郑州市建设网免费关键词排名优化软件
一、文件过多导致HiveServer2内存溢出
1.1查看表文件个数
desc formatted yanyu.tmp
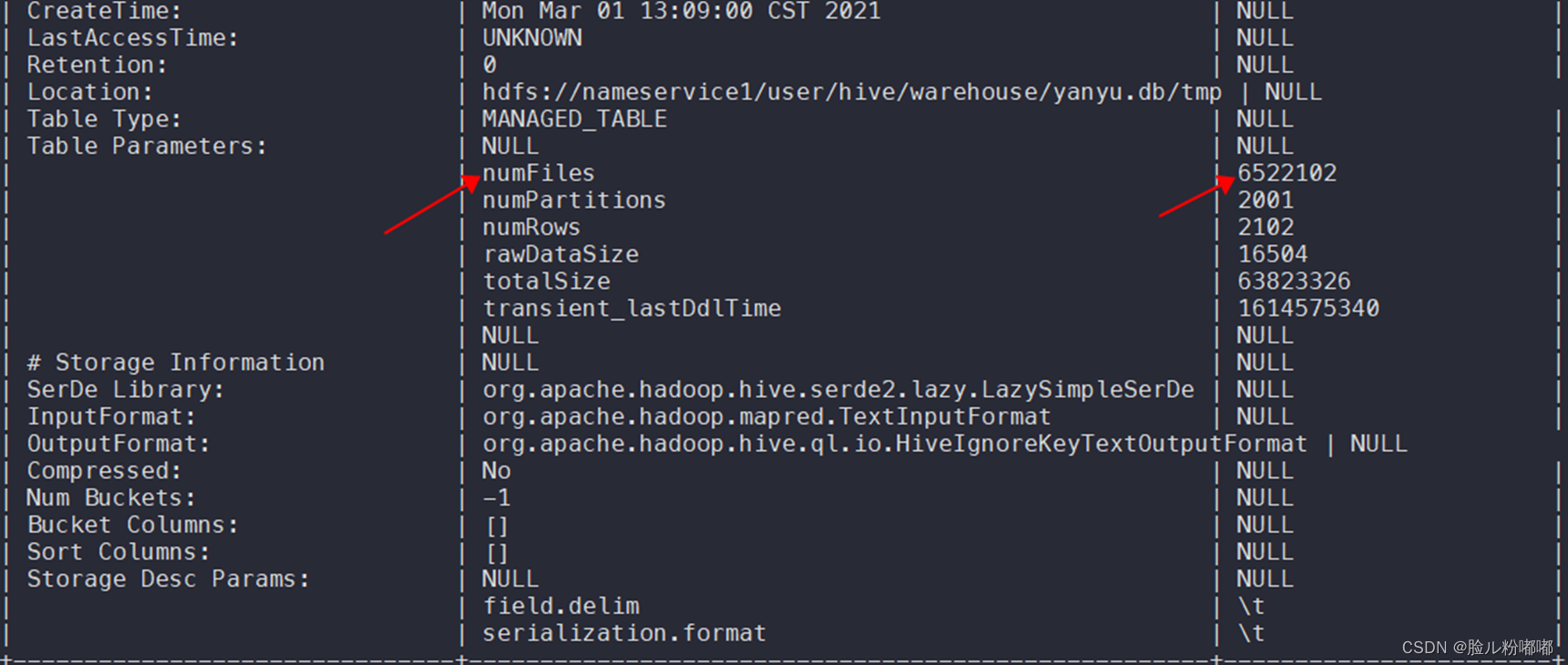
• 表文件数量为6522102
1.2查看表文件信息
hadoop fs -ls warehouse/yanyu.db/tmp
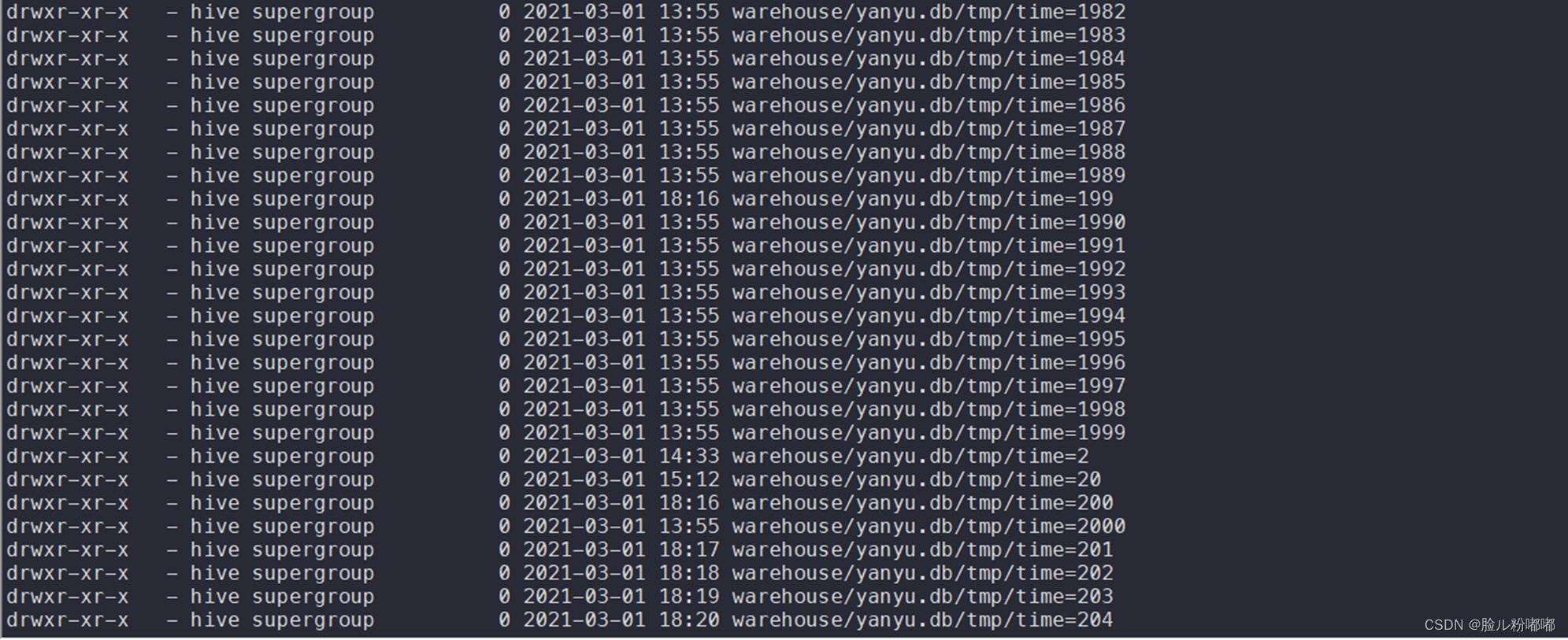
• 分区为string 类型的time字段,分了2001个区。
1.3.查看某个分区下的文件个数为10000个
hadoop fs -ls warehouse/yanyu.db/tmp/time=45
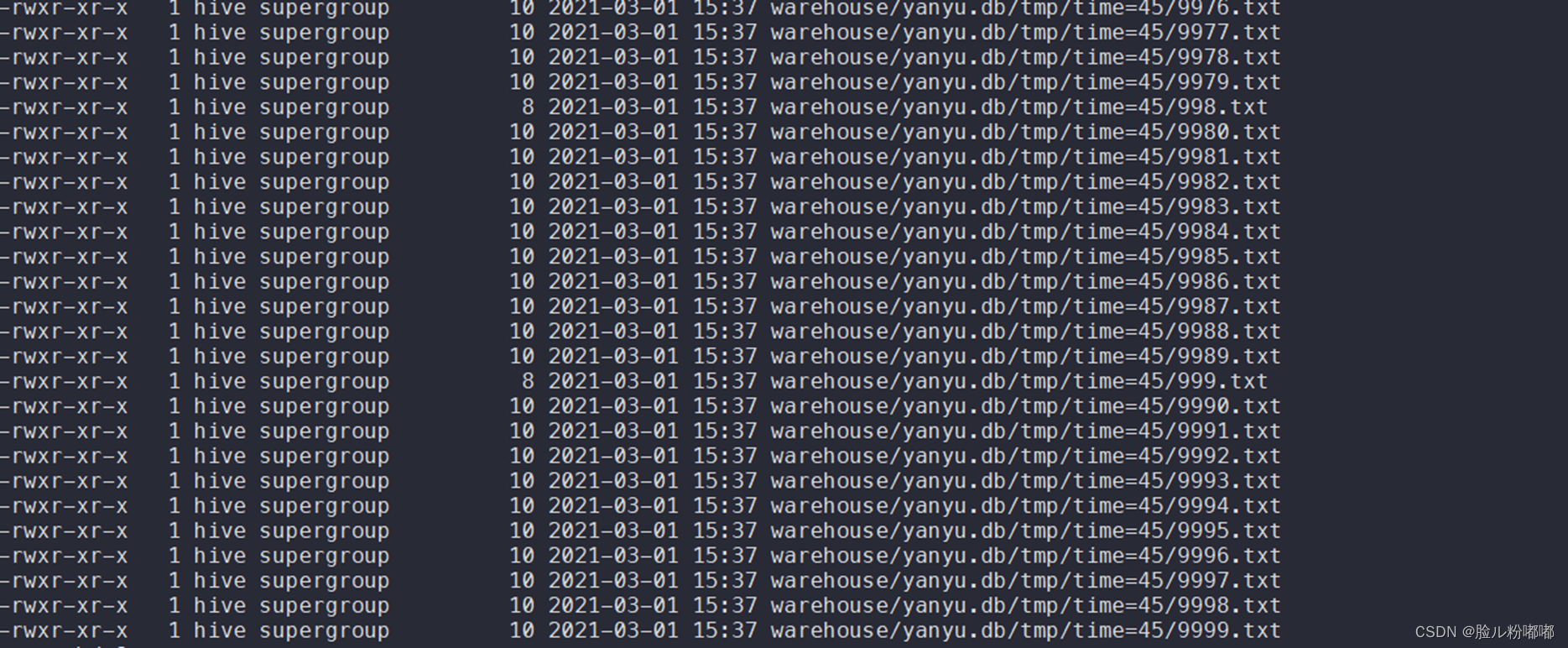
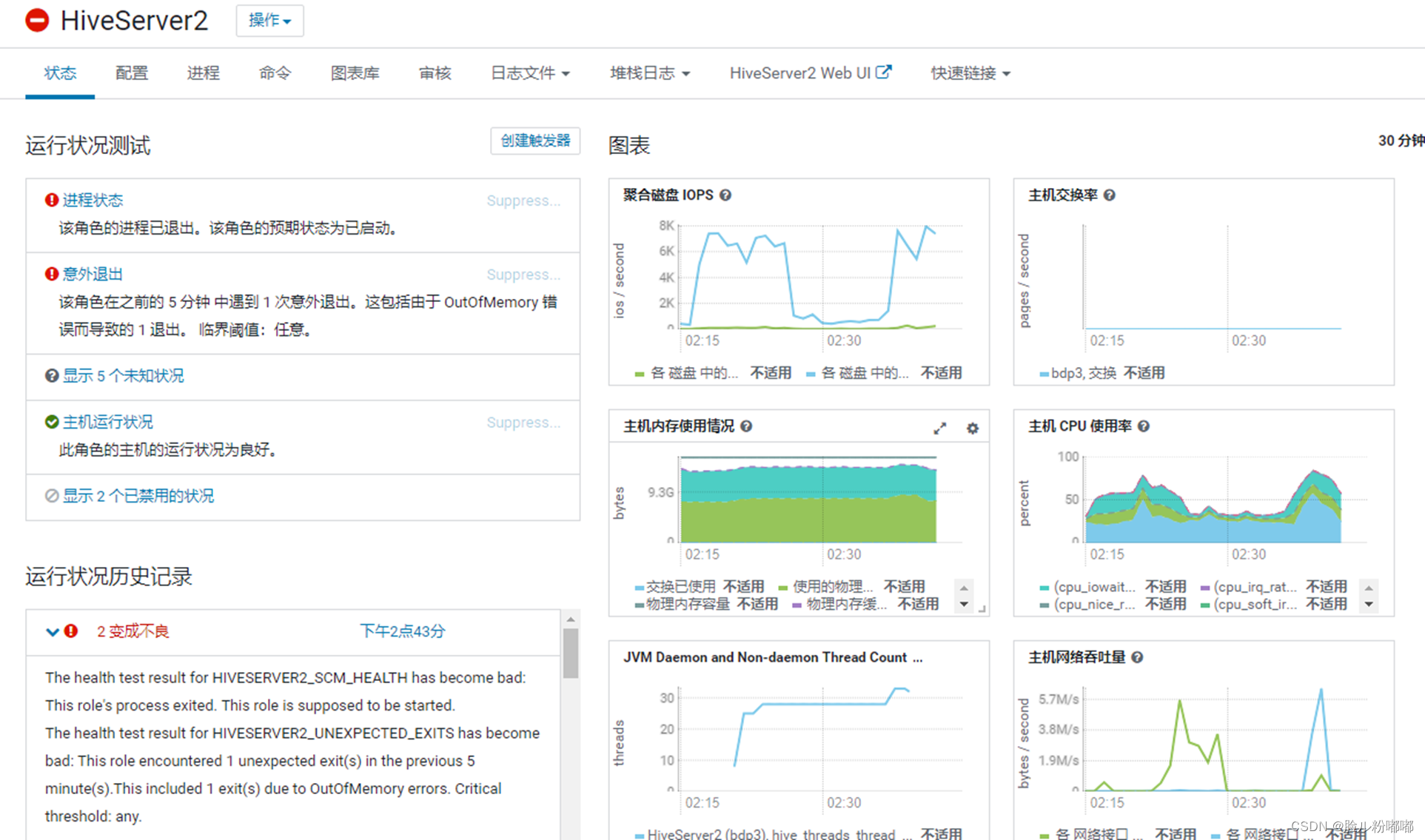
1.4.执行select count(*) 是否内存溢出
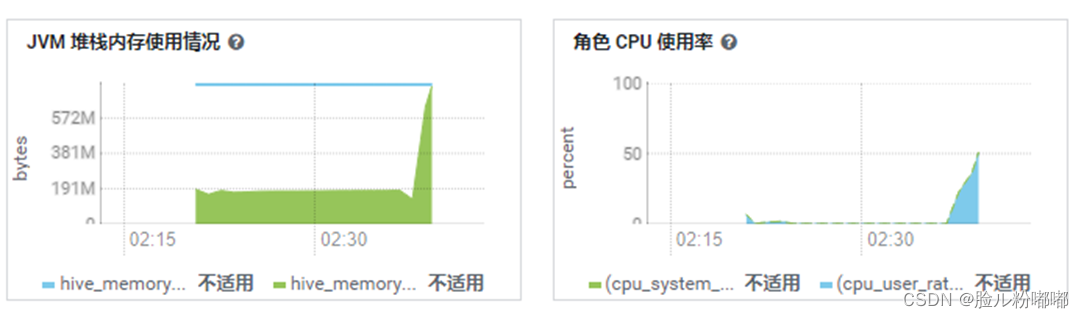
•可以看到Jvm内存使用明显增大,Hiveserver2内存溢出,进程挂掉了;查看HiveServer2状态标红。
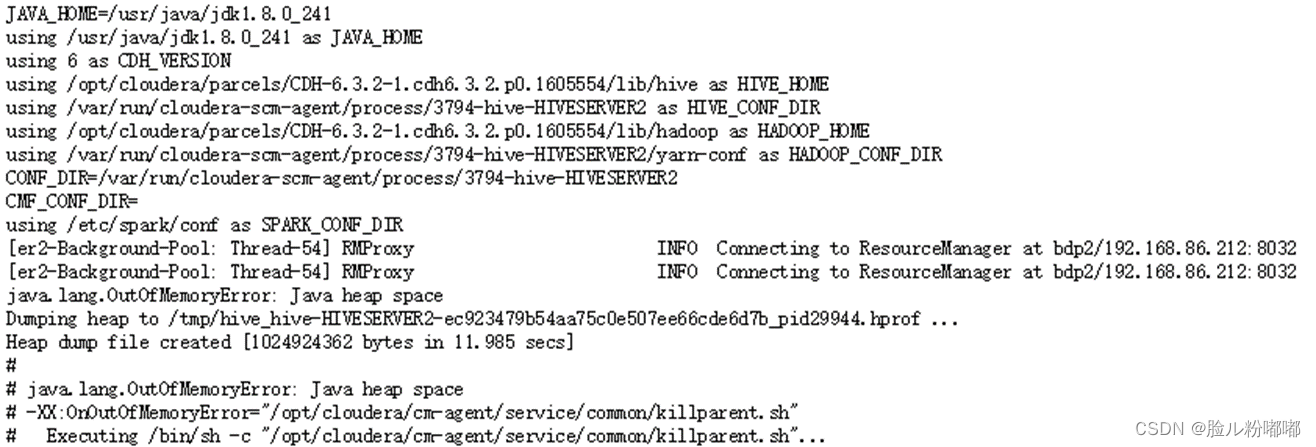
•详细日志如下

二、合并小文件以解决HiveServer2内存溢出
2.1小文件合并
• 将每个分区里的若干个小文件合并成一个文件,最终文件个数为分区数。合并流程如下:
2.1.1 创建表结构一致的临时表
查看原始表信息desc formatted yanyu.tmp
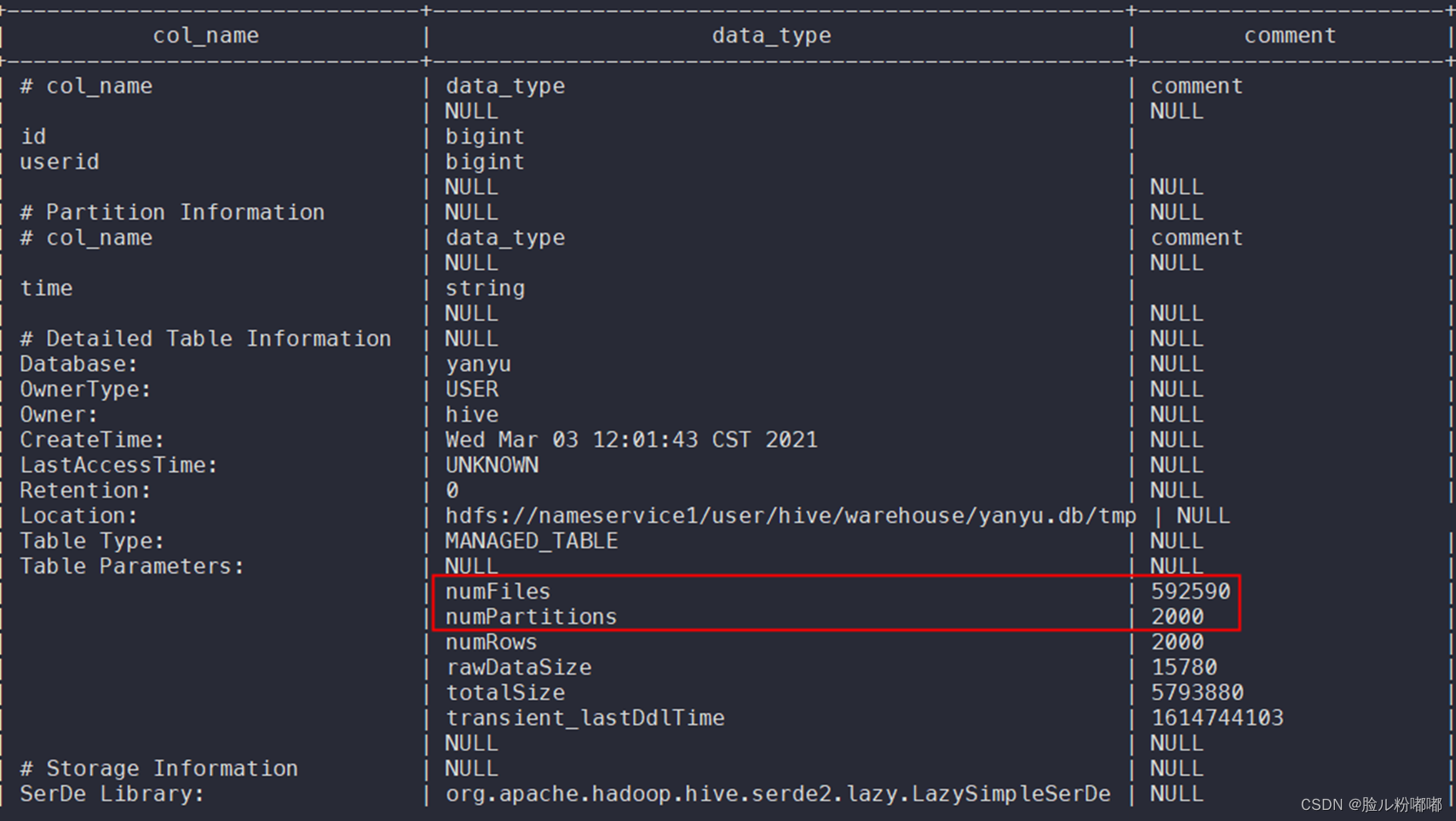
• 然后创建一个数据结构与原表完全一样的临时表用来存储数据。
create table yanyu.tmp_bak like yanyu.tmp;查看表属性show create table yanyu.tmp_bak;
2.1.2 将原始数据导入到临时表
• 配置合并小文件的参数
SET hive.merge.mapfiles = true;
SET hive.merge.mapredfiles = true;
--输出时合并小文件大小为256M
SET hive.merge.size.per.task = 256000000;
--输出文件平均大小小于该值,则开启小文件合并
SET hive.merge.smallfiles.avgsize = 134217728;
SET hive.exec.compress.output = true;
SET parquet.compression = snappy;
SET hive.exec.dynamic.partition.mode = nonstrict;
SET hive.exec.dynamic.partition = true;
• 查询原表数据并使用insert overwrite 将原表数据插入到临时表中
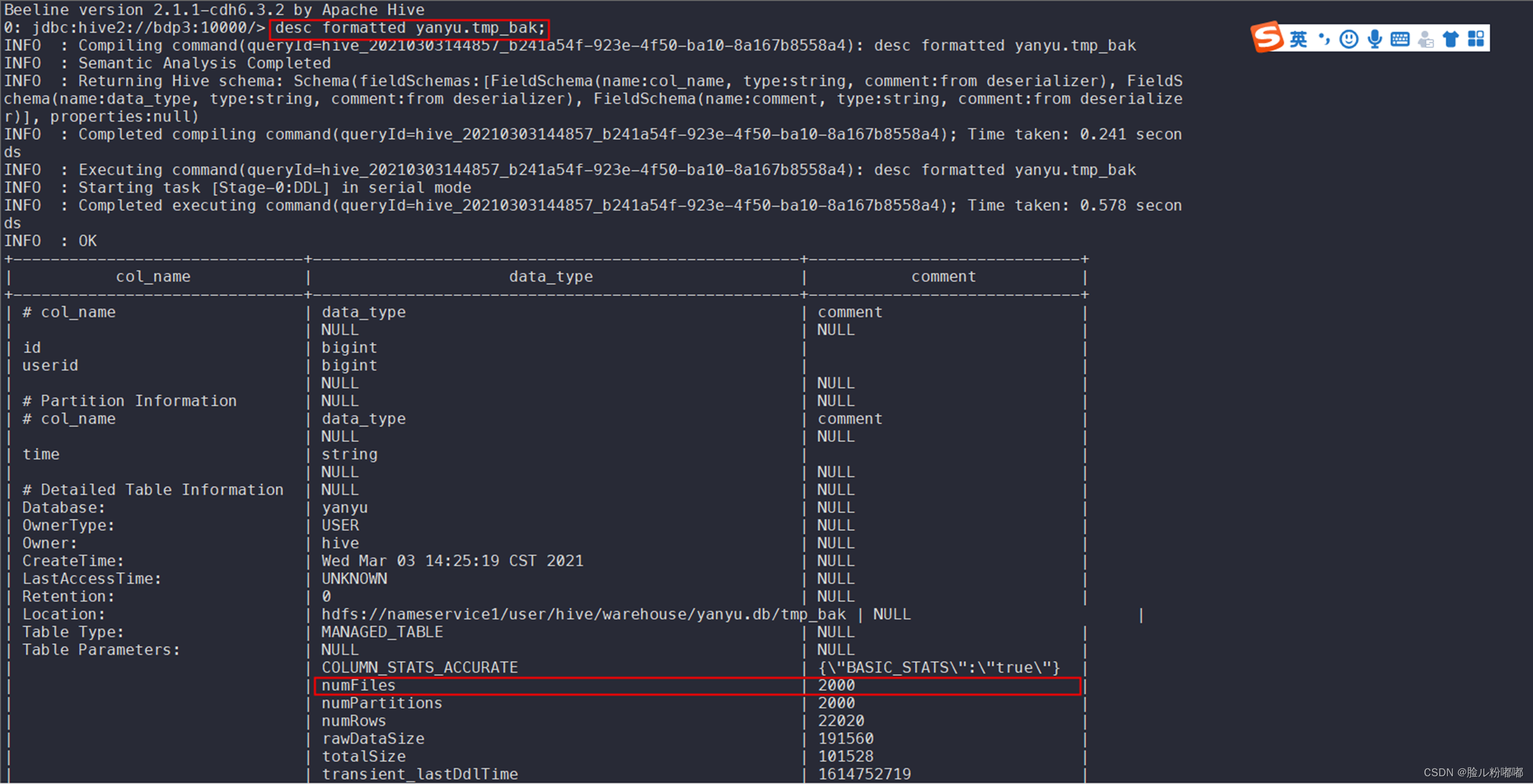
insert overwrite table yanyu.tmp_bak partition(time) select * from yanyu.tmp;查看合并小文件后的表文件个数(2000个):desc formatted yanyu.tmp_bak;
2.1.3 查看hdfs文件系统里原始表和合并小文件表后任意分区下面的文件数量
查看合并后的文件数量:hadoop fs -ls warehouse/yanyu.db/tmp_bak/time=0

对比查看原始表分区下的文件数量:hadoop fs -ls warehouse/yanyu.db/tmp/time=0
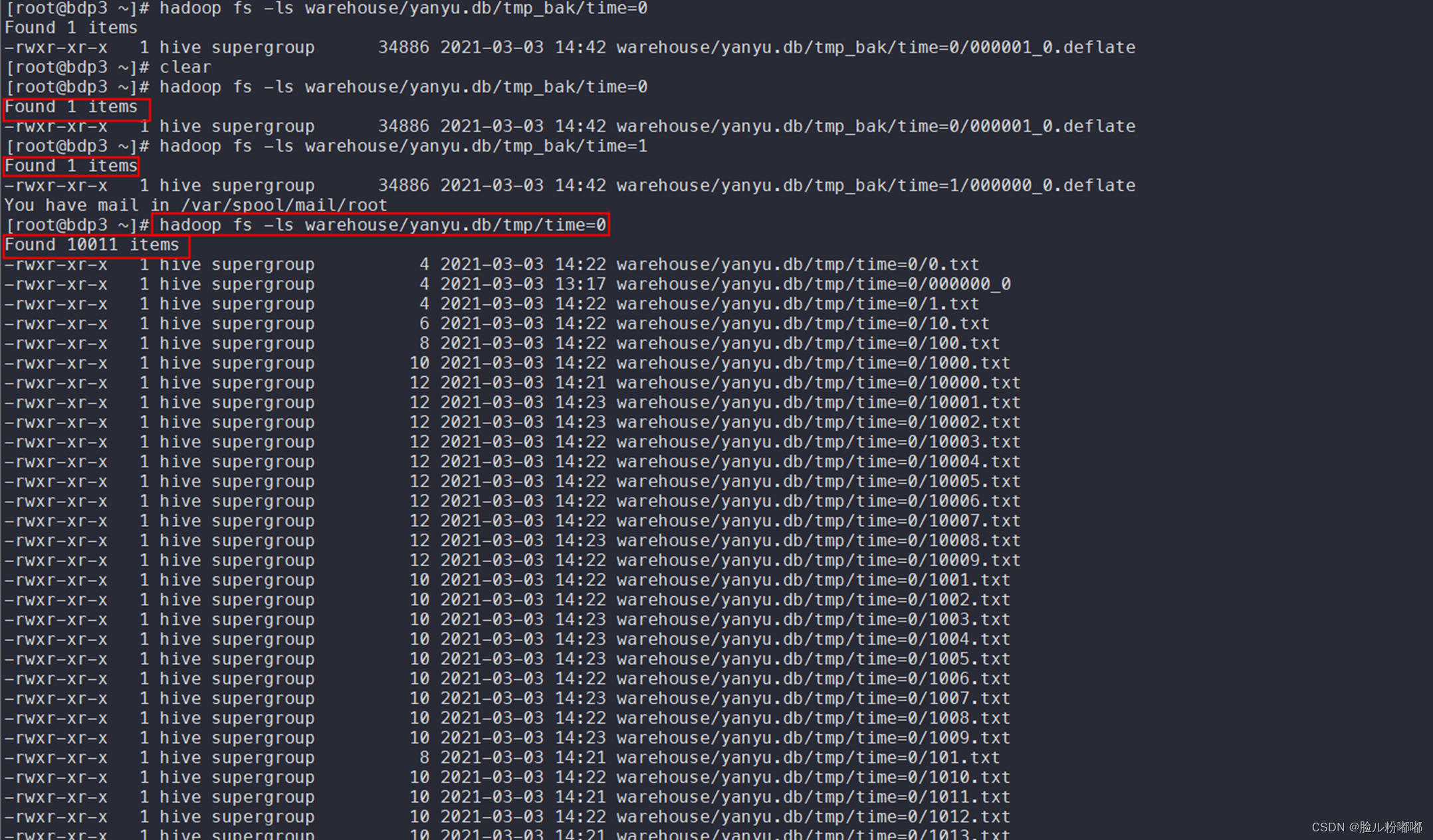
• 说明:小文件合并操作后原始表的分区下的大量小文件合并为一个文件。
2.1.4 压缩小文件进行合并后是否查看数据
• 查看原始文件数据,正常显示

• 查看合并后的文件内容为乱码。
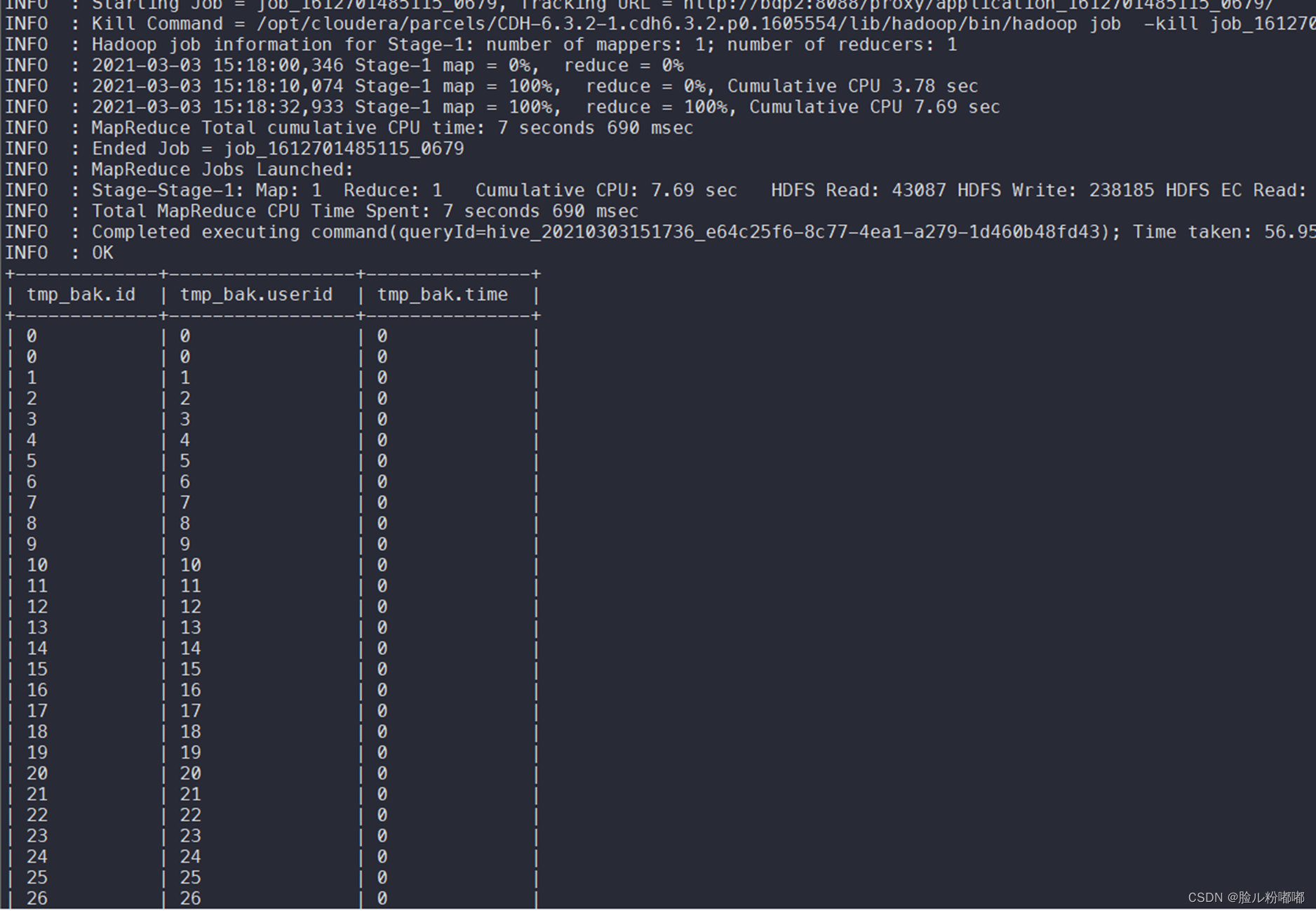
• 使用sql检查临时表数据是否和原表数据一致。
• 查看hdfs文件系统表格路径下文件个数是否与分区数一致。
hadoop fs -ls warehouse/yanyu.db/tmp_bak
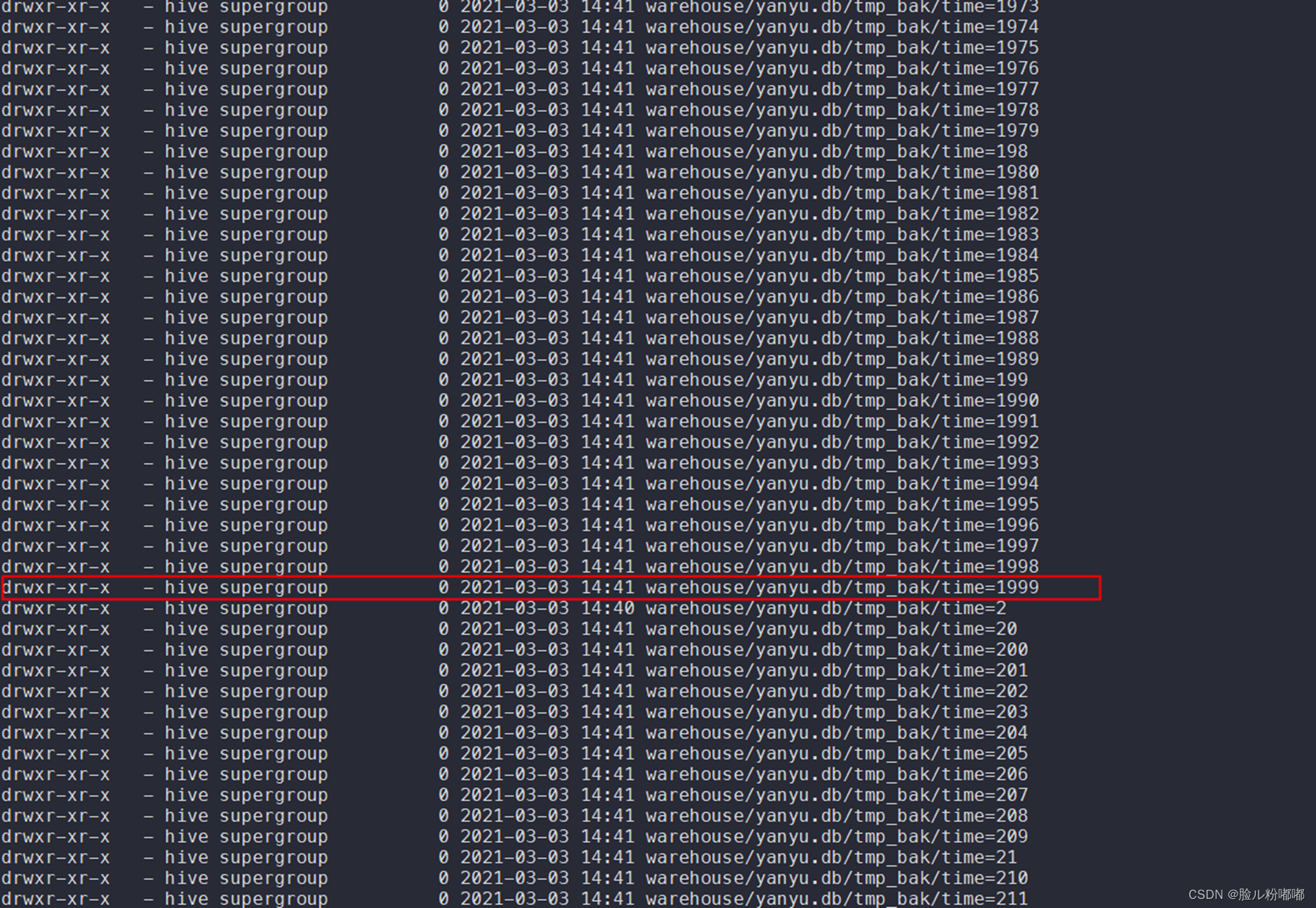
查看合并小文件后分区最大值为1999即有2000个分区(分区类型为string,以字符串排序)
2.1.5 删除原始表
• 确认表数据一致后,删除原表,使用alert修改临时表名为原表名。
alter table yanyu.tmp_bak rename to yanyu.tmp
三、总结
使用HiveServer2查询数据时,会将元数据都加载到内存中,如果一个表格的分区很大,每个分区中又有很多的小文件,就会导致将元数据加载到内存中时使用的内存比较大。因此,Cloudera公司推荐使用的分区数最好不要超过1000个分区;同时分区中的也不要存储过多的为小文件,要定期对数据进行治理以合并小文件。