阴阳师网站怎么做sem竞价代运营公司
文章目录
- 一、Hive基本概念
- 二、Hive数据类型
- 三、DDL,DML,DQL
- 1 DDL操作
- 2 DML操作
- 3 DQL操作
- 四、分区操作和分桶操作
- 1、分区操作
- 2、分桶操作
- 五、Hive函数
- 六、文件格式和压缩格式
一、Hive基本概念
Hive是什么?
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。
Hive的本质
Hive的本质是将HQL转化成MR程序。存储在HDFS上,计算使用MR引擎,运行在yarn上。
Hive架构原理
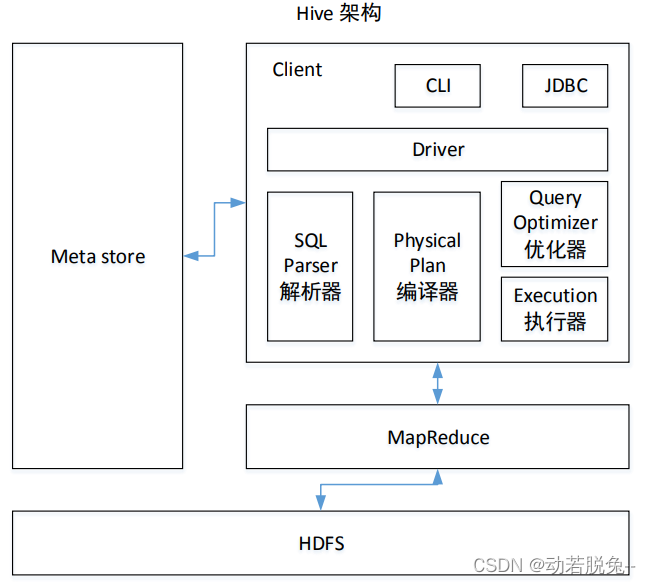 1)用户接口:Client
1)用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问 hive)
2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、
表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore
3)驱动器:Driver
1.进入程序,利用Antlr框架定义HQL的语法规则,对HQL完成词法语法解析,将HQL转换为为AST(抽象语法树);
⒉遍历AST,抽象出查询的基本组成单元QueryBlock (查询块),可以理解为最小的查询执行单元;
3.遍历QueryBlock,将其转换为OperatorTree(操作树,也就是逻辑执行计划),可以理解为不可拆分的一个逻辑执行单元;
4.使用逻辑优化器对OperatorTree(操作树)进行逻辑优化。例如合并不必要的ReduceSinkOperator,减少Shuffle数据量;
5.遍历OperatorTree,转换为TaskTree。也就是翻译为MR任务的流程,将逻辑执行计划转换为物理执行计划;
6.使用物理优化器对TaskTree进行物理优化:
7.生成最终的执行计划,提交任务到Hadoop集群运行。
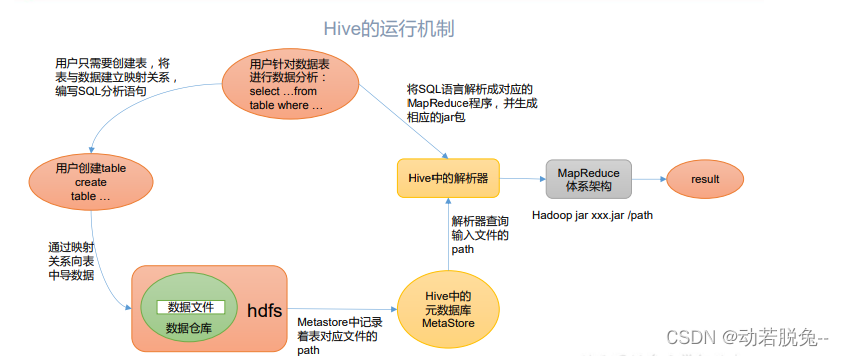
二、Hive数据类型
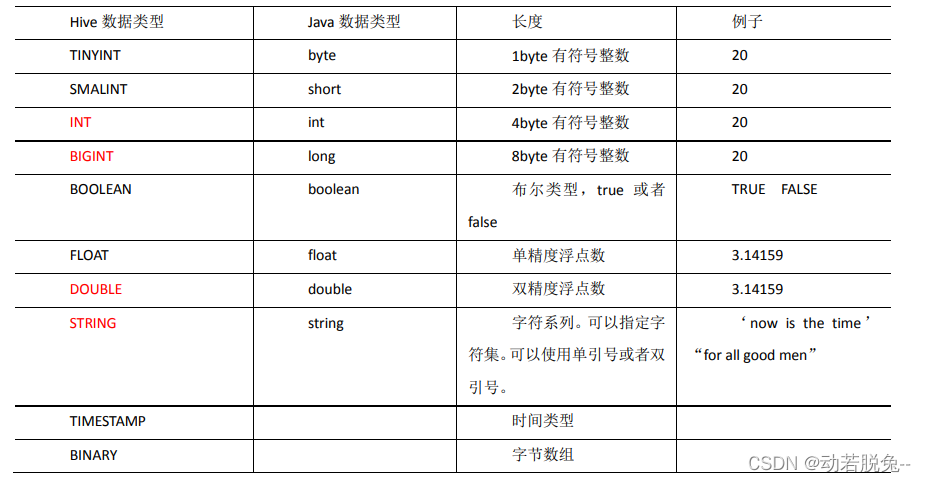
-
基本数据类型
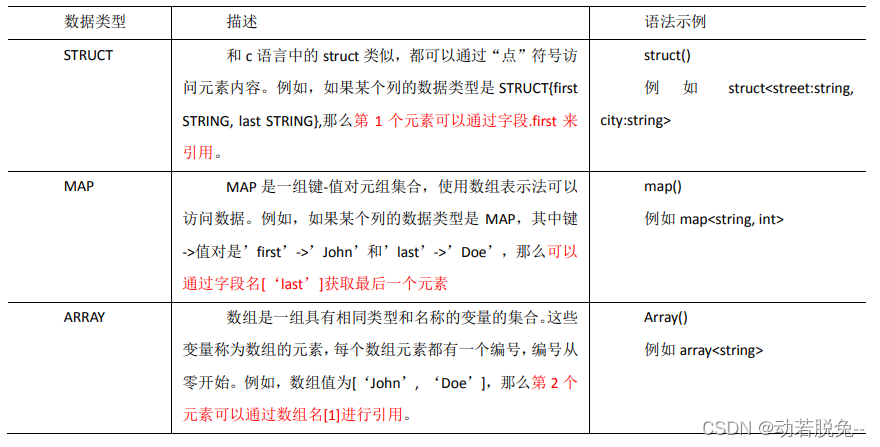
-
集合数据类型
-
类型转换
Hive默认会进行隐式类型转换
隐式类型转换规则如下
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如 TINYINT 可以转换成INT,INT 可以转换成 BIGINT。
(2)所有整数类型、FLOAT 和 STRING 类型都可以隐式地转换成 DOUBLE。
(3)TINYINT、SMALLINT、INT 都可以转换为 FLOAT。
(4)BOOLEAN 类型不可以转换为任何其它的类型。
三、DDL,DML,DQL
1 DDL操作
- 创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES (property_name=property_value, ...)]; - 创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] [AS select_statement]
2)字段解释说明
(1)CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;
用户可以用 IF NOT EXISTS 选项来忽略这个异常。
更多 Java –大数据 –前端 –python 人工智能资料下载,可百度访问:尚硅谷官网
(2)EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实
际数据的路径(LOCATION),在删除表的时候,内部表的元数据和数据会被一起删除,而外
部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释。
(4)PARTITIONED BY 创建分区表
(5)CLUSTERED BY 创建分桶表
(6)SORTED BY 不常用,对桶中的一个或多个列另外排序
(7)ROW FORMAT DELIMITED [FIELDS TERMINATED BY char]
[COLLECTION ITEMS TERMINATED BY char]
row format delimited fields terminated by ‘,’ – 列分隔符
lines terminated by ‘\n’; – 行分隔符
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, …)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW
FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
SerDe 是 Serialize/Deserilize 的简称, hive 使用 Serde 进行行对象的序列与反序列化。
(8)STORED AS 指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列
式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED
AS SEQUENCEFILE。
(9)LOCATION :指定表在 HDFS 上的存储位置。
(10)AS:后跟查询语句,根据查询结果创建表。
(11)LIKE 允许用户复制现有的表结构,但是不复制数据。
2 DML操作
- 向表中装载数据
hive> load data [local] inpath '数据的 path' [overwrite] into table student [partition (partcol1=val1,…)];
(1)load data:表示加载数据
(2)local:表示从本地加载数据到 hive 表;否则从 HDFS 加载数据到 hive 表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
具体数据导入导出操作命令参考:
http://t.csdn.cn/CBsYE
3 DQL操作
hiveSql执行顺序
from ..on .. join .. where .. group by .. having .. select .. distinct .. order by .. limit
hiveSQL书写规则
-
SELECT [ALL | DISTINCT] select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BY col_list] [ORDER BY col_list] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ] [LIMIT number]
注意:
(1)SQL 语言大小写不敏感。
(2)SQL 可以写在一行或者多行
(3)关键字不能被缩写也不能分行
(4)各子句一般要分行写。
(5)使用缩进提高语句的可读性。 -
排序
-
Order By:全局排序,只有一个 Reduce
-
每个 Reduce 内部排序(Sort By)
Sort By:对于大规模的数据集 order by 的效率非常低。在很多情况下,并不需要全局排
序,此时可以使用 sort by。
Sort by 为每个 reducer 产生一个排序文件。每个 Reducer 内部进行排序,对全局结果集
来说不是排序。 -
Distribute By: 在有些情况下,我们需要控制某个特定行应该到哪个 reducer,通常是为了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by 类似 MR 中 partition(自定义分区),进行分区,结合 sort by 使用。
对于 distribute by 进行测试,一定要分配多 reduce 进行处理,否则无法看到 distribute by 的效果。 -
cluster by
当 distribute by 和 sorts by 字段相同时,可以使用 cluster by 方式。
cluster by 除了具有 distribute by 的功能外还兼具 sort by 的功能。但是排序只能是升序
排序,不能指定排序规则为 ASC 或者 DESC。
四、分区操作和分桶操作
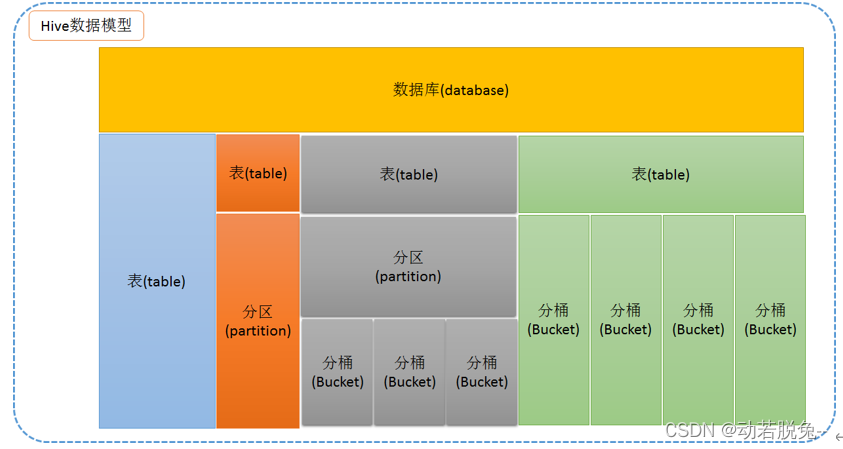
1、分区操作
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
create table dept_partition(
deptno int, dname string, loc string
)
partitioned by (day string)
row format delimited fields terminated by '\t';
注意:分区字段不能是表中已经存在的数据,可以将分区字段看作表的伪列,注意:分区表加载数据时,必须指定分区
2、分桶操作
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分。
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
分区针对的是数据的存储路径;分桶针对的是数据文件。
创建分桶表
create table stu_buck(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';注意:
(1)reduce 的个数设置为-1,让 Job 自行决定需要用多少个 reduce 或者将 reduce 的个数设置为大于等于分桶表的桶数
(2)从 hdfs 中 load 数据到分桶表中,避免本地文件找不到问题
(3)不要使用本地模式
五、Hive函数
hive窗口函数整理参考如下链接
http://t.csdn.cn/xbPnv
六、文件格式和压缩格式
文件格式
文件格式按面向的存储形式不同,分为面向行和面向列两大类文件格式。
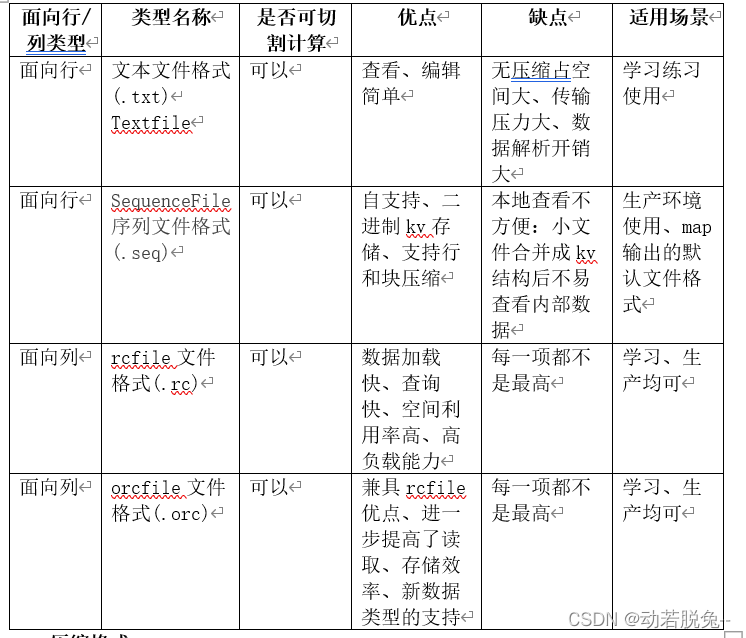 压缩格式按其可切分独立性,分成可切分和不可切分两种。
压缩格式按其可切分独立性,分成可切分和不可切分两种。
