如何做动态网站html广州seo排名收费
雪花算法原理
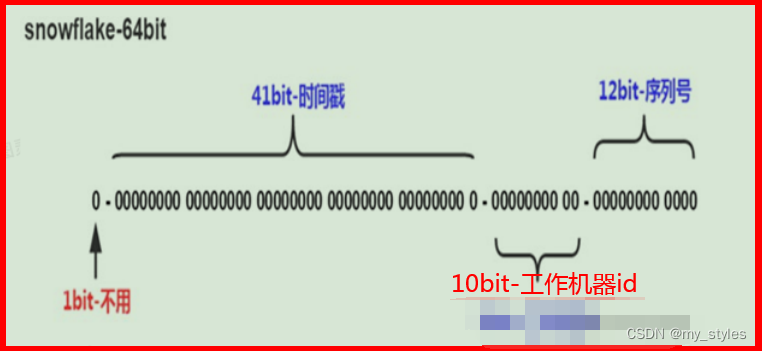
第1位符号位固定为0,41位时间戳,10位workId,12位序列号,位数可以有不同实现。
优点:每个毫秒值包含的ID值很多,不够可以变动位数来增加,性能佳(依赖workId的实现)。时间戳值在高位,中间是固定的机器码,自增的序列在低位,整个ID是趋势递增的。能够根据业务场景数据库节点布置灵活调整bit位划分,灵活度高。
缺点:强依赖于机器时钟,如果时钟回拨,会导致重复的ID生成,所以一般基于此的算法发现时钟回拨,都会抛异常处理,阻止id生成,这可能导致服务不可用。
SOA、分布式、微服务之间有什么关系和区别
1.分布式架构是指将单体架构中的各个部分拆分,然后部署不同的机器或进程中去,SOA和微服务基本上都是分布式架构的。
2. SOA是一种面向服务的架构,系统的所有服务都注册在总线上,当调用服务时,从总线上查找服务信息,然后调用。
3.微服务是-种更彻底的面向服务的架构,将系统中各个功能个体抽成一个个小的应用程序,基本保持一个应用对应的一个服务的架构。
零拷⻉是什么
零拷贝指的是,应用程序在需要把内核中的一块区域数据转移到另外-块内核区域去时,不需要经过先复制到用户空间,再转移到目标内核区域去了,而直接实现转移。
深拷⻉和浅拷⻉
深拷贝和浅拷贝就是指对象的拷贝,一个对象中存在两种类型的属性,一种是基本数据类型,一种是实例对象的引用。
1.浅拷贝是指,只会拷贝基本数据类型的值,以及实例对象的引用地址,并不会复制一份引用地址所指向的对象,也就是浅拷贝出来的对象,内部的类属性指向的是同一个对象
2.深拷贝是指,既会拷贝基本数据类型的值,也会针对实例对象的引用地址所指向的对象进行复制,深拷贝出来的对象,内部的属性指向的不是同一个对象。
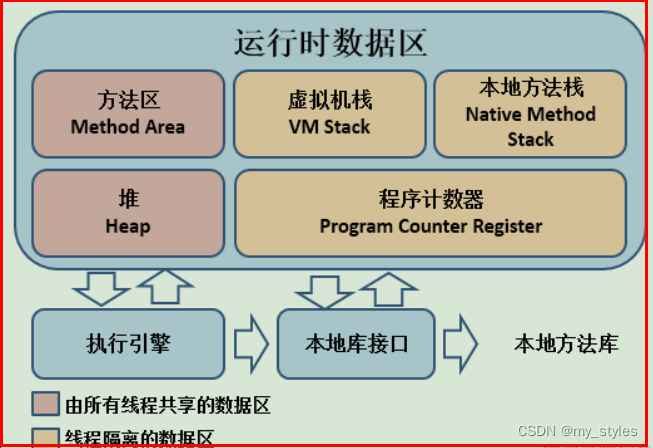
JVM中哪些是线程共享区
堆区和方法区是所有线程共享的,栈、本地方法栈、程序计数器是每个线程独有的
常⻅的缓存淘汰算法
1、FIFO (First In First Out,先进先出),根据缓存被存储的时间,离当前最远的数据优先被淘汰;
2、LRU (LeastRecentlyUsed,最近最少使用),根据最近被使用的时间,离当前最远的数据优先被淘汰;
3、LFU (LeastFrequentlyUsed,最不经常使用),在一段时间内,缓存数据被使用次数最少的会被淘汰。
如何保证消息的⾼效读写?
零拷贝: kafka和RocketMQ都是 通过零拷贝技术来优化文件读写。
传统文件复制方式:需要对文件 在内存中进行四次拷贝。
零拷贝:有两种方式,mmap和transfile, Java当中对零拷贝进行了封装,Mmap方 式通过MappedByteBuffer对象进行操作,而transfile通过FileChannel来进行 操作。Mmap适合比较小的文件,通常文件大小不要超过1.5G ~2G之间。Transfile没有 文件大小限制。RocketMQ当中使用Mmap方式来对他的文件进行读写。
在kafka当中,他的index日志文件也是通过mmap的方式来读写的。在其他日志文件当中,并没有使用零拷贝的方式。Kafka使用transfile方 式将硬盘数据加载到网卡。
JVM参数有哪些
JVM参数大致可以分为三类:
1.标注指令: - 开头,这些是所有的HotSpot都支持的参数。可以用java -help打印出来。
2.非标准指令: -X开头, 这些指令通常是跟特定的HotSpot版本对应的。可以用java -X打印出来。
3.不稳定参数: -XX开头,这一类参数是跟特定HotSpot版本对应的,并且变化非常大。
谈谈你对AQS的理解,AQS如何实现可重⼊锁?
1. AQS是一个JAVA线程同步的框架。是JDK中很多锁工具的核心实现框架。
2.在AQS中,维护了一个信号量state和一个线程组成的双向链表队列。其中,这个线程队列,就是用来给线程排队的,而state就像是 一个红绿灯,用来控制线程排队或者放行的。在不同的场景下,有不用的意义。
3.在可重入锁这个场景下,state就用来表示加锁的次数。0标识无锁,每加一次锁,state就加1。释放锁state就减1。
什么是MVCC
多版本并发控制:读取数据时通过一种类似快照的方式将数据保存下来,这样读锁就和写锁不冲突了,不同的事务session会看到自己特定版本的数据,版本链MVCC只在READ COMMITTED和REPEATABLE READ两个隔离级别下工作。其他两个隔离级别够和MVCC不兼容,因为READ UNCOMMITTED总是读取最新的数据行,而不是符合当前事务版本的数据行。而SERIAL IZABL E则会对所有读取的行都加锁。
聚簇索引记录中有两个必要的隐藏列:
trx_id:用来存储每次对某条聚簇索引记录进行修改的时候的事务id。
roll_pointer: 每次对哪条聚簇索引记录有修改的时候,都会把老版本写入undo日志中。这个roll_pointer就是存了一个指针,它指向这条聚簇索引记录的上一个版本的位置,通过它来获得上一个版本的记录信息。(注意插入操作的undo日志没有这个属性,因为它没有老版本)
已提交读和可重复读的区别就在于它们生成ReadView的策略不同。
开始事务时创建readview, readView维护 当前活动的事务id,即未提交的事务id,排序生成一个数组访问数据,获取数据中的事务id (获取的是事务id最大的记录),对比readview:
如果在readview的左边(比readview都小) ,可以访问(在左边意味着该事务已经提交)
如果在readview的右边(比readview都大) 或者就在readview中,不可以访问,获取roll pointer,取上一版本重新对比(在右边意味着,该事务在readview生成之后出现,在readview中 意味着该事务还未提交)
已提交读隔离级别下的事务在每次查询的开始都会生成一个独立的ReadView,而可重复读隔离级别则在第一次读的时候生成个ReadView, 之后的读都复用之前的ReadView。 学沉间
这就是Mysql的MVCC,通过版本链,实现多版本,可并发读-写,写-读。通过ReadView生成策略的不同实现不同的隔离级别。