wordpress调用字段网站优化关键词
Java集合
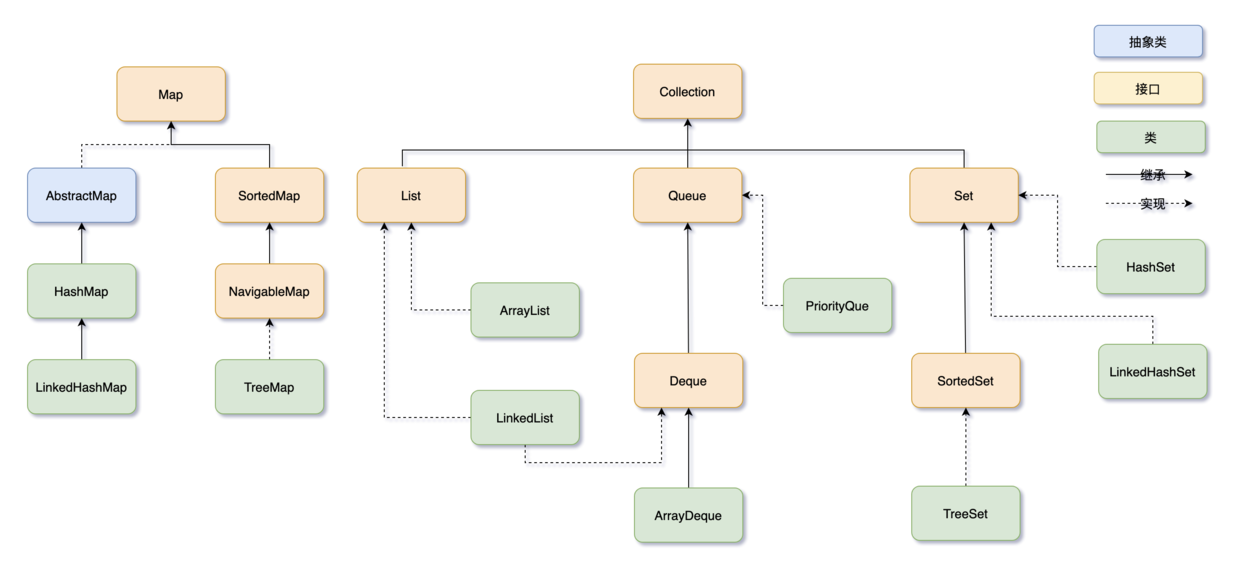
集合底层框架总结
List
代表的有序,可重复的集合。
-
ArrayList -- 数组 -- 把他想象成C++中的Vector就可以,当数组空间不够的时候,会自动扩容。 -- 线程不安全
-
LinkedList -- 双向链表 -- 可以将他理解成一个链表,不支持随机存取,但是增加删除特别方便。
-
Vector -- 数组 -- 线程安全
comparable 和 Comparator 的区别
comparable 是Java中的一个接口,定义在lang包下,他的比较方法是comparableTo。他是一个Java 中内置的比较方法,不是独立的。例如我可以根据年龄,来为对象排序。这个comparableTo 是写在类之中的。
class Person implements Comparable<Person> {private String name;private int age;
public Person(String name, int age) {this.name = name;this.age = age;}
// Implementing compareTo method of Comparable interface@Overridepublic int compareTo(Person otherPerson) {return Integer.compare(this.age, otherPerson.age);}
}
public class Main {public static void main(String[] args) {List<Person> people = new ArrayList<>();people.add(new Person("Alice", 30));people.add(new Person("Bob", 25));people.add(new Person("Charlie", 35));
Collections.sort(people);
for (Person person : people) {System.out.println(person);}}
}Comparator 是一个独立的接口,定义在Util 包下。他如果对对象进行排序,需要重写 compare 方法,然后在外部对具体如何排序进行书写,也正因为写在外部,所以可以有多种排序方式,与之相反的Compareable 接口由于在类内部,所以只有一种排序方式,不可改变。
class Person implements Comparable<Person> {private String name;private int age;
public Person(String name, int age) {this.name = name;this.age = age;}
// Implementing compareTo method of Comparable interface@Overridepublic int compareTo(Person otherPerson) {return Integer.compare(this.age, otherPerson.age);}
// Getter methods for name and agepublic String getName() {return name;}
public int getAge() {return age;}
// toString method for printing Person objects@Overridepublic String toString() {return name + " - " + age;}
}
public class Main {public static void main(String[] args) {List<Person> people = new ArrayList<>();people.add(new Person("Alice", 30));people.add(new Person("Bob", 25));people.add(new Person("Charlie", 35));
Collections.sort(people);
for (Person person : people) {System.out.println(person);}}
}ArrayList如何序列化
transient 修饰 存储元素的elementData,目的是不让被修饰的成员属性序列化。
那为什么不可以直接序列化 ArrayList?
因为ArrayList的空间可能是100,但是只有60个有元素,那么就极大的浪费空间,且效率低下。
如何序列化
通过的是readObject和writeObject方法,实际使用的是流的方式。
ObjectOutputStream和ObjectInputStream来进行序列化和反序列化。
ArrayList的扩容机制
首先,我们在创建ArrayList时,我们可以指定ArrayList的初始容量,但随着add()方法,不断往ArrayList添加元素,这个时候ArrayList的容量满了,我们需要对 ArrayList 进行扩容。
流程为:创建了一个当前数组容量*1.5大小的 ArrayList,然后将原来的数组中的元素利用Arrays.copyOf() 方法放入 新数组中。再将准备新加入的元素加入新数组中。
图示:
堆栈过程图示: add(element) └── if (size == elementData.length) // 判断是否需要扩容├── grow(minCapacity) // 扩容│ └── newCapacity = oldCapacity + (oldCapacity >> 1) // 计算新的数组容量│ └── Arrays.copyOf(elementData, newCapacity) // 创建新的数组├── elementData[size++] = element; // 添加新元素└── return true; // 添加成功
LinkedList 为什么不能实现RandomAccess接口
RandomAccess 是一个标记接口,用来表明实现该接口的类支持随机访问(即可以通过索引快速访问元素)。由于 LinkedList 底层数据结构是链表,内存地址不连续,只能通过指针来定位,不支持随机快速访问,所以不能实现 RandomAccess 接口。
Queue
-
PriorityQueue -- 数组来实现二叉堆
-
ArrayQueue -- 数组 + 双指针
Set
代表的有序,不可重复的集合。
-
HashSet(无序,唯一) -- 基于 HashMap 实现,底层是哈希表
-
LinkedHashSet(HashSet的子类,有序) -- 基于LinkedHashMap实现,底层是链表 + 哈希表
-
TreeSet (有序,唯一)-- 红黑树
Map
以键值对方式存储。代表的是键值对的集合。
-
HashMap -- JDK1.8 前:数组+链表。JDK1.8后:如果链表阈值大于默认值(8),会将链表转换为红黑树,但转换前会先判断数组大小是否小于64,如果小于的话,优先数组扩容。总结:数组+链表或红黑树。
-
LinkHashMap -- 数组+链表或红黑树。不同的是,在HashMap基础上,增加了一条双向链表,可以保证顺序与插入顺序一致。
-
TreeMap -- 红黑树。 因为TreeMap还实现了 SortedMap 和 NavigableMap 接口,所以会比 HashMap 多了搜寻和排序的功能。可以自定义排序规则。
HashMap详解
数据结构:
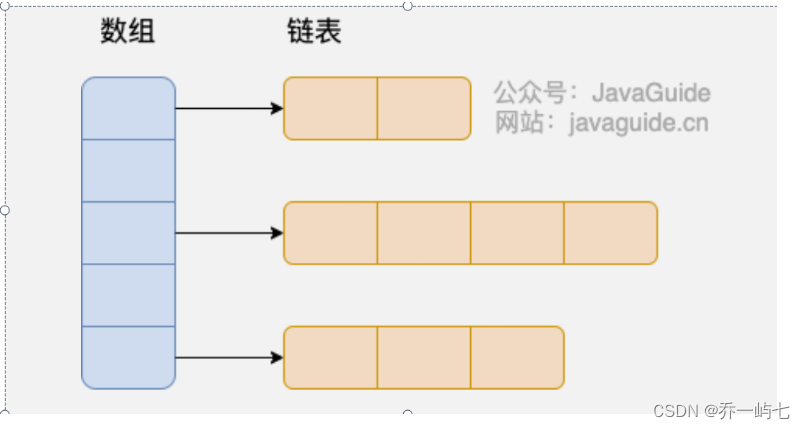
HashMap -- JDK1.8 前:数组+链表。JDK1.8后:如果链表阈值大于默认值(8),会将链表转换为红黑树,但转换前会先判断数组大小是否小于64,如果小于的话,优先数组扩容。总结:数组+链表或红黑树。使用了拉链法来解决的哈希冲突。
JDK1.8 前:
JDK1.8后: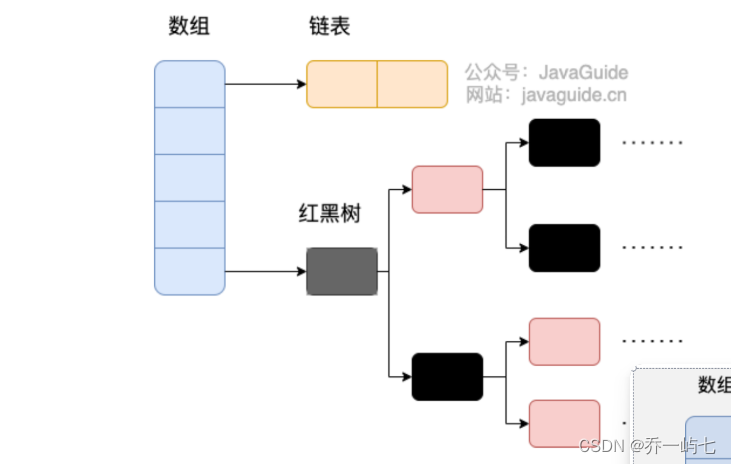
线程安全:
非线程安全,但是HashTable是线程安全的。因为HashTable中的方法基本上都经过 synchronized 修饰过的。
初始容量和扩容机制:
HashMap如果未指定初始大小,那么默认初始容量大小是16,且每次扩容都是之前的二倍。如果给定初始容量大小 n,那么容量为给定大小的2 的n次幂。
而HashTable 如果未指定初始大小,那么默认初始容量大小是11,且每次扩容都是之前的 2n + 1 。如果指定初始容量大小,那么容量直接就是给定的大小。
为什么 HashMap 的⻓度为什么是 2 的幂次方
因为 Hash 值范围非常大,但是空间是不能容得下这么多哈希值的,所以需要 Hash值 数组长度进行取模运算。也就是 Hash % length ,但是这个这个值是与 Hash & (length - 1 )是相等的。
举个例子如果 数组长度是 16,hash值是 10101 ,hash & (ength - 1) = 10101 & 1111。这样可以看到 hash 值的后四位就可以被用来计算数组的索引。
-
会方便计算,也可以使其分布更加均匀。(因为与 hash 值有关)。
-
并且如果数组长度是2 的幂次方,就可以用 与运算。也会使效率更高。
如果初始化一个HashMap长度为17,还是会变成 32 容量。
HashMap 的 put 流程
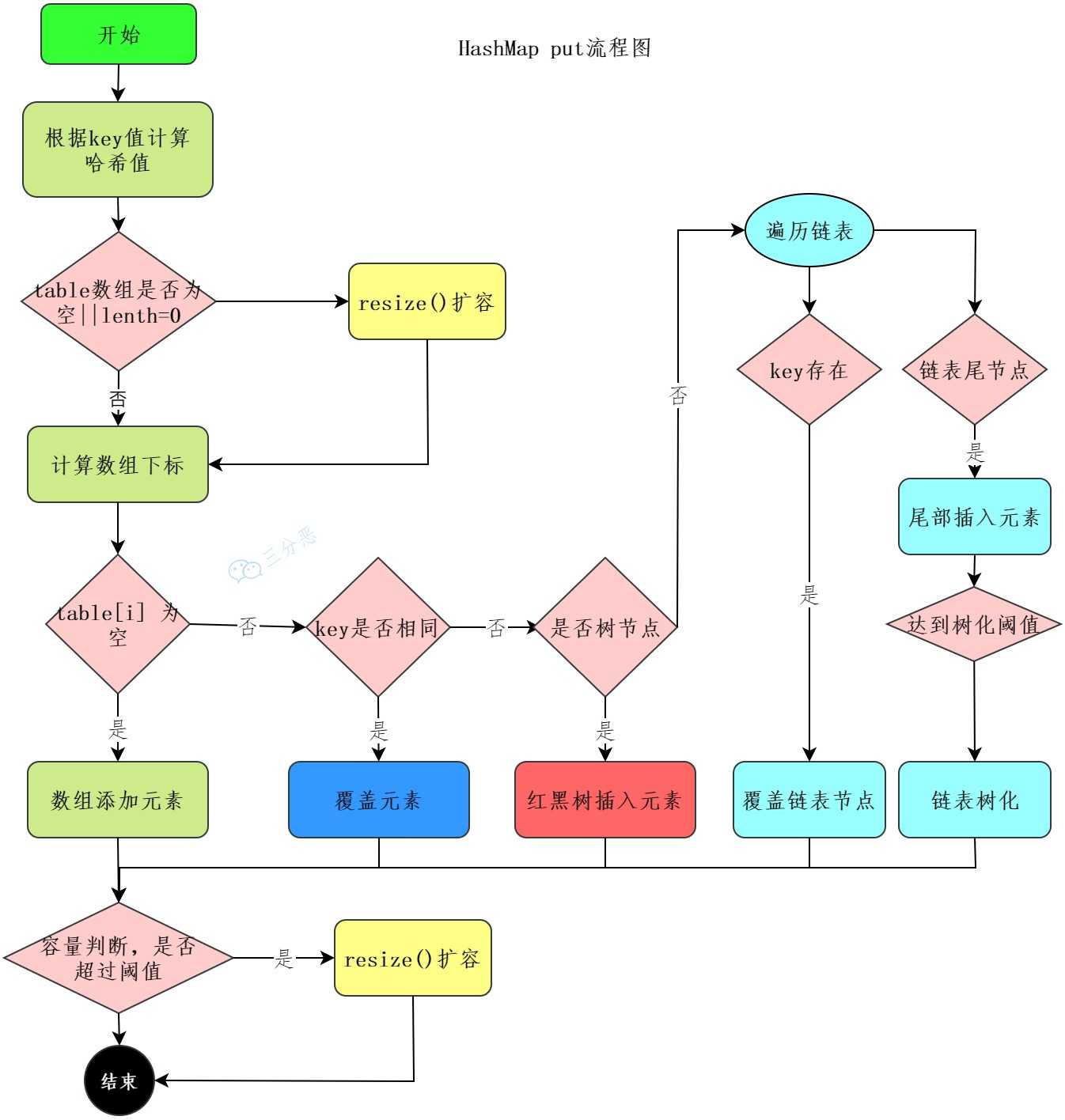
先利用 hashcode 获取哈希值,然后根据哈希值和数组长度算出键值对在数组中的索引。如果当前数组的桶为空,直接添加。如果不为空,判断key 相同与否,如果相同,则覆盖,不相同的话遍历链表或者遍历树。在链表中,如果 key 相同,则覆盖,如果key 不存在,添加进链表中,作为尾节点,并判断如果超过链表阈值,则转换为红黑树。
HashMap的查询,删除的时间复杂度
HashMap可以直接根据哈希码来确认数组下标,所以查询和删除的时间复杂度都是 o(1) 。但是如果发生哈希冲突的话,链表还未转换成红黑树,时间复杂度就变成了o(n),n是链表长度,如果转变成了红黑树,时间复杂度变成了 o(logn).
ConcurrentHashMap
从上文已知,HashMap 是线程不安全的,那如果我们想用线程安全的哈希表,就可以用 ConcurrentHashMap。
在Jdk 1.8 之前,ConcurrentHashMap 的底层数据结构是 分段数组 + 链表的形式。每个分段可以独立锁定,当需要读取数据的时候,不需要锁震整个数组,只需要锁定当前数据所在的段的段就可以。可以提高并发的性能。当一个线程锁上一个数据段的时候,其他的数据段仍然可以被另外的线程读取。 如果有些方法需要跨段,那么就可以按顺序锁住所有的段,然后再按顺序释放就可以。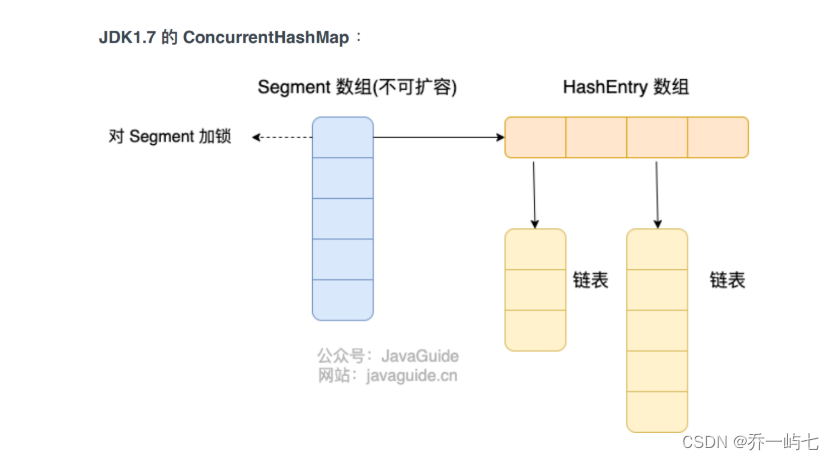
Segment 数组中的每个元素包含⼀个 HashEntry 数组,每个 HashEntry 数组属于链表结构。
这样就可以保证线程安全。
JDK1.8之后,ConcurrentHashMap 取消了 Segment 分段数组,只保留了一大个数组,也就是 table 数组。取而代之,保证线程安全用的是CAS 和 synchronized 锁,避免不必要的锁的开销。另一个变化是像HashMap一样增加了红黑树,防止链表长度过长。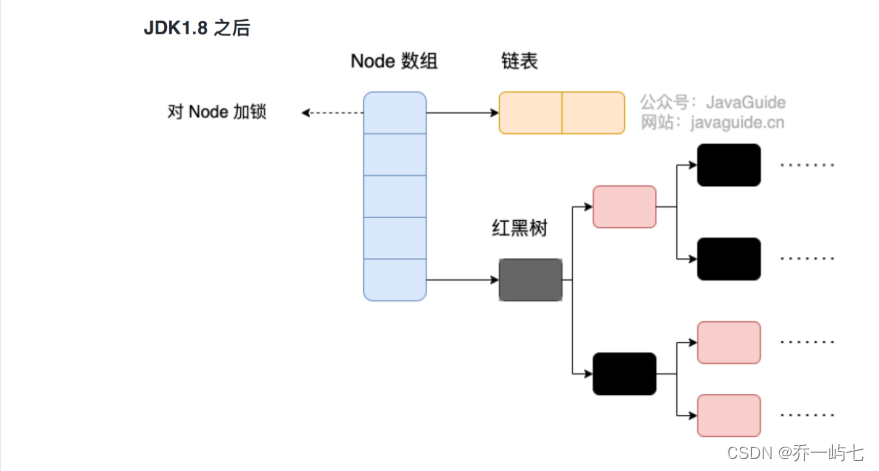
JDK 1.8 最大并发数是Node数组的大小,而Jdk1.7并发数是 Segment 的数量。
ConcurrentHashMap 和 HashTable 的区别
首先,他们俩都是线程安全的,但是数据结构不同。
HashTable 的数据结构利用了 数组加链表,ConcurrentHashMap 的数据结构参考上文。
其次,实现线程安全的方式也不同,HashTable使⽤ synchronized 来保证线程安全,同一时段,只能一个线程访问,效率低下。