湖北平台网站建设哪家好珠海seo推广

TiDB从0到1系列
- TiDB-从0到1-体系结构
- TiDB-从0到1-分布式存储
- TiDB-从0到1-分布式事务
- TiDB-从0到1-MVCC
- TiDB-从0到1-部署篇
- TiDB-从0到1-配置篇
- TiDB-从0到1-集群扩缩容
一、数据导出
TiDB中通过Dumpling来实现数据导出,与MySQL中的mysqldump类似,其属于逻辑备份,备份出的文件格式为SQL或CSV。
同样与MySQL中的mysqldump应用场景类似,Dumping最好使用于对小规模的数据备份(导出)
二、Dumpling实操
1、下载安装
wget https://download.pingcap.org/tidb-community-toolkit-v7.5.1-linux-amd64.tar.gz
------
tar -xvf tidb-community-toolkit-v7.5.1-linux-amd64.tar.gz
2、解压需要的工具包

tar xvf dumpling-v7.5.1-linux-amd64.tar.gz
2、权限控制
使用dumpling的用户需要有对应的权限
- select
- reload
- lock tables
- replication client
- process
3、参数
./dumpling --help
-----------------
Flags:--allow-cleartext-passwords Allow passwords to be sent in cleartext (warning: don't use without TLS)--azblob.access-tier string Specify the storage class for azblob--azblob.account-key string Specify the account key for azblob--azblob.account-name string Specify the account name for azblob--azblob.encryption-key string Specify the server side encryption customer provided key--azblob.encryption-scope string Specify the server side encryption scope--azblob.endpoint string (experimental) Set the Azblob endpoint URL--azblob.sas-token string Specify the SAS (shared access signatures) for azblob--ca string The path name to the certificate authority file for TLS connection--case-sensitive whether the filter should be case-sensitive--cert string The path name to the client certificate file for TLS connection--complete-insert Use complete INSERT statements that include column names-c, --compress string Compress output file type, support 'gzip', 'snappy', 'zstd', 'no-compression' now--consistency string Consistency level during dumping: {auto|none|flush|lock|snapshot} (default "auto")--csv-delimiter string The delimiter for values in csv files, default '"' (default "\"")--csv-line-terminator string The line terminator for csv files, default '\r\n' (default "\r\n")--csv-null-value string The null value used when export to csv (default "\\N")--csv-separator string The separator for csv files, default ',' (default ",")-B, --database strings Databases to dump--dump-empty-database whether to dump empty database (default true)--escape-backslash use backslash to escape special characters (default true)-F, --filesize string The approximate size of output file--filetype string The type of export file (sql/csv)-f, --filter strings filter to select which tables to dump (default [*.*,!/^(mysql|sys|INFORMATION_SCHEMA|PERFORMANCE_SCHEMA|METRICS_SCHEMA|INSPECTION_SCHEMA)$/.*])--gcs.credentials-file string (experimental) Set the GCS credentials file path--gcs.endpoint string (experimental) Set the GCS endpoint URL--gcs.predefined-acl string (experimental) Specify the GCS predefined acl for objects--gcs.storage-class string (experimental) Specify the GCS storage class for objects--help Print help message and quit-h, --host string The host to connect to (default "127.0.0.1")--key string The path name to the client private key file for TLS connection-L, --logfile path Log file path, leave empty to write to console--logfmt format Log format: {text|json} (default "text")--loglevel string Log level: {debug|info|warn|error|dpanic|panic|fatal} (default "info")-d, --no-data Do not dump table data--no-header whether not to dump CSV table header-m, --no-schemas Do not dump table schemas with the data--no-sequences Do not dump sequences (default true)-W, --no-views Do not dump views (default true)--order-by-primary-key Sort dump results by primary key through order by sql (default true)-o, --output string Output directory (default "./export-2024-06-26T11:19:24+08:00")--output-filename-template string The output filename template (without file extension)--params stringToString Extra session variables used while dumping, accepted format: --params "character_set_client=latin1,character_set_connection=latin1" (default [])-p, --password string User password-P, --port int TCP/IP port to connect to (default 4000)-r, --rows uint If specified, dumpling will split table into chunks and concurrently dump them to different files to improve efficiency. For TiDB v3.0+, specify this will make dumpling split table with each file one TiDB region(no matter how many rows is).If not specified, dumpling will dump table without inner-concurrency which could be relatively slow. default unlimited--s3.acl string (experimental) Set the S3 canned ACLs, e.g. authenticated-read--s3.endpoint string (experimental) Set the S3 endpoint URL, please specify the http or https scheme explicitly--s3.external-id string (experimental) Set the external ID when assuming the role to access AWS S3--s3.provider string (experimental) Set the S3 provider, e.g. aws, alibaba, ceph--s3.region string (experimental) Set the S3 region, e.g. us-east-1--s3.role-arn string (experimental) Set the ARN of the IAM role to assume when accessing AWS S3--s3.sse string Set S3 server-side encryption, e.g. aws:kms--s3.sse-kms-key-id string KMS CMK key id to use with S3 server-side encryption.Leave empty to use S3 owned key.--s3.storage-class string (experimental) Set the S3 storage class, e.g. STANDARD--snapshot string Snapshot position (uint64 or MySQL style string timestamp). Valid only when consistency=snapshot-s, --statement-size uint Attempted size of INSERT statement in bytes (default 1000000)--status-addr string dumpling API server and pprof addr (default ":8281")-T, --tables-list strings Comma delimited table list to dump; must be qualified table names-t, --threads int Number of goroutines to use, default 4 (default 4)--tidb-mem-quota-query uint The maximum memory limit for a single SQL statement, in bytes.-u, --user string Username with privileges to run the dump (default "root")-V, --version Print Dumpling version--where string Dump only selected records
4、导出数据
导出test库下的所有数据,同时指定导出文件为sql,导出目录为/tmp/test,导出线程2,每10w行数据切换一次文件,每200MB切换一次文件
./dumpling -h192.168.14.121 -P4000 -uroot -p123456 --filetype sql -t 2 -o /tmp/test -r 100000 -F200MiB -B test
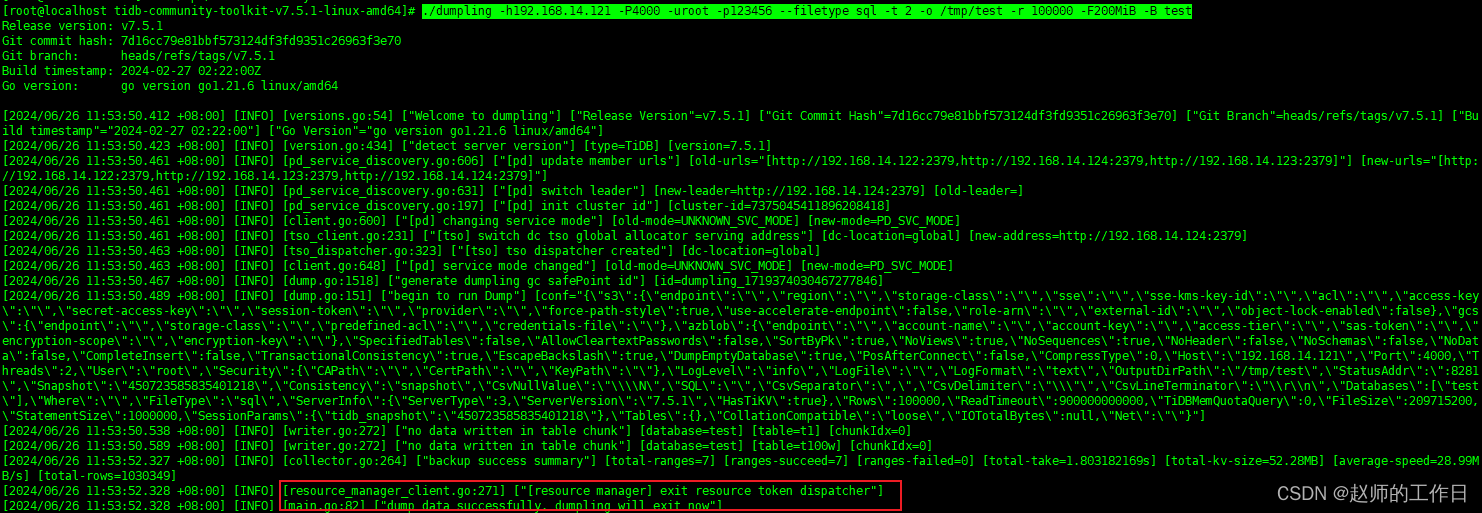
(备份成功)
查看导出的内容

其中
- metadata:数据导出时的时间,binlog位置点
- xxx.schema.sql:建库建表语句
- xxx.000000100.sql:数据
导出test库下t1的表中id>10的数据,同时指定导出文件为CSV,导出目录为/tmp/t1,导出线程2,每100行数据切换一次文件,每100MB切换一次文件
./dumpling -h192.168.14.121 -P4000 -uroot -p123456 --filetype csv -t 2 -o /tmp/t1 -r 100 -F100MiB -T test.t1 --where "id>10"
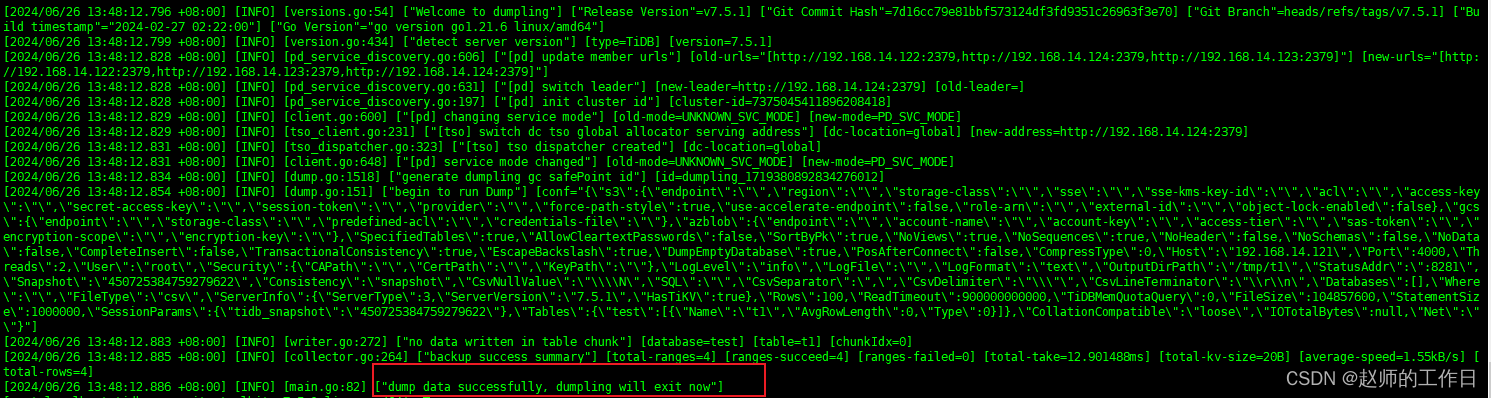
(备份成功)
查看导出的内容

建库\建表语句依旧是SQL文件
不过数据为CSV格式
同时Dumpling默认也是一致性备份,通过MVCC机制备份出某个时间点的快照数据
三、数据导入
TiDB中提供了一种叫TiDB Lightning(Physical Import Mode模式)的数据导入方式,因为其导入过程TiDB是不能对外提供服务的,而且数据是从本地直接导入到TiKV,所以应用场景更适合TiDB集群初始化。
整个Lightning原理如下
- 将集群切换为导入模式
- 创建对应库表
- 分割导入数据源
- 读取数据源文件
- 将源数据文件写入本地临时文件
- 导入临时文件到TiKV集群
- 检验与分析
- 将集群切换回正常模式
四、Lightning实操
1、下载安装
wget https://download.pingcap.org/tidb-community-toolkit-v7.5.1-linux-amd64.tar.gz
------
tar -xvf tidb-community-toolkit-v7.5.1-linux-amd64.tar.gz
2、解压需要的工具包
tar xvf tidb-lightning-v7.5.1-linux-amd64.tar.gz
3、准备配置文件
vim tidb-lighning.toml
-----------------
[lightning]
#逻辑cpu数量
#region-concurrency =
#日志
level = "info"
file = "tidb-lighning.log"[tikv-importer]
#开启并行导入
incremental-import = true
#设置为local模式
backend = "local"
#设置本地临时存储路径
sorted-kv-dir = "/tmp/sorted-kv-dir"[mydumper]
#源数据目录
data-source-dir = "/tmp/test"[tidb]
#tidb-server监听地址
host = "192.168.14.121"
port = 4000
user = "root"
password = ""
#表架构信息
status-port = 10080
#pd地址
pd-addr = "192.168.14.122:2379"
4、导入数据
我这里就将原集群清空,然后将上面-B导出的test库恢复回去
./tidb-lightning --config /opt/tidb-lighning.toml

(导入成功)
5、进入数据库校验
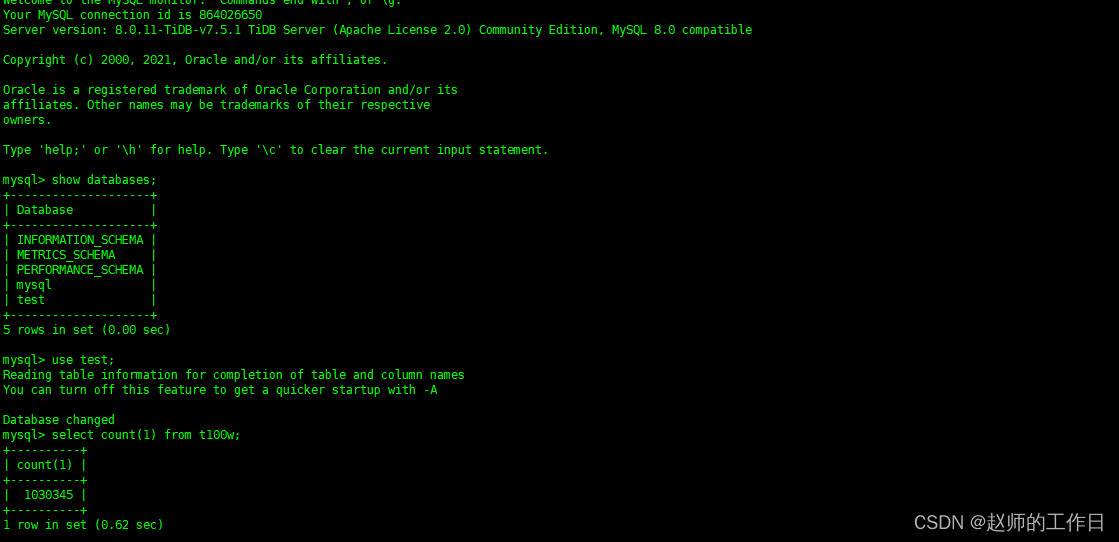
(验证无误)
彩蛋
TiDB-Lightning功能强大,可以通过配置文件过滤导入指定的表,同时也支持将MySQL中分库分表数据导入到TiDB中合并为一张表,还有断点续传等功能。
具体可以参考官方文档
