如何让做网站快手作品推广网站

目录
1.前言
2.mapreduce编程示例
3.MapReduce适用场景
1.前言
本文是作者大数据系列专栏的其中一篇,前文我们依次聊了大数据的概论、分布式文件系统、分布式数据库、以及计算引擎mapreduce核心概念以及工作原理。
书接上文,本文将会继续聊一下mapreduce的编程实践以及mapreduce的适用场景。基于的Hadoop版本依然是前文的hadoop3.1.3。
2.mapreduce编程示例
本文依然以最经典的单词分词,即统计各个单词数量的业务场景为例。mapreduce其实就是编写map函数和reduce函数。map reduce的Java API中提供了map和reduce的标准接口,实现接口,编写自己的业务逻辑即可。
依赖:
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>3.1.3</version>
</dependency>map函数:
map阶段会从分布式文件系统HDFS中去读数据,读入的数据先进行分词,然后进行初步的统计。所以编写map函数要写的就是分词和统计:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.Text;public class MyMapper extends Mapper<Object, Text, Text, IntWritable> {private Text word = new Text();@Overrideprotected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, new IntWritable(1));}}
}key,是每条输入的键,默认情况下处理文本文件时通常是记录的偏移量,类型为Object(实践中常为LongWritable)。
context是输出。
在new StringTokenizer这一步,文本就会进行分词。
IntWritable是int的包装类,主要是为了赋予int类型可序列化的能力,毕竟要在网络中进行传输。
reduce函数:
reduce的shuffle是底层自动执行的,所以我们只需要编写好reduce函数即可:
reduce函数的输入就是shuffle后的<key,Iterable>,context是输出。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int sum=0;for(IntWritable val:values){sum+=val.get();}context.write(key,new IntWritable(sum));}
}
main函数:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class MapReduceTest {public static void main(String[] args)throws Exception {Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://192.168.31.10:9000");conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");Job job = Job.getInstance(conf, "word count");job.setJarByClass(MapReduceTest.class); // 使用当前类的类加载器job.setMapperClass(MyMapper.class);job.setCombinerClass(MyReducer.class);job.setReducerClass(MyReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path("/user/hadoop/input/input1.txt"));FileOutputFormat.setOutputPath(job, new Path("/user/hadoop/output"));job.waitForCompletion(true);}
}
3.MapReduce适用场景
mapreduce适用于哪些场景?之前聊了那么多,似乎MapReduce也就只能统计一下数量?其实不是这样的,MapReduce能用来实现一切代数关系运算,即:选择、投影、并、交、差、连接,也就是对应关系型数据库的全部操作。
以连接为例:
在存数据的时候通过一个外键来预留好关联点。map和reduce函数都是我们手动定义的,map阶段我们完全可以把外键作为key,这样在reduce的shuffle阶段数据自然就会通过外键这个key聚合在一起。
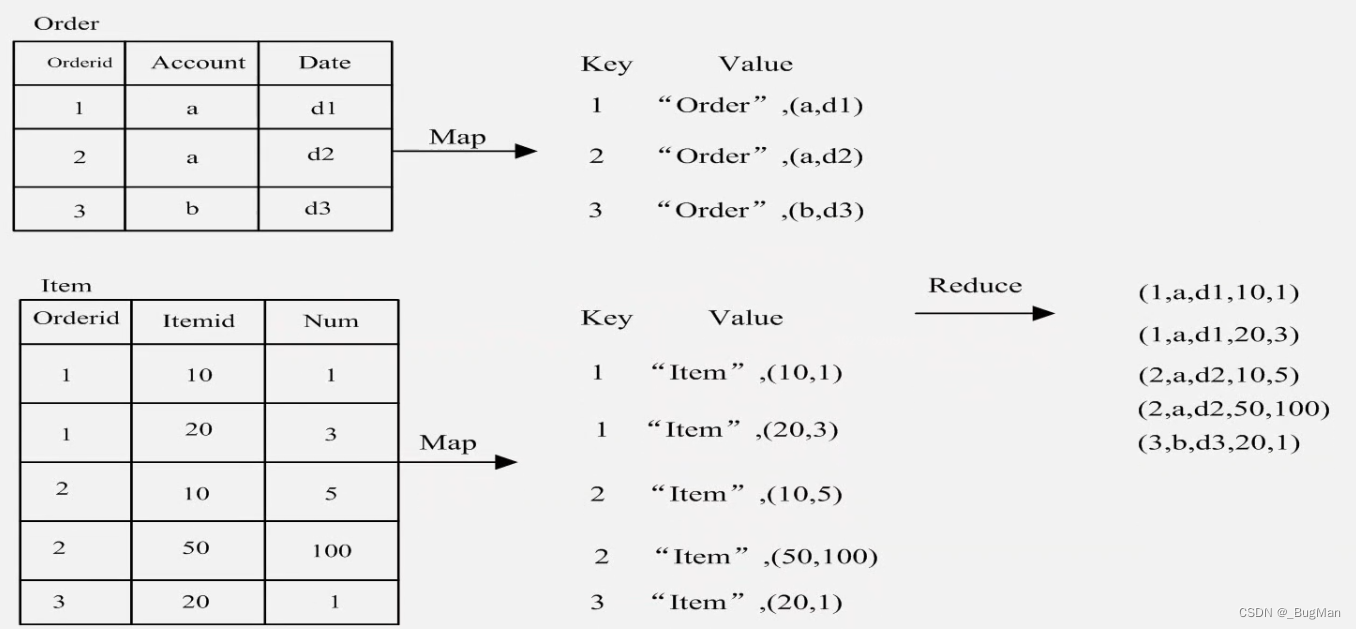
ok,我们知道了MapReduce能将数据关联在一起,那么MapReduce能做的事情可就太多了。回想一下类比我们在用关系型数据库时,想对数据进行统计分析,是不是其实就是将数据连接聚合在一起。所以我们说MapReduce可以完成一切对于数据的关系运算,也就是完成一切对于数据的计算任务。
下面举几个具体在行业内落地的应用场景:
1.搜索引擎的网页索引:
网页爬虫抓取大量网页内容。
Map阶段:解析每个网页,提取关键词,生成键值对(关键词, 网页URL)。
Reduce阶段:对关键词进行聚合,生成倒排索引,即每个关键词对应一组包含该关键词的网页列表。
2.用户行为分析:
收集用户在网站上的浏览、点击、购买等行为数据。
Map阶段:将每个事件转化为键值对(用户ID, 行为详情)。
Reduce阶段:按用户ID聚合,统计用户的总访问次数、购买行为、最常访问的页面等。
3.广告效果评估:
分析广告展示、点击和转化数据。
Map阶段:处理广告日志,产生(广告ID, 展示次数/点击次数/转化次数)键值对。
Reduce阶段:计算每个广告的CTR(点击率)和ROI(投资回报率)。
4.社交网络分析:
计算用户之间的关系,如好友数、影响力等。
Map阶段:遍历用户关系数据,输出(用户A, 用户B)键值对表示A关注B。
Reduce阶段:对每个用户进行聚合,计算其关注者和被关注者的数量。
5.新闻热点检测:
分析新闻标题和内容,找出热门话题。
Map阶段:将每条新闻转化为(关键词, 新闻ID)键值对。
Reduce阶段:对关键词进行聚合,统计出现频率,找出出现最多的关键词。
6.图像处理:
大规模图像分类或标签生成。
Map阶段:对每张图片进行预处理,生成特征向量和对应的图像ID。
Reduce阶段:使用机器学习模型对特征向量进行分类或聚类。
7.金融领域:
信用评分模型的训练。
Map阶段:处理个人信用记录,形成(用户ID, 信用特征)键值对。
Reduce阶段:用这些特征训练模型,预测用户违约概率。
8.基因组学研究:
对大规模基因序列进行比对和变异检测。
Map阶段:将基因序列片段与参考基因组进行比对,输出匹配位置。
Reduce阶段:整合比对结果,确定变异位点。