆瓣top榜上前250部电影的响应内容
response=requests.get("https://movie.douban.com/top250",headers=headers)
# 查看获取响应的状态码是什么
print(response.status_code)
# 打印response的内容
print(response.text)
显示200 ,响应成功且获取信息成功
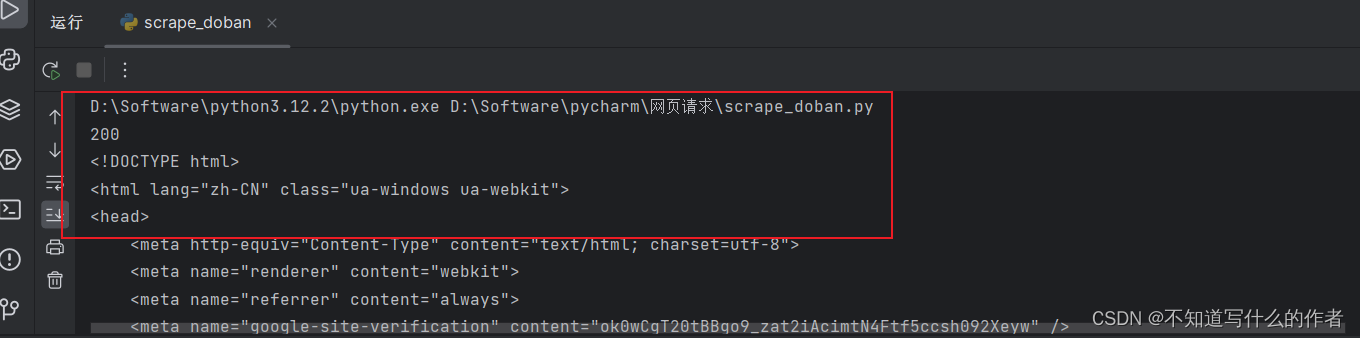
本章内容到此结束,谢谢大家的支持,希望本期作品可以简单帮助大家了解爬虫基础
大家一起学习呀!🔥🔥🔥🔥