企业网站建设的淘宝运营培训课程免费
一、专有名词解释
1.System on Chip(Soc)
Soc是把CPU、GPU、内存、通信基带、GPS模块等等整合在一起的芯片的称呼。常见有A系Soc(苹果),骁龙Soc(高通),麒麟Soc(华为),联发科Soc,猎户座Soc(三星),去年苹果推出的M系Soc,暂用于Mac,但这说明手机、笔记本和PC的通用芯片已经出现了。
2.System Memory(物理内存)
Soc中GPU和CPU共用一块片内LPDDR物理内存,就是我们常说的手机内存,也叫System Memory,大概几个G。此外CPU和GPU还分别有自己的高速SRAM的Cache缓存,也叫On-chip Memory,一般几百K~几M。不同距离的内存访问存在不同的时间消耗,距离越近消耗越低,读取System Memory的时间消耗大概是On-chip Memory的几倍到几十倍。
· Soc上GPU和CPU共享一个内存地址空间
3.On-Chip Buffer
在TB(D)R架构下会存储Tile的颜色、深度和模板缓冲,读写修改都非常快。如果Load/Store指令中缓冲需要被Preserve,将会被写入一份到System Memory中。
4.Stall
当一个GPU核心的两次计算结果之间有依赖关系而必须串行时,等待的过程便是Stall。
5.FillRate(像素填充率)
像素填充率 = ROP运行的时钟频率 x ROP的个数 x 每个时钟ROP可以处理的像素个数。
二、TB(D)R
1.什么是TB(D)R
TBR(Tile-Based (Deferred) Rendering)是目前主流的移动GPU渲染架构,对应一般PC上的GPU渲染架构则是IMR(Immediate Mode Rendering )。
TB(D)R的简单意思:屏幕被分成块(16*16像素 / 32*32像素)渲染。
2.TBR与TBDR
TBR:顶点Shader → Defer → 光栅化 → 像素Shader
TBDR:顶点Shader → Defer → 光栅化 → Defer → 像素Shader
Defer是什么?:字面是延迟的意思,但从渲染数据的角度来看,Defer就是“阻塞+批处理”GPU的“一帧”的多个数据,然后一起处理。
三、立即渲染架构(IMR)
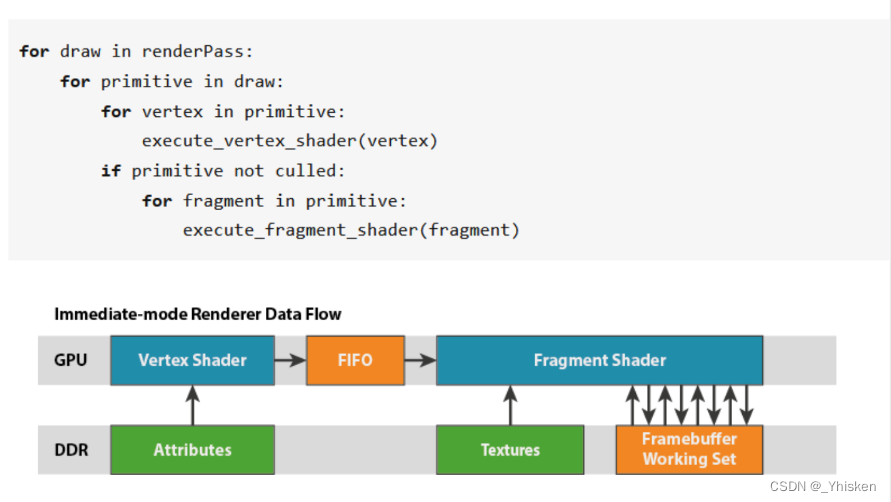
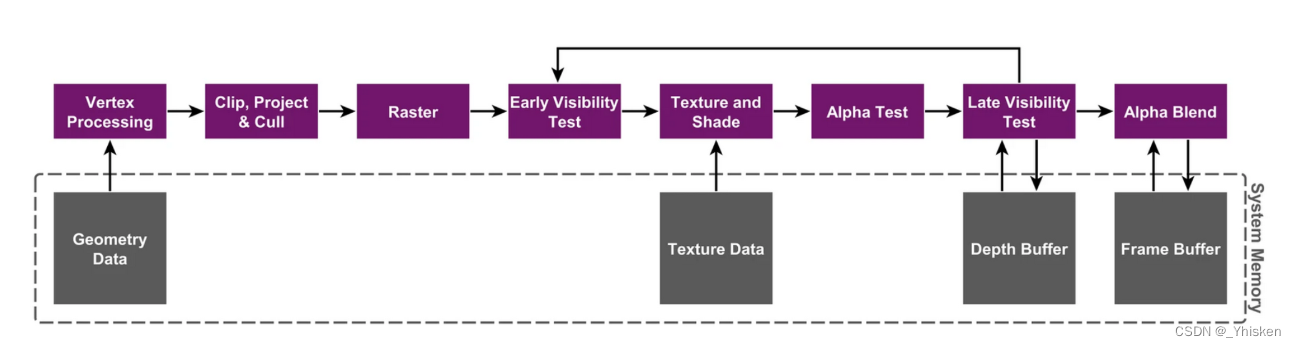
出处:A look at the PowerVR graphics architecture: Tile-based rendering - Imagination
可以看到,整个立即渲染架构流水线是直接和系统内存进行交互。
四、TBDR的渲染流程
1.宏观上的2个阶段:
第一阶段执行所有与几何相关的处理,并生成Primitive List(图元列表),并确定每个tile上面有哪些primitive。(分图元)
第二阶段将逐块执行光栅化及后续处理,并在完成后将Frame Buffer从Tile Buffer写回到System Memory中。(TBDR第二阶段相比传统的立即渲染架构,它并不是直接将结果写回到系统内存中,而是写到片上内存中)
2.简略示意图
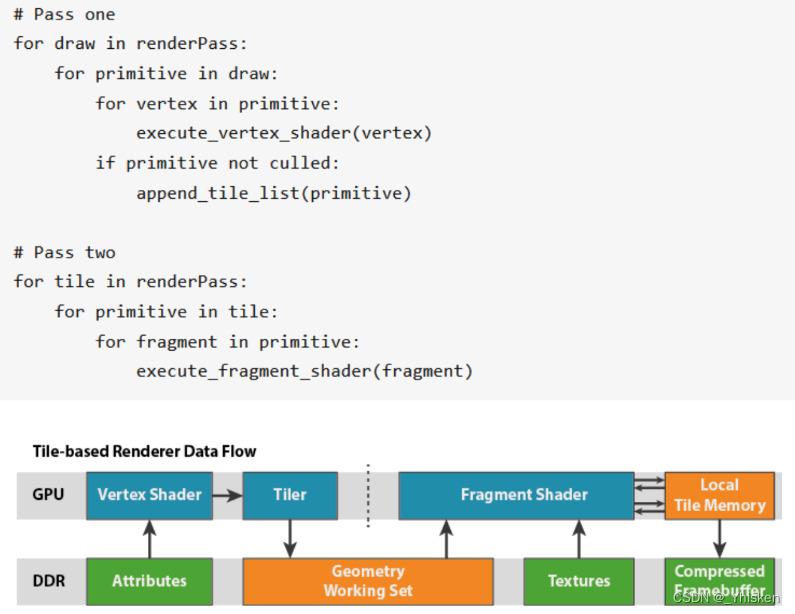
可以看到再顶点着色器后有一个Tiler的过程,这个Tiler个过程就是把所有图元分成不同块元的过程(确定每个块元包含哪些图元)。之后进行片元处理后,先把处理后的块元先写入自己块元的内存上,之后再写入系统内存。
3.详细示意图
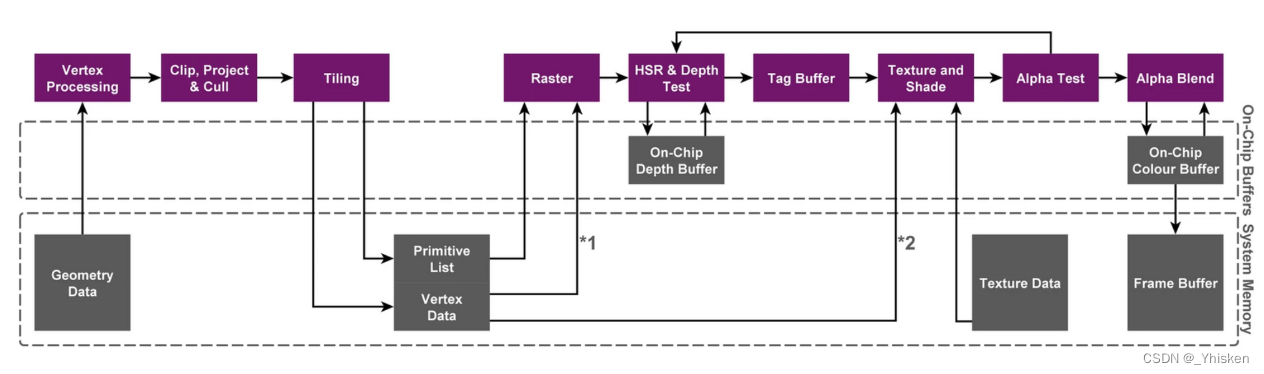
出处:A look at the powervr graphics architecture tile based rendering
可以看到上图中有两个虚线框,其中上面的虚线框表示片上内存,下面的虚线框表示系统内存。
可以看到有一个Tilling的过程,它把我们经过顶点操作处理后的几何数据写到了系统内存上面,那么之后经过光栅化和后续的处理操作,仍然是先写入片上内存,最后进入Frame Buffer。
4.比较
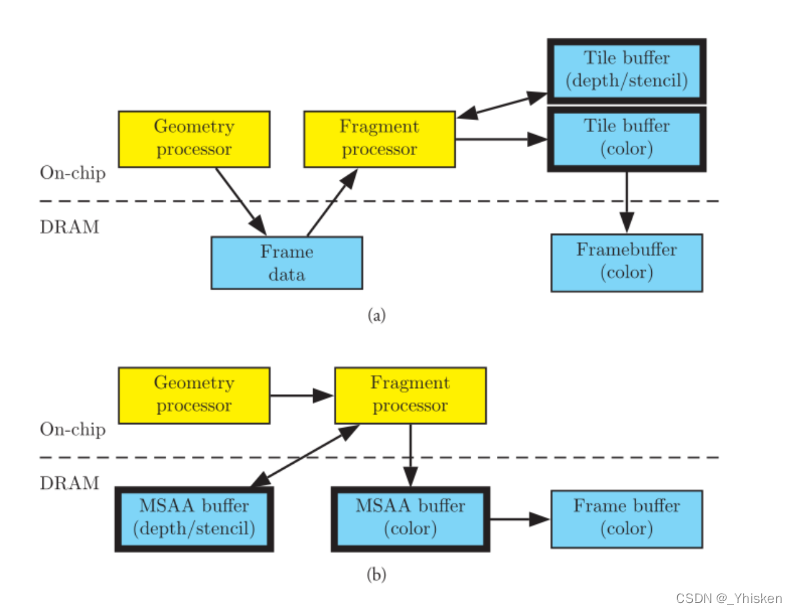
相比于IMR架构,TB(D)R架构在几何处理和片段处理两步中增加了一个Frame data的区域,同时在最终输出时,先输出到片内存中,而不是直接输出到Frame Buffer。
5.TBR(Tile-Based (Deferred) Rendering)示意图
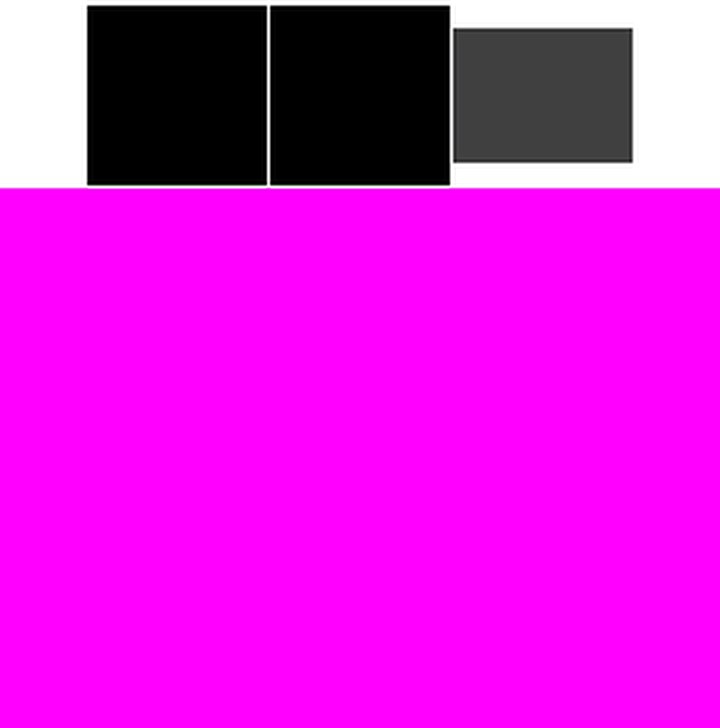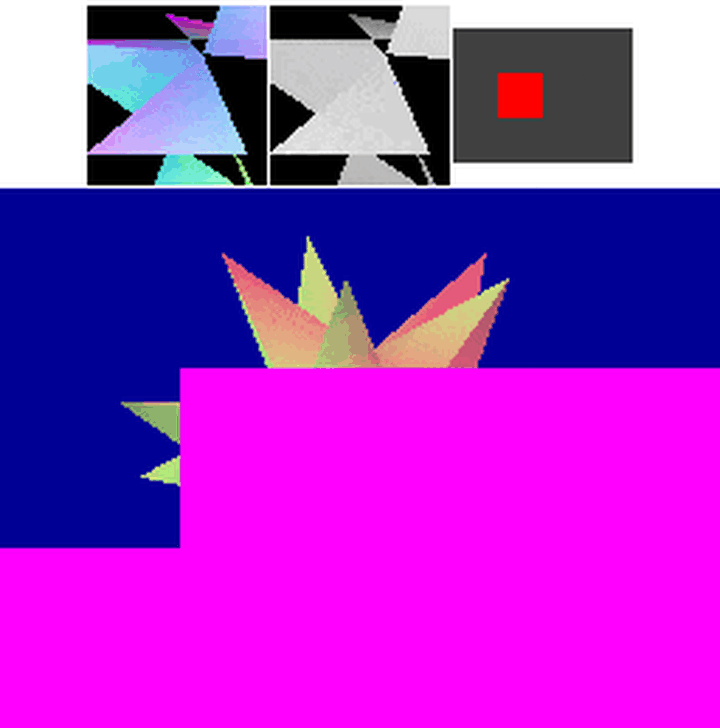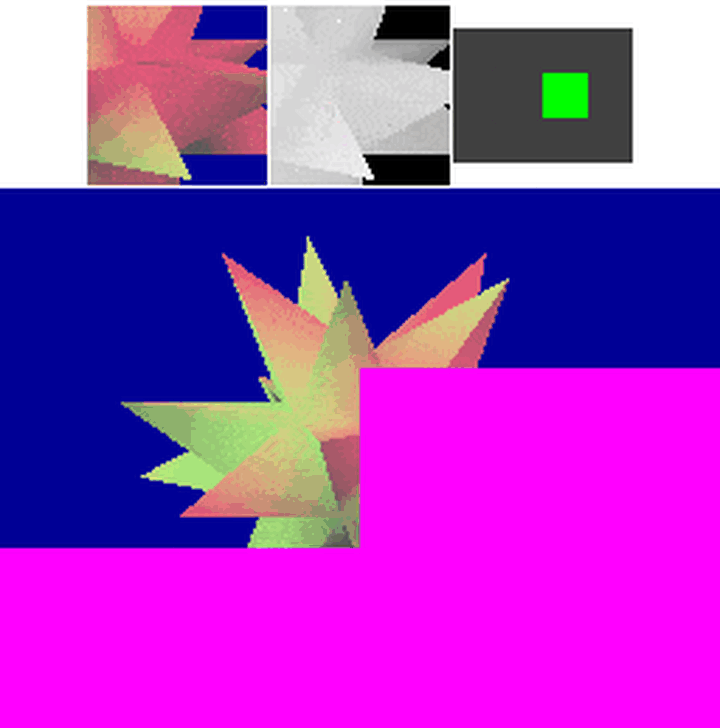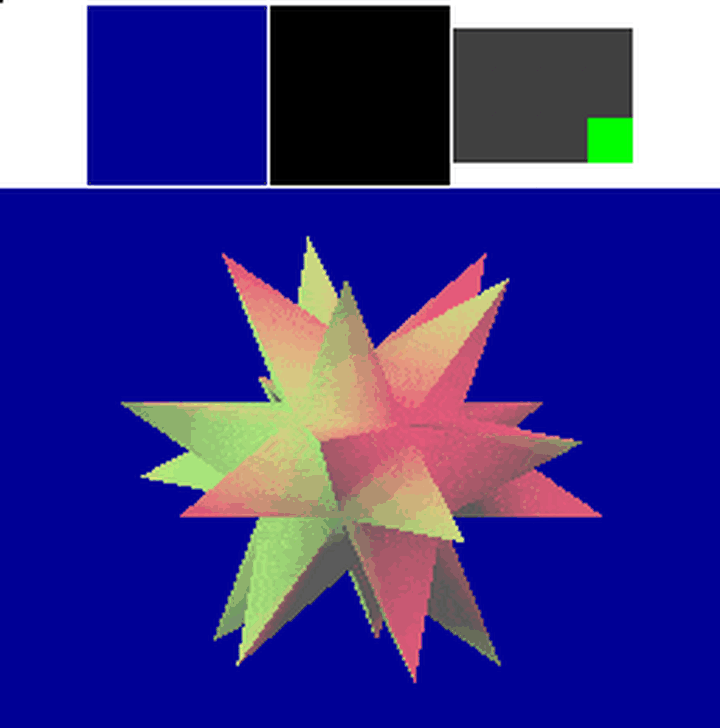
6.GPU乱序执行:IMR和TB(D)R
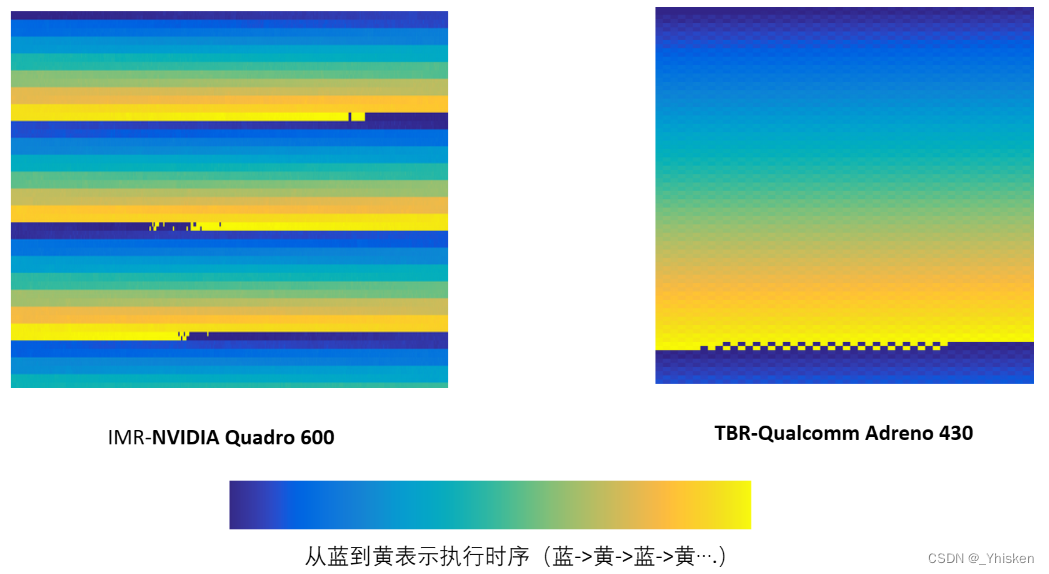
可以看到,实际上,GPU并不会严格的按照从左到右/从上到下竟然有序的执行。
五、小结
TBR的核心目的是降低带宽,减少功耗,但渲染帧率上并不比IMR快
1.优点
(1):TBR给消除Overdraw提供了机会,PowerVR用了HSR技术,Mali用了Forward Pixel Killing技术,目标一样,就是要最大限度减少被遮挡pixel的texturing和shading。
(2):TBR主要是 缓存友好, 在缓存里头的速度要比全局内存的速度快的多,以及有可能降低帧率的代价,降低带宽,省电。
2.缺点
(1)binning过程需要在vertex阶段之后,将输出的几何数据写入到DDR,然后才被fragment shader读取(几何数据过多的管线容易在此处有性能瓶颈)。这之间也就是tile写入DDR的开销和fragment shader渲染读取DDR开销的平衡。另外还有一些操作(比如tessellation)也不适用于TBR。
(2)如果某些三角形叠加在数个图块(Overdraw),则需要绘制数次。这意味着总渲染时间将高于即时渲染模式。
六、两个重要的Defer/批处理
1.Binning过程(类似四叉树)
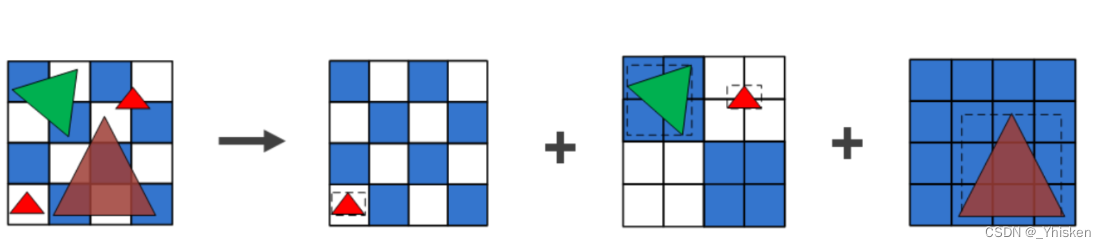
Binning过程实际上就是决定每一个图元由哪些块元来渲染的一个过程,如上图所示。
2.不同GPU的Eearly-DT
· Android平台

(2)Arm Mali
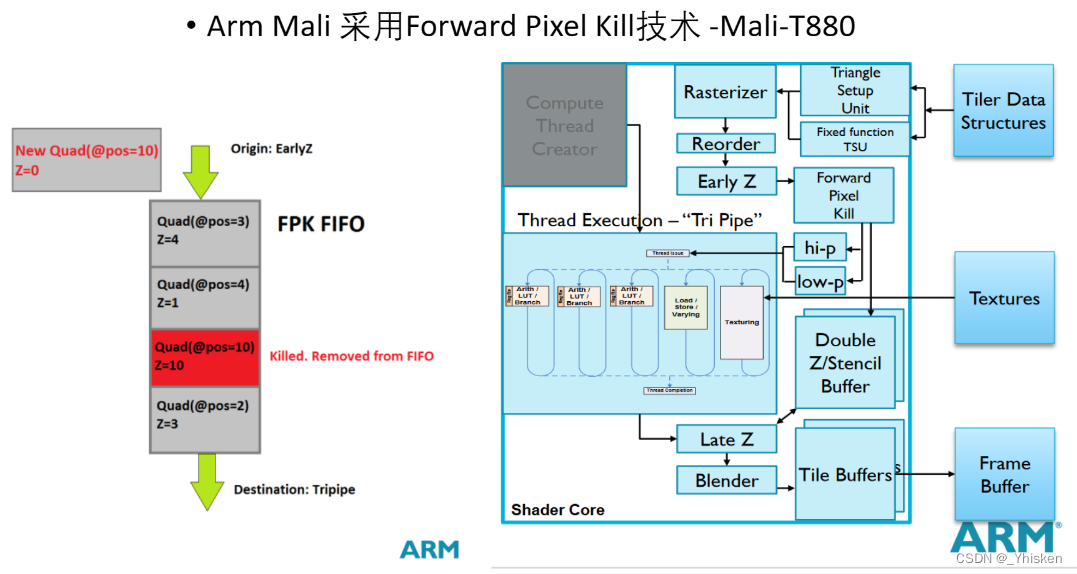
Arm Mali发生在early depth/early Z之后,是一个先进先出的队列。在上图左侧可以看到,该队列中已经存在了4个Quad,每个Quad可以理解为一个2x2像素的平面,它们带有一个pos信息记录它们在屏幕上的位置,其次还有Z,也就是深度,那么如图所示,当新进来的Quad和队列中已有的Quad的pos相同的时候,Z=10的被Z=0的替换掉。
· IOS平台
(1)HSR(隐形面剔除)
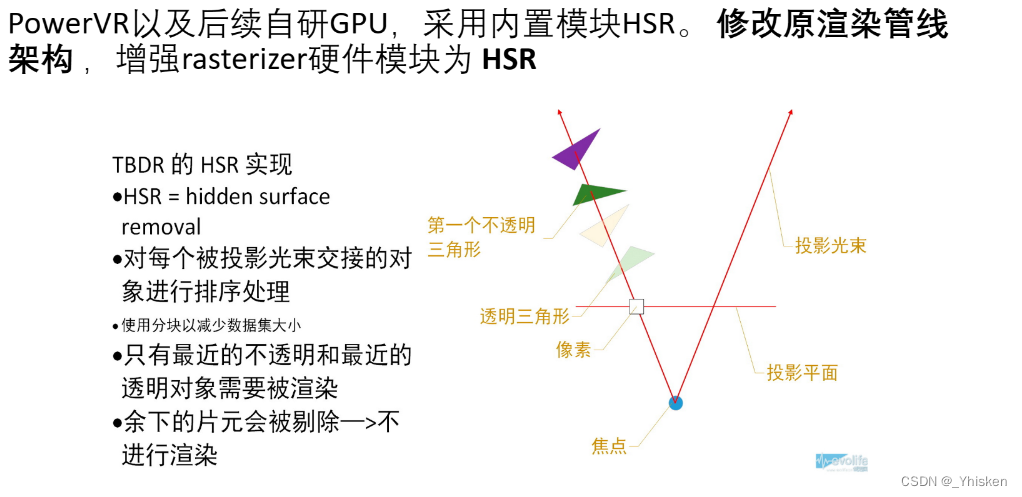
发出一条射线,遇到的第一个不透明三角形的时候停止下来,打断后面三角形的像素着色器的处理。
七、移动端Tile Based Render的优化



参考:
3710-移动端GPU的TB(D)R架构_哔哩哔哩_bilibili
PPT:3710-移动端GPU的TB(D)R架构(1) (qq.com)