网站硬件建设方案成都百度推广代理公司
注意力机制
- 为什么需要注意力机制
- attention机制的架构总体设计
- 一、attention本身实现
- 评分函数
- attention在网络模型的应用-Bahdanau 注意力
- 加性注意力代码实现
为什么需要注意力机制

这是一个普通的seq2seq结构,用以实现机器对话,Encoder需要把一个输入的一个句子转化为一个最终的输出,上下文context vector,然后在Decoder中使用,但这里有些问题:
- 如果句子很长,这个向量很难包含sequence中最早输入的哪些词的信息,那么decoder的处理必然也缺失了这一部分。
- 对话的过程中,大部分情况下decoder第一个的输出应该关心的权重更应该是encoder的前半部分的输入,比如这里Yes,其实应该是对are you这样一个疑问的输出,但是这就要求decoder的预测的时候有区别的针对sequence的输入做输出,现在这个结构没办法实现这个功能。
你可能会想到LSTM或者GRU也是有memory记忆功能的,解决方案:
LSTM中的memory没有办法很大,假设它的memory的大小时K的话,就需要有一个K*K的矩阵,如果太大的memory,不仅计算量大,参数太多还会容易过拟合,因此不可行
attention机制就是用来解决这个问题,attention里面memory增加的话,参数并不会增加,一句话总结就是attention就是来解决长输入在decoder时,能够找到应该关注的输入部分的问题,它最初时从机器翻译发展的,后续也扩展到了其他领域
attention机制的架构总体设计
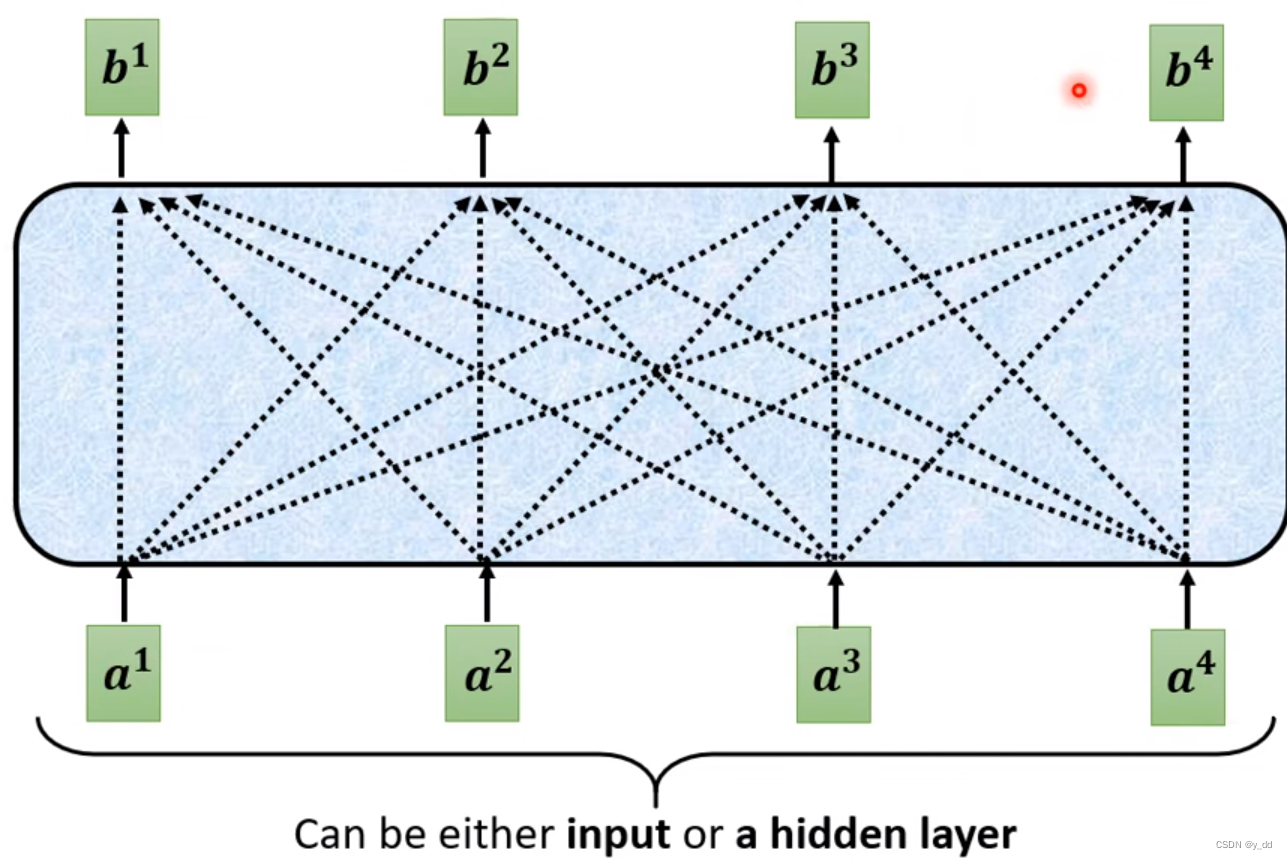
这就是总体的架构设计,输入a1…an,输出b1…bn 对应,注意这里的b考虑了所有的输入,这个输出带有对于每个输入的attention score,score越大,证明这个输入越重要,a在这里可以是输入,也可以是输入解码器后hidden layer的输出,那么中间蓝色框部分就是attention主体实现,它用来生成的b1到bn 。
举个例子:输入are you free tomorrow? 输出的时候Yes更关注的是are you,那这个的attention score就需要高一些
普通的seq2seq结构

带有注意力的seq2seq
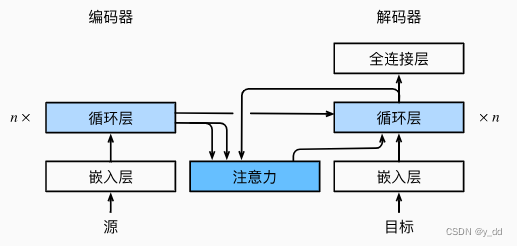
在普通的seq2seq相比,解码器使用的上下文变量C’不再仅仅是编码器的输出,而是 注意力的输出
与普通的seq2seq模型对比下,带有注意力模型的修改就分为了两部分
1.attention本身的实现
2.attention应用到模型部分
以下详述这了两部分
一、attention本身实现
先不介绍内部的一些数学处理,attention的输出实际上是对某种输入的选择倾向
输入就是要被选择的数据和对应的查询线索
输出对要选择数据的权重
举个例子
输入:the dog is running across the grass
翻译:这个小狗正在穿越草地
解码翻译这 个 小 狗 这些词的时候,注意力应该放在the dog上,这时候我们给与the dog这些词更多的权重,这时候对于输入可能的权重就是0.5 0.5 0 0 0 0
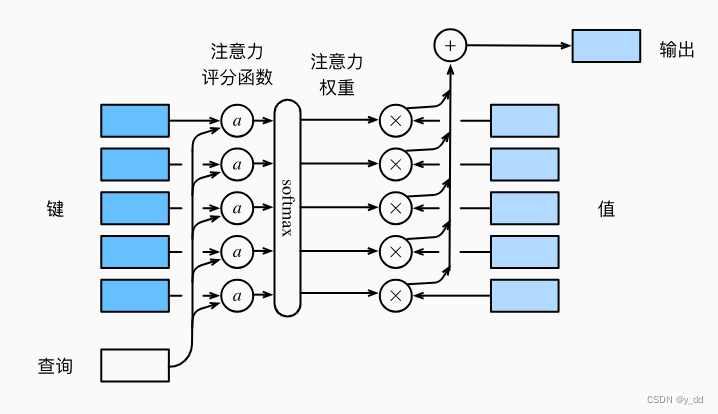
在数学模型方面,
键key
查询Query
值 Value
要实现的是根据键和查询生成的线索,去计算对于值Value的倾向选择,数学表达是这样的:
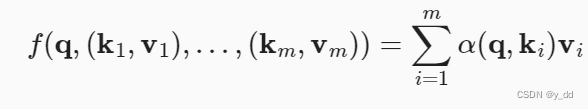
这里的a(q, ki) 一般是经过一个评分函数映射成标量和然后一个softmax操作
这里可以形象的理解一下,比如下面三组数据:
| id | 体重->Q | 身高->K | 年龄-> V |
|---|---|---|---|
| 1 | 50 | 160 | 50 |
| 2 | 65 | 165 | 23 |
| 3 | 60 | 175 | 21 |
当输入体重K 63, 身高V 170,问现在的年龄大概是多少呢?
看到表中的信息,人脑会自然猜测年龄在23和21之间,也就是在id 2和3上权重比较高,0.6* 23 +0.4* 21,这个也接近于注意力的实质,其实是根据Q和V 做评分,用以对V加权取值,这些权重值,就是注意力。
a(q, k1) v1+ a(q, k2)v2
评分函数
评分函数实际有很多种,tanh, 经过一个线性变换,或者sin cos 、加 等等,目前业内没有最好的实践
attention在网络模型的应用-Bahdanau 注意力
很多的论文都涉及注意力的使用,这块的依据是比较早和出名的Bahdanau注意力讲解。
上文seq2se模型中讲过解码器的输入是编码器的输出(上下文变量)以及解码器输入,而在有注意力的网络模型中,这个上下文变成了注意力的输出,解码器示意:

其中的at,i 就是注意力权重的输出
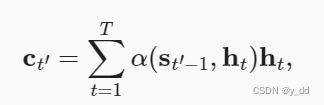
时间步t’-1 解码器的隐状态是St’-1,也是所谓的查询
ht编码器隐状态,是键也是值
加性注意力代码实现
class AdditiveAttention(nn.Module):"""加性注意力实现"""def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):super(AdditiveAttention, self).__init__(**kwargs)self.W_k = nn.Linear(key_size, num_hiddens, bias=False)self.W_q = nn.Linear(query_size, num_hiddens, bias=False)self.w_v = nn.Linear(num_hiddens, 1, bias=False)self.dropout = nn.Dropout(dropout)def forward(self, queries, keys, values, valid_lens):queries, keys = self.W_q(queries), self.W_k(keys)# 在维度扩展后,# queries的形状:(batch_size,查询的个数,1,num_hidden)# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)# 使用广播方式进行求和features = queries.unsqueeze(2) + keys.unsqueeze(1)features = torch.tanh(features)# self.w_v仅有一个输出,因此从形状中移除最后那个维度。# scores的形状:(batch_size,查询的个数,“键-值”对的个数)scores = self.w_v(features).squeeze(-1)# 这部分主要是为了遮蔽填充项,理解注意力上的时候可以先忽略它self.attention_weights = masked_softmax(scores, valid_lens)# values的形状:(batch_size,“键-值”对的个数,值的维度)return torch.bmm(self.dropout(self.attention_weights), values)