bootstarp做的网站站内营销推广方案
文章目录
- 前言
- 一、VSCode+Python环境搭建
- 二、爬虫案例一
- 1、爬取第一页数据
- 2、爬取所有页数据
- 3、格式化html数据
- 4、导出excel文件
前言
实战是最好的老师,直接案例操作,快速上手。
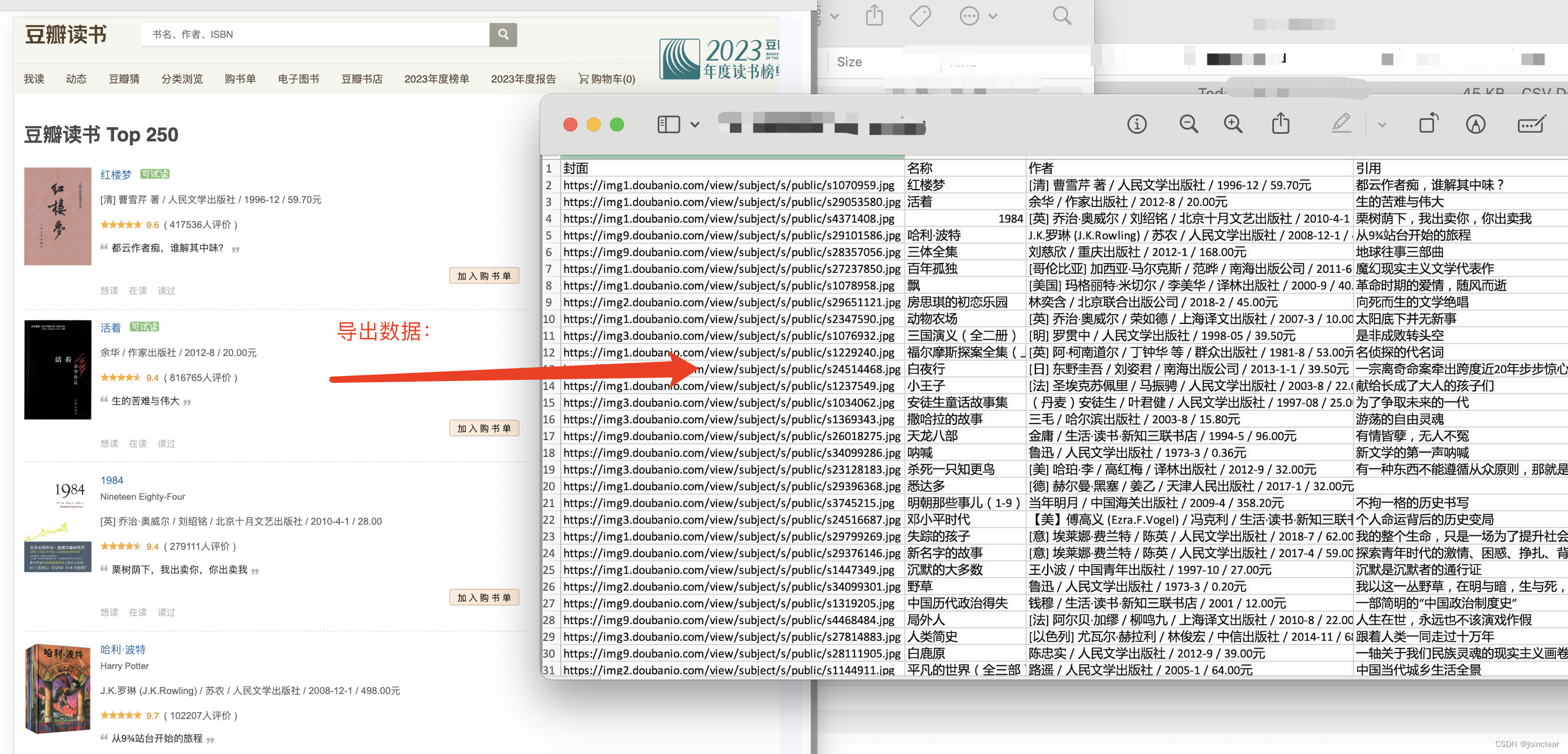
案例一,爬取数据,最终效果图:
一、VSCode+Python环境搭建
开发环境:MacBook Pro + VSCode + Python。
打开最新版VSCode,安装Python开发环境,快捷键:cmd+shift+x。
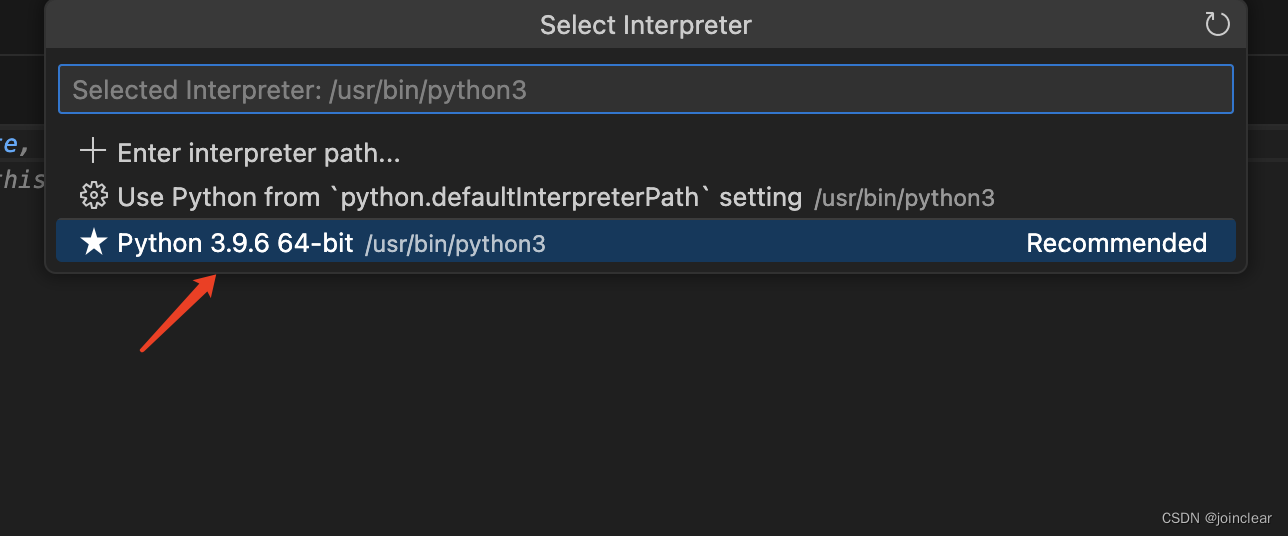
选择Python解释器,快捷键:cmd+shift+p。输入:Python: Select Interpreter,选择解释器。
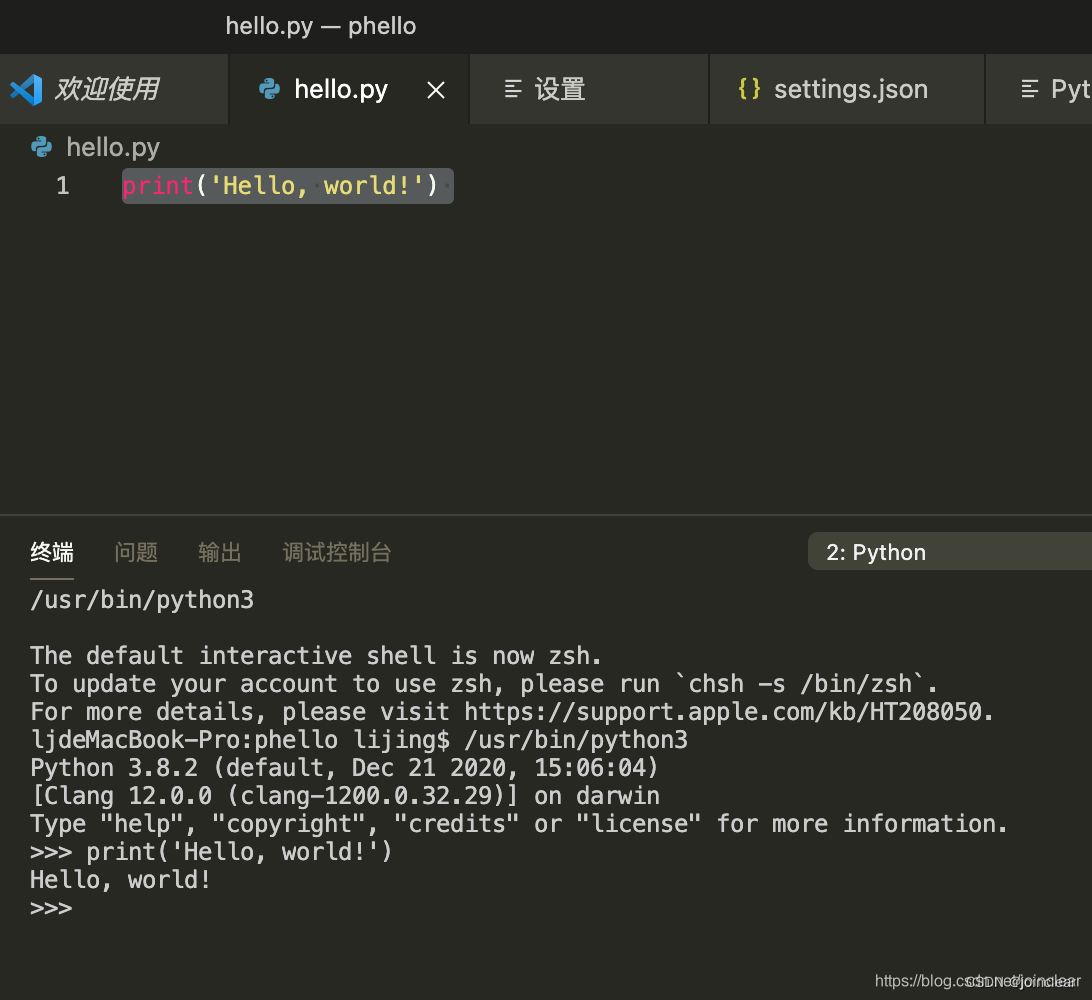
写“hello world”。
新建文件,输入print(‘hello world~’),另存为hello.py文件。
shift+enter 运行:
二、爬虫案例一
以爬取“豆瓣读书TOP250”的书籍为案例。
网址链接:https://book.douban.com/top250?start=0
1、爬取第一页数据
代码如下:
import requests
def askUrl(url):head = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.15"}html="" r = requests.get(url, headers = head) html = r.text print(html) return htmlif __name__ == "__main__": askUrl("https://book.douban.com/top250?start=0")
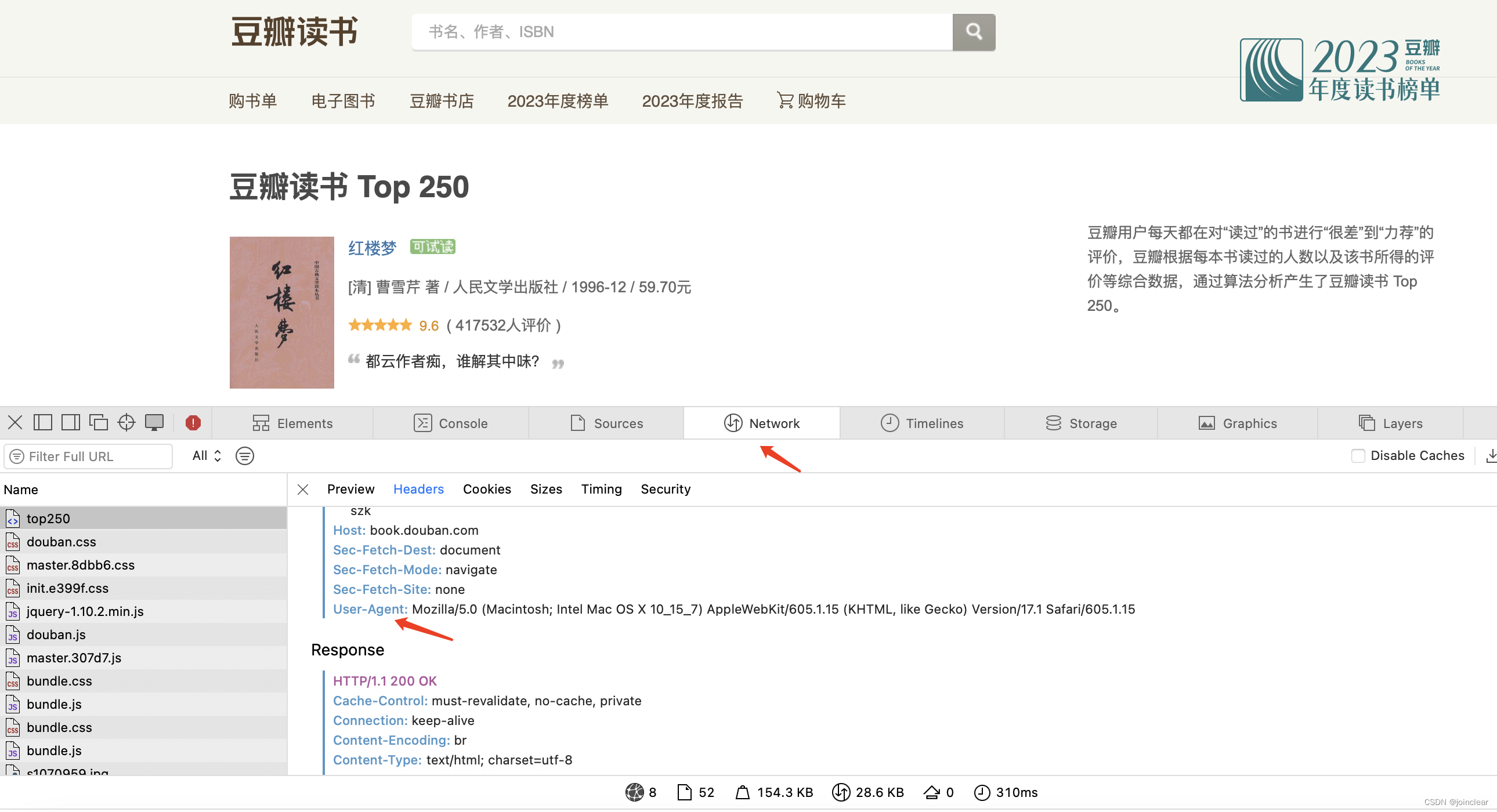
head->User-Agent的值可以从这个地方获取:
如果import requests报错,使用pip3 install requests安装。
运行之后,结果如下:
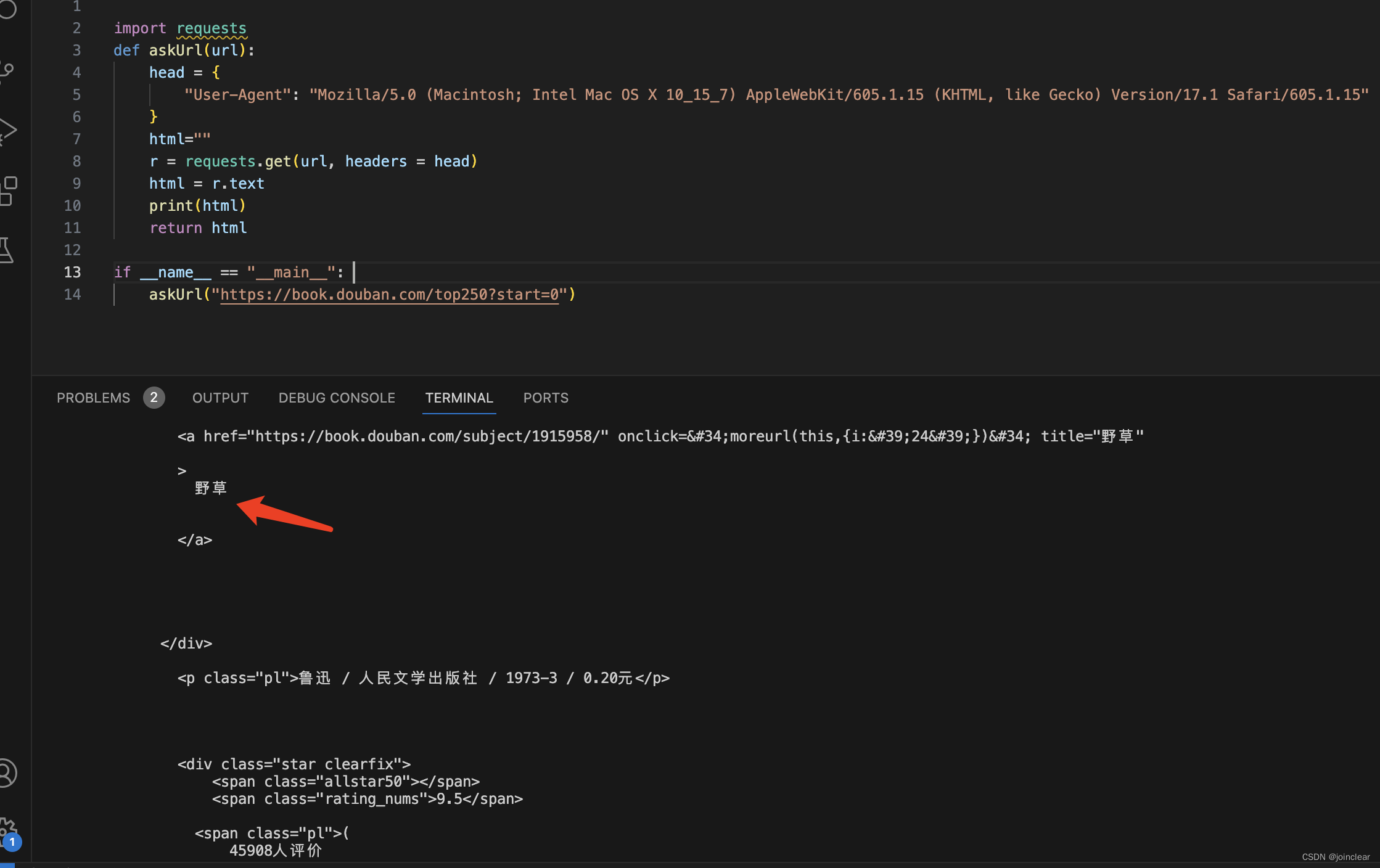
第一页25个,都以html的形式显示了出来,第25个为书籍《野草》。
2、爬取所有页数据
代码如下:
import requests
def askUrl(url):head = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.15"}r = requests.get(url, headers = head)html = r.textprint(html)def getData(baseurl):for i in range(0, 10):url = baseurl + str(i * 25)html = askUrl(url)if __name__ == "__main__": baseurl = "https://book.douban.com/top250?start="getData(baseurl)运行之后,结果如下:
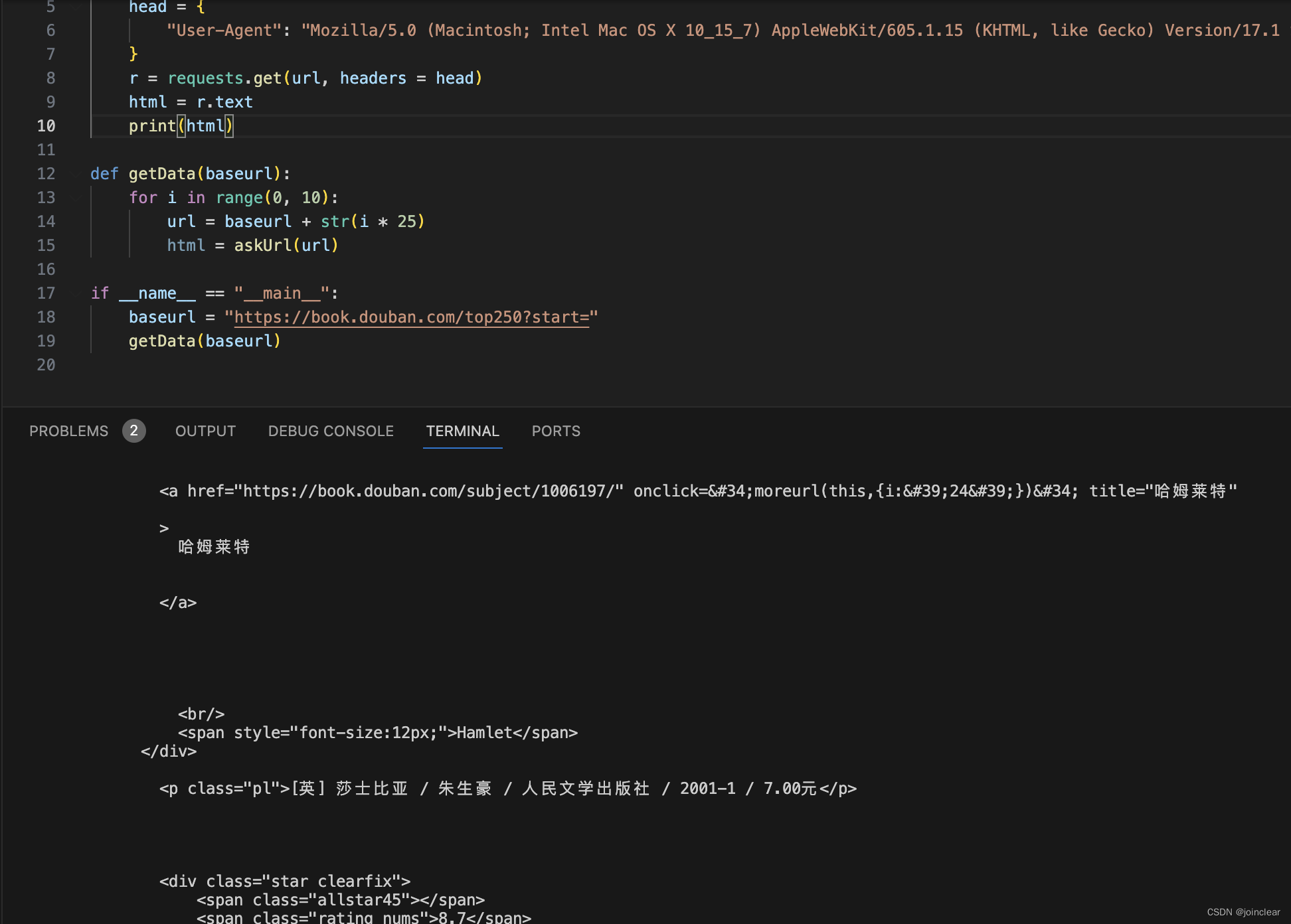
最后一页,最后一个,为书籍《哈姆莱特》。
3、格式化html数据
上面1和2,只是输出了html源码,现在按自己需要的几个字段进行格式化。
分别取这4个字段:封面图、书籍名称、作者(出版社、价格等)、引用。
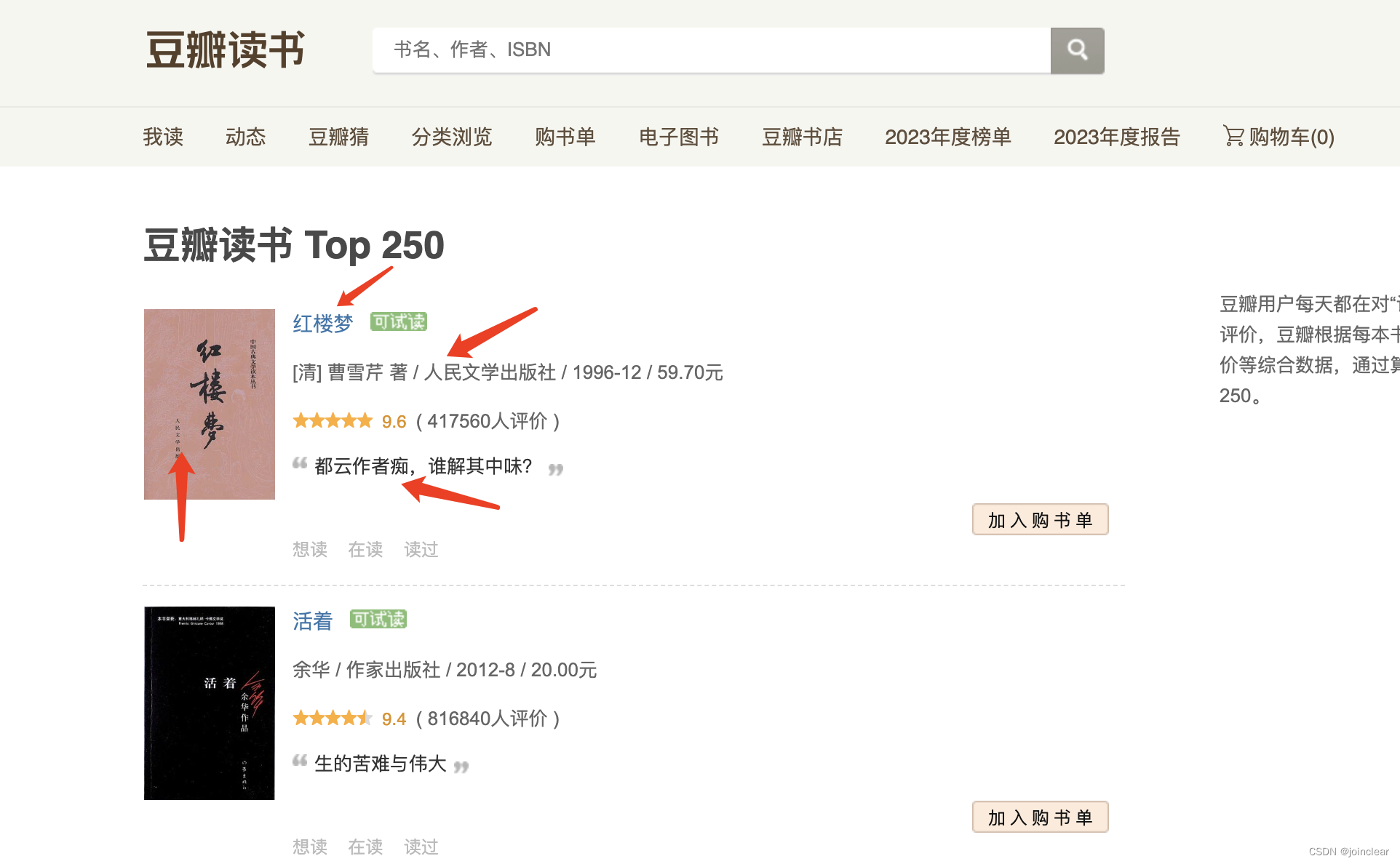
这里使用lxml库,解析html。
# 导入lxml库子模块etree
from lxml import etree
格式化代码如下:
import requests
from lxml import etree def askUrl(url):head = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.15"}html="" r = requests.get(url, headers = head) html = r.text parse = etree.HTML(html) # 数据# all_tr = parse.xpath('/html[@class="ua-mac ua-webkit book-new-nav"]/body/div[@id="wrapper"]/div[@id="content"]/div[@class="grid-16-8 clearfix"]/div[@class="article"]/div[@class="indent"]/table')all_tr = parse.xpath('//*[@id="content"]/div/div[1]/div/table')for tr in all_tr:tr_data = {'vover': ''.join(tr.xpath('./tr/td[1]/a/img/@src')).strip(), # 封面图'name': ''.join(tr.xpath('./tr/td[2]/div[@class="pl2"]/a/text()')).strip(), # 书名'author': ''.join(tr.xpath('./tr/td[2]/p[1]/text()')).strip(), # 作者'quote': ''.join(tr.xpath('./tr/td[2]/p[2]/span/text()')).strip() # 引用}print(tr_data)if __name__ == "__main__": askUrl("https://book.douban.com/top250?start=0") 如果报错:
urllib3 v2 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with 'LibreSSL 2.8.3'.
解决方法:
pip3 install urllib3==1.26.15
结果如下:
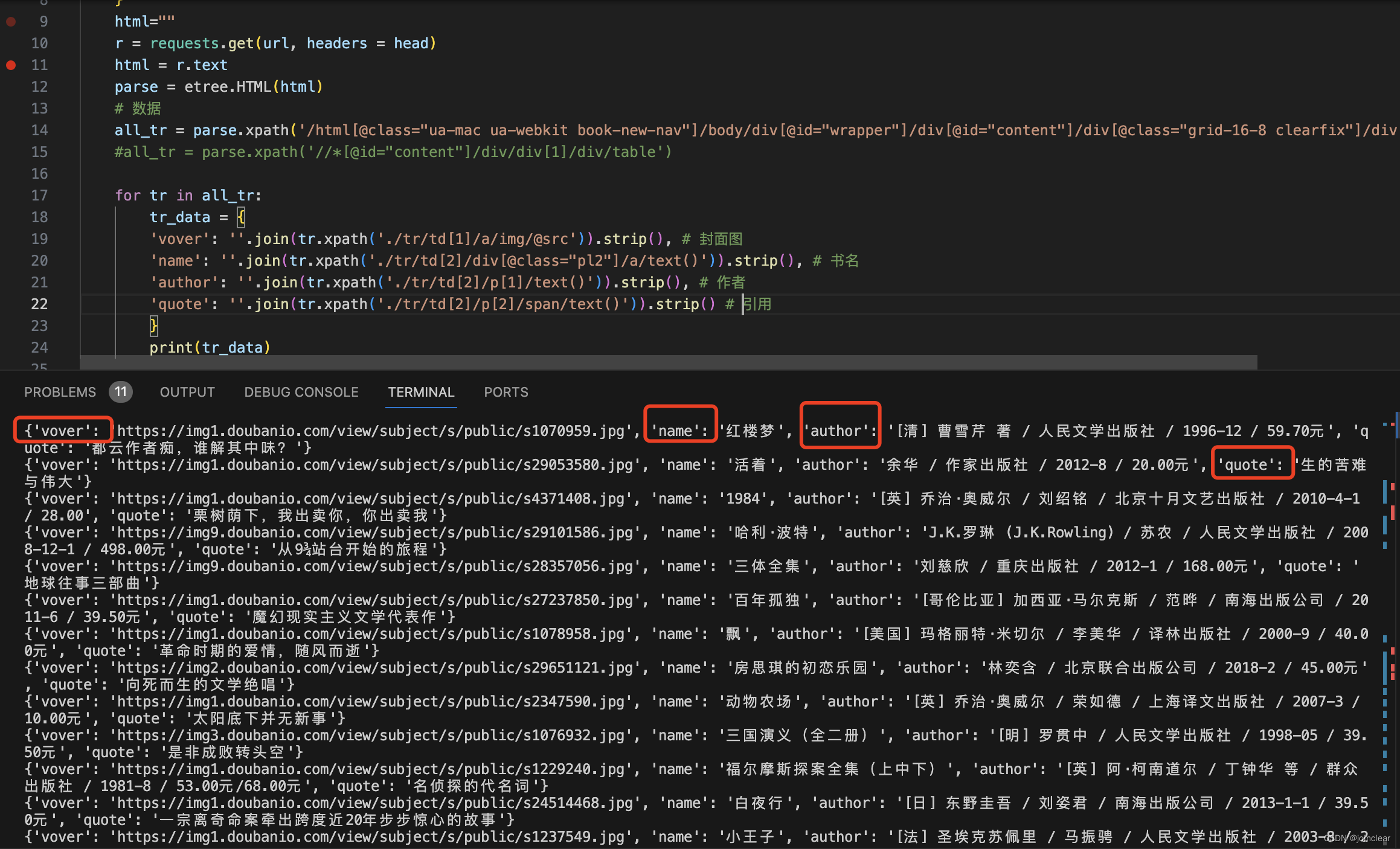
数据,已经非常清晰了。
PS:使用parse.xpath,最重要的是获取到准确的xpath值。
两个方法:
方法一:Google Chrome浏览器插件:xpath helper。
效果如下:
弹出插件面板:cmd+shift+x。
选中:shift。
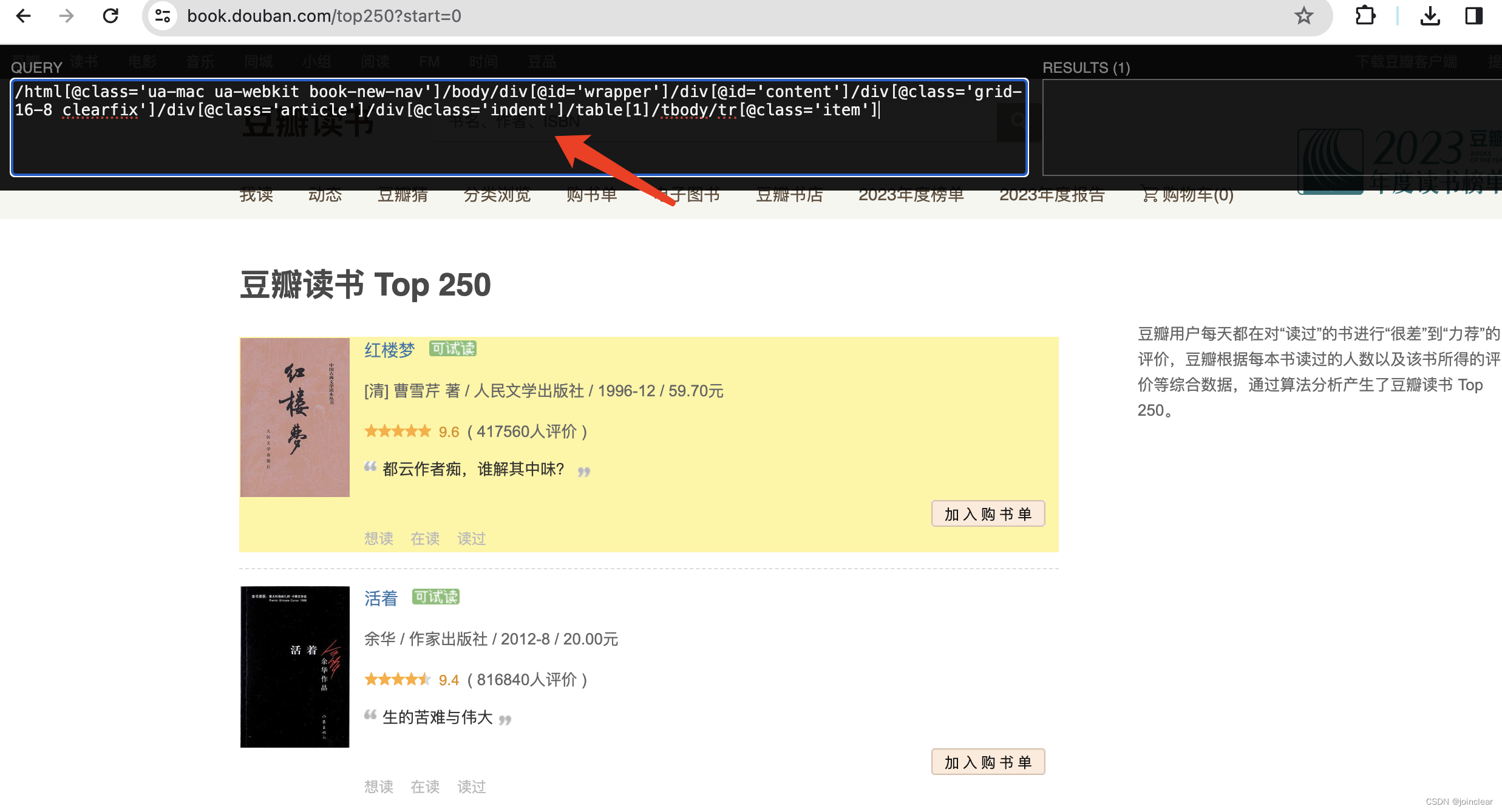
取到的值为:
# 原始值
/html[@class='ua-mac ua-webkit book-new-nav']/body/div[@id='wrapper']/div[@id='content']/div[@class='grid-16-8 clearfix']/div[@class='article']/div[@class='indent']/table[1]/tbody/tr[@class='item']# 优化后的值(使用此值,去掉了tbody和[1])
/html[@class='ua-mac ua-webkit book-new-nav']/body/div[@id='wrapper']/div[@id='content']/div[@class='grid-16-8 clearfix']/div[@class='article']/div[@class='indent']/table方法二:Google Chrome浏览器,查看源代码。
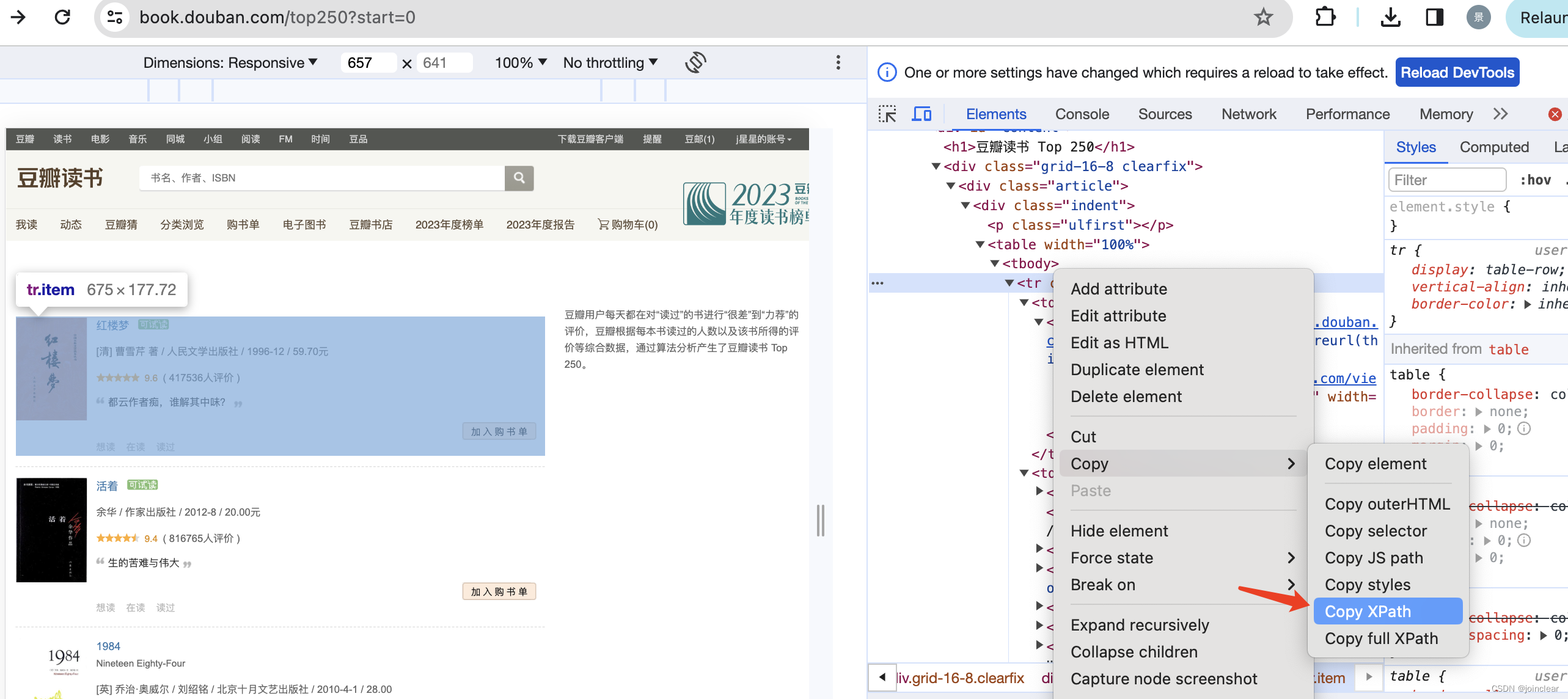
取到的值为:
# 原始值
//*[@id="content"]/div/div[1]/div/table[1]/tbody/tr# 优化后的值(使用此值,去掉了tbody和[1])
//*[@id="content"]/div/div[1]/div/table每一个字段对应的xpath值,也是这么获取。
4、导出excel文件
生成csv格式文件。
导入csv库:
import csv
导出cvs文件(第一页25条),代码如下:
import requests
from lxml import etree
import csvdef askUrl(url):head = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.15"}html="" r = requests.get(url, headers = head) html = r.text parse = etree.HTML(html) # 数据all_tr = parse.xpath('//*[@id="content"]/div/div[1]/div/table')# 创建book.csv文件with open('book.csv', 'a', encoding='utf_8_sig', newline='') as fp: header = ['封面','名称', '作者', '引用'] writer = csv.writer(fp) writer.writerow(header)for tr in all_tr:tr_data = {'vover': ''.join(tr.xpath('./tr/td[1]/a/img/@src')).strip(), # 封面图'name': ''.join(tr.xpath('./tr/td[2]/div[@class="pl2"]/a/text()')).strip(), # 书名'author': ''.join(tr.xpath('./tr/td[2]/p[1]/text()')).strip(), # 作者'quote': ''.join(tr.xpath('./tr/td[2]/p[2]/span/text()')).strip() # 引用}# print(tr_data)# 写入数据行with open('book.csv', 'a', encoding='utf_8_sig', newline='') as fp: fieldnames = ['vover','name', 'author', 'quote'] writer = csv.DictWriter(fp, fieldnames) writer.writerow(tr_data)if __name__ == "__main__": askUrl("https://book.douban.com/top250?start=0")
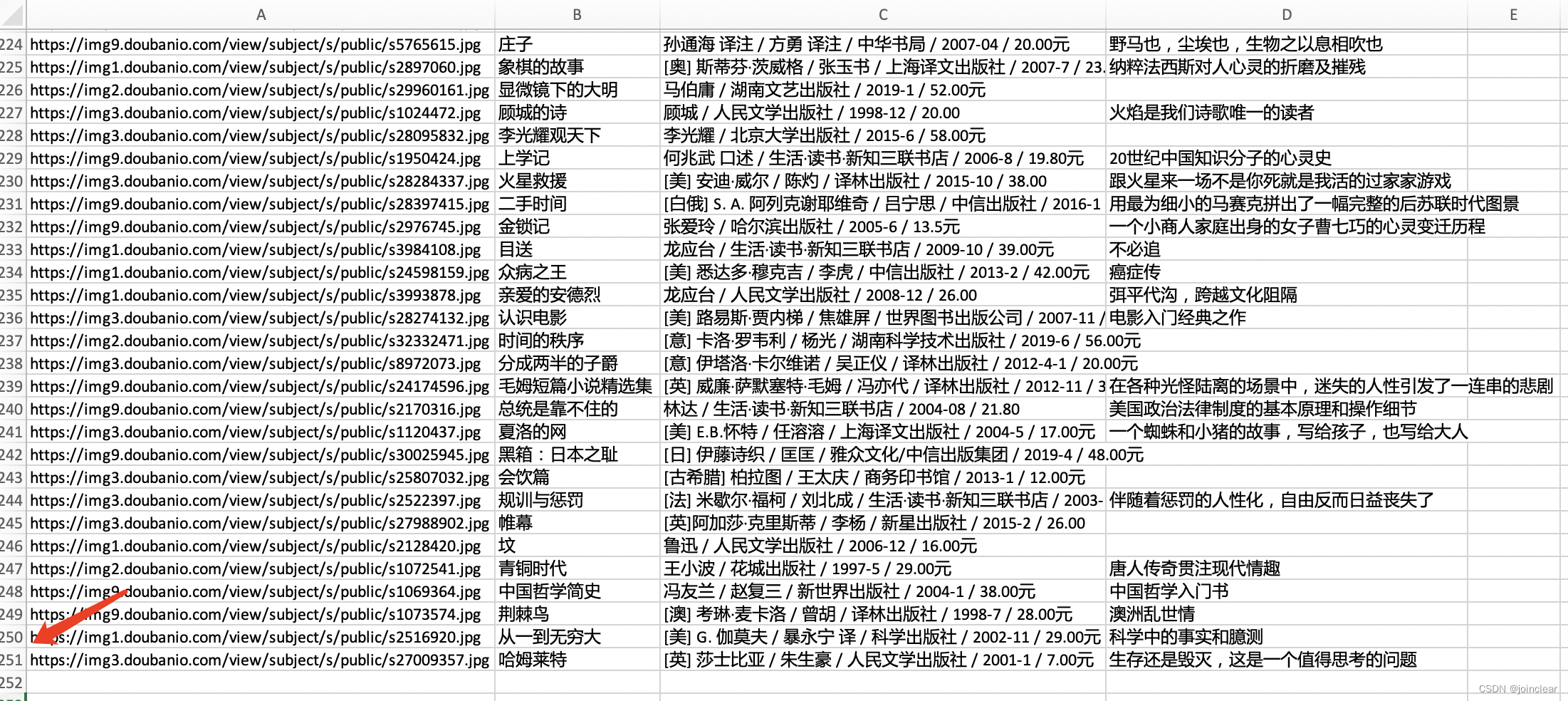
导出的book.csv文件(第一页),如下:

导出cvs文件(所有的250条),代码如下:
import requests
from lxml import etree
import csvdef askUrl(url):head = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1 Safari/605.1.15"}r = requests.get(url, headers = head)html = r.text# print(html)parse = etree.HTML(html)all_tr = parse.xpath('//*[@id="content"]/div/div[1]/div/table')for tr in all_tr:tr_data = {'vover': ''.join(tr.xpath('./tr/td[1]/a/img/@src')).strip(), # 封面图'name': ''.join(tr.xpath('./tr/td[2]/div[@class="pl2"]/a/text()')).strip(), # 书名'author': ''.join(tr.xpath('./tr/td[2]/p[1]/text()')).strip(), # 作者'quote': ''.join(tr.xpath('./tr/td[2]/p[2]/span/text()')).strip() # 引用}# print(tr_data)# 写入数据行with open('bookall.csv', 'a', encoding='utf_8_sig', newline='') as fp: fieldnames = ['vover','name', 'author', 'quote'] writer = csv.DictWriter(fp, fieldnames) writer.writerow(tr_data)def getData(baseurl):# 创建book.csv文件with open('bookall.csv', 'a', encoding='utf_8_sig', newline='') as fp: header = ['封面','名称', '作者', '引用'] writer = csv.writer(fp) writer.writerow(header)# 插入25页的数据for i in range(0, 10):url = baseurl + str(i * 25)html = askUrl(url)if __name__ == "__main__": baseurl = "https://book.douban.com/top250?start="getData(baseurl)导出的book.csv文件(所有页250条数据),如下: