高校学风建设网站手机搜索引擎排名
最近在搜集数据要做分析,一般的数据来源是一手数据(生产的)和二手数据(来自其他地方的)。
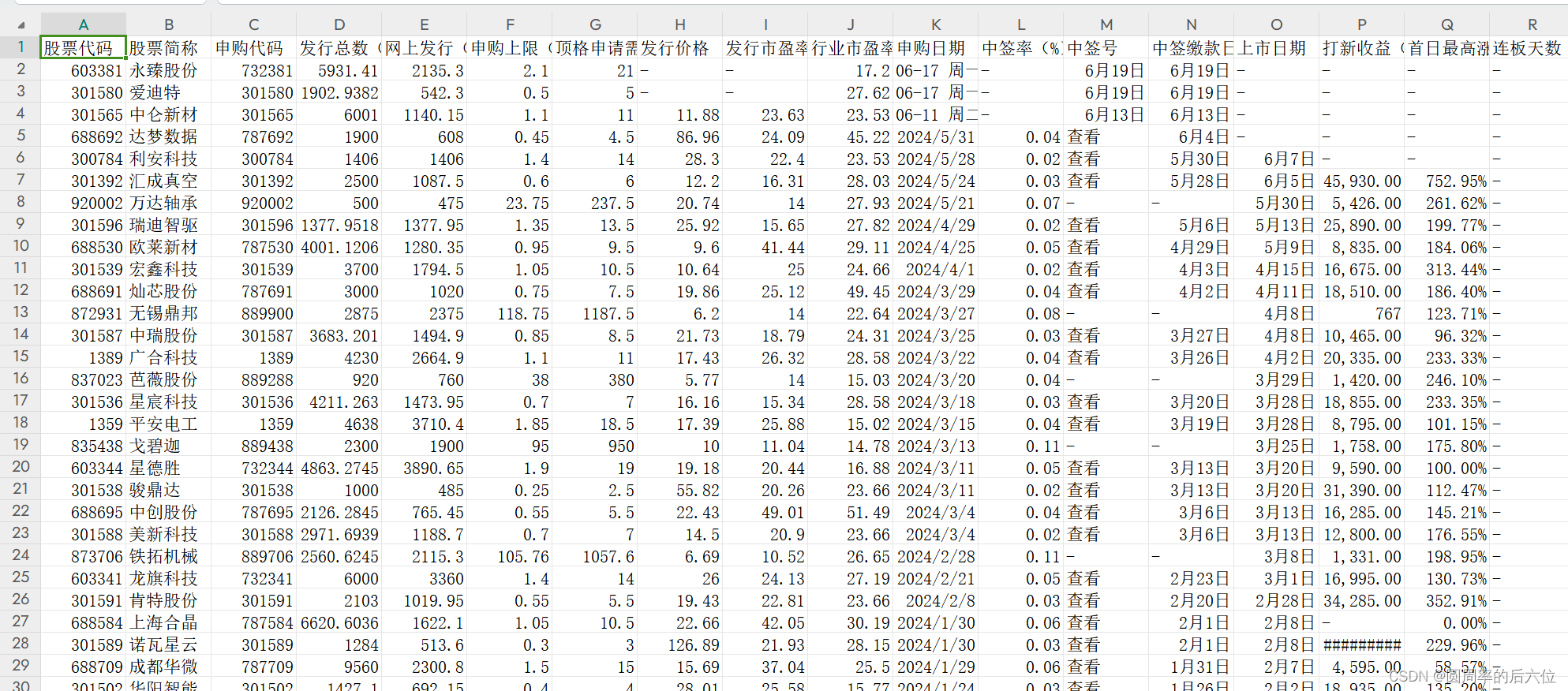
今天我们爬取同花顺这个网站的数据。url为:https://data.10jqka.com.cn/ipo/xgsgyzq/
话不多说直接上代码。有帮助到各位的给**点赞评论收藏**。
一 导入包
import time
import csv
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
二 url+requests请求
url = 'https://data.10jqka.com.cn/ipo/xgsgyzq/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
response.encoding = 'GBK' # utf-8
main_string = response.text三 获取字段名称
soup = BeautifulSoup(main_string, 'html') # html.parser
# 正则表达式匹配<a>标签内的文本
pattern = r'<a[^>]*>(.*?)</a>'
matches = re.findall(pattern, str(soup.find_all('th')[0:18]), re.DOTALL)
name_list = []
for match in matches:name_list.append(match)
cleaned_list = [item.strip() if i == 0 else item for i, item in enumerate(name_list)] # 有空字符 去掉
print(cleaned_list) ## 字段名称
字段名称:
[‘股票代码’, ‘股票简称’, ‘申购代码’, ‘发行总数(万股)’, ‘网上发行(万股)’, ‘申购上限(万股)’,‘顶格申请需配市值(万元)’, ‘发行价格’, ‘发行市盈率’, ‘行业市盈率’, ‘申购日期’, ‘中签率(%)’, ‘中签号’, ‘中签缴款日期’, ‘上市日期’, ‘打新收益(元)’, ‘首日最高涨幅’, ‘连板天数’]
四 提取数据
soup2 = BeautifulSoup(main_string, 'html')
# 提取所有td标签内的内容以及span标签的target属性
all_td_contents = [td.get_text(strip=True, separator=' ') for td in soup2.find_all('td')]
all_target_values = [span.get('target') for span in soup2.find_all('span', class_='jumpToclient1')]
data_list = [] ## 将数据添加到data_list里面 存在有问题的数据
for content in all_td_contents:data_list.append(content)
print(data_list)
## 将有问题的数据处理保留干净的数据
new_data = []
# 遍历原始数据列表
for item in data_list:# 检查元素是否包含中签结果的关键词if '网上定价发行摇号中签结果' in item:parts = item.split(' ')date_part = parts[0]new_data.append(date_part)else:# 如果不是中签结果,则直接添加到新列表中new_data.append(item)
print(new_data)
部分结果:
[‘603381’, ‘永臻股份’, ‘732381’, ‘5931.41’, ‘2135.3’, ‘2.10’, ‘21.00’, ‘-’, ‘-’, ‘17.20’, ‘06-17 周一’, ‘-’, ‘06-19’, ‘06-19’, ‘-’, ‘-’, ‘-’, ‘-’, ‘301580’, ‘爱迪特’, ‘301580’, ‘1902.9382’, ‘542.3’, ‘0.50’, ‘5.00’, ‘-’, ‘-’, ‘27.62’, ‘06-17 周一’, ‘-’, ‘06-19’, ‘06-19’, ‘-’, ‘-’, ‘-’, ‘-’]
五 建csv表以及将数据录入
original_list = new_data
## 创建csv表
fieldnames = ['股票代码', '股票简称', '申购代码', '发行总数(万股)', '网上发行(万股)', '申购上限(万股)','顶格申请需配市值(万元)', '发行价格', '发行市盈率', '行业市盈率', '申购日期', '中签率(%)', '中签号', '中签缴款日期', '上市日期', '打新收益(元)', '首日最高涨幅', '连板天数']
filename = r'E:\工作\数据收集\数据\股票数据爬取\股票数据爬取.csv'
with open(filename, 'w', newline='') as csvfile:writer = csv.DictWriter(csvfile, fieldnames=fieldnames)writer.writeheader() # 写入表头(字段名)
print(f"CSV文件 {filename} 已创建并写入数据。")
## 写入数据
with open(filename, 'a', newline='') as csvfile:writer = csv.writer(csvfile)# 使用列表推导式或循环来生成包含最多18个元素的子列表for i in range(0, len(original_list), 18):row = original_list[i:i + 18] # 取列表中的18个元素writer.writerow(row)
部分结果: