江苏集团网站建设如何写好一篇软文
文章目录
- 流程
- 我的
- 案例
- api调用
- llama.cpp
流程
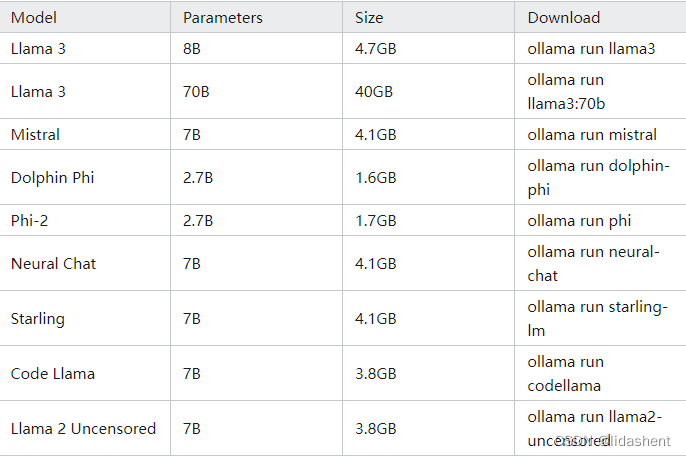
ollama支持可运行的模型,图片这里只是一部分而已,只需要下载下面的软件和模型文件,即可直接运行,而无需配置其他
模型文件下载地址
https://ollama.com/library
支持的部分模型,实际上更多,这里只是显示部分
登陆ollama官网
https://ollama.com/download
下载对应你电脑的软件即可
我的
因为我本地已经有一个gguf模型了,我的需求是将这个模型加载进ollama,然后运行
因此我在桌面建了一个txt文件
内容为:
FROM C:/Users/Administrator/.ollama/models/blobs/LexiFun-Llama-3-8B-Uncensored-V1_Q8_0.gguf# set prompt template
TEMPLATE """[INST] <<SYS>>{{ .System }}<</SYS>>{{ .Prompt }} [/INST]
"""# set parameters
PARAMETER stop "[INST]"
PARAMETER stop "[/INST]"
PARAMETER stop "<<SYS>>"
PARAMETER stop "<</SYS>>"# set system message
SYSTEM """
you are a good assistant
"""
意思是导入gguf模型文件,设定回答模板,为模型指定角色
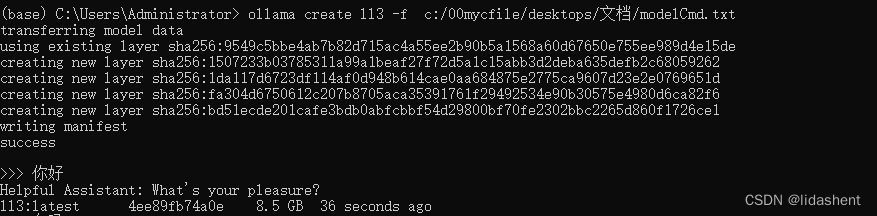
然后使用ollama根据这个text设置,将本地模型安装进ollama,为其指定名字为ll3
ollama create ll3 -f c:/00mycfile/desktops/文档/modelCmd.txt
后续如果要运行,不再需要重新安装,只需要
ollama run ll3
若是想要移除这个模型,将run改册成rm
案例
下载好后运行,
进入cmd窗口
查看版本
ollama -v
查看已经安装的模型
ollama list
ollama 还可以以 API 的方式调用,比如执行 ollama show --help 可以看到本地访问地址为:http://localhost:11434
https://ollama.com/library
打开llama的模型网站,我们随机选择一个模型,就可以看到

复制上面的命令
ollama run llama2-uncensored
输入cmd窗口,模型即可自动下载与安装,
然后使用
ollama list
查看即可
然后可以使用
ollama run 模型名
运行安装的模型
运行模型后的可用命令
显示帮助命令-/?
/?
Available Commands:
/set Set session variables
/show Show model information
/load Load a session or model
/save Save your current session
/bye Exit
/?, /help Help for a command
/? shortcuts Help for keyboard shortcuts
Use “”" to begin a multi-line message.
显示模型信息命令-/show
/show
Available Commands:
/show info Show details for this model
/show license Show model license
/show modelfile Show Modelfile for this model
/show parameters Show parameters for this model
/show system Show system message
/show template Show prompt template
显示模型详情命令-/show info
/show info
这样一个模型就运行在本地了
api调用
generate 接口
curl http://localhost:11434/api/generate -d '{"model": "gemma:2b","prompt":"你是一个好助手吗?"
}'
每个词将会分段返回
如果想要一次性返回可以加参数"stream": false
chat接口
curl http://localhost:11434/api/chat -d '{"model": "gemma:2b","messages": [{ "role": "user", "content": "你是好助手吗?" }]
}'
generate 是一次性生成的数据。chat 可以附加历史记录,多轮对话。
llama.cpp
llama.cpp的主要目标是能够在各种硬件上实现LLM(大型语言模型)推理,提供1.5位、2位、3位、4位、5位、6位和8位整数量化,用来减小内存使用和加快推理速度.当然精度会变差,其作用是给模型瘦身
https://github.com/ggerganov/llama.cpp/releases
下载这个工具,根据需要下载
在模型瘦身之前,目录结构如下
这只是一个案例参考,模型文件根据你的需要会有不同
gguf是一个包文件,打包了所有运行模型需要的配置以及参数,方便快速部署,而不是需要多个软件分别加载
将其打包为gguf代码如下,如果已经有gguf文件,则忽略
python .\convert.py C:\llama-2-13b-chat
进行精度转换,32位转4位瘦身,可以将原本16g的gguf模型缩小为4g左右
quantize.exe C:\ggml-model-f32.gguf C:\ggml-model-Q4_0.gguf Q4_0
然后运行这个gguf如同之前一样就可以了