织梦手机网站模板北京互联网公司有哪些
切片机制
默认的切片大小和块大小一致,切片的个数决定了MapTask的个数。
数据倾斜问题:如果某个切片的大小太小,会浪费了MapTask申请的CPU资源。
如果剩余数据长度大于128*1.1, 就切片成2份,否则就不进行切分了。
InputFormat基类
-
TextInputFormat:
TextInputFormat是默认的FileInputFormat实现类。按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量, LongWritable类型。 -
CombineTextInputFormat:
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。 -
CombineTextInputFormat切片机制
- 虚拟存储过程:将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较;
- 小于maxSplitSize:逻辑上划分1块
- 大于2*maxSplitSize:以最大值划分一块
- 介于之间时:均分为2块
- 切片过程
- 判断虚拟文件大小是否大于max切片大小
- 大于时,单独形成一个切片
- 小于时,跟下一个虚拟存储文件进行合并,共同形成一个切片。
- 虚拟存储过程:将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较;
MapReduce工作机制
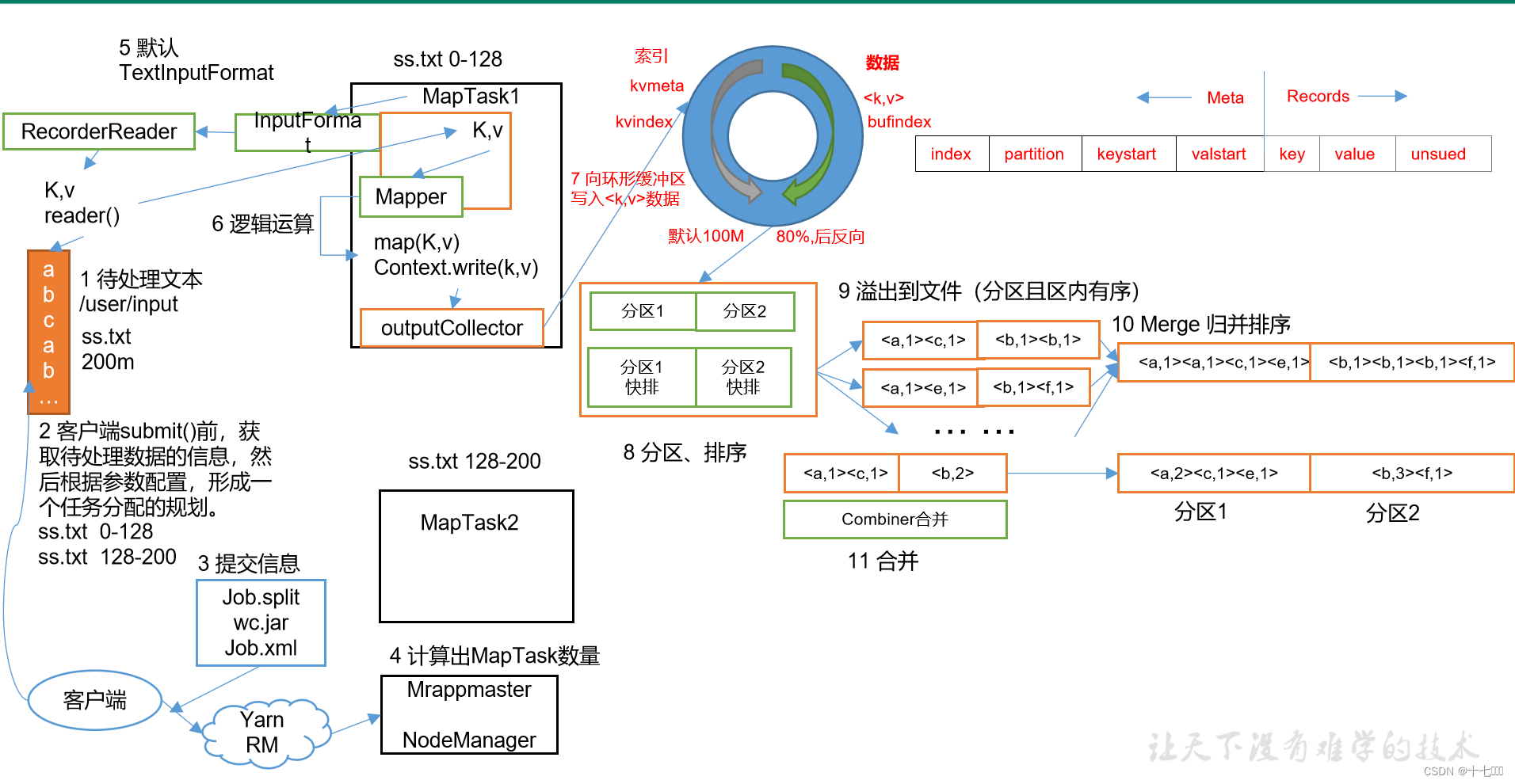
Map阶段
- 索引id是哈希和字典序的结合,形象上可以将索引id看做key来进行快排。
- 对索引id对索引进行快速排序
- 写入磁盘,需要按照分区进行写入,环形缓冲区排序后数据整体是有序的,分区写入时局部也是有序的。写入时是通过索引在环形缓冲区的右侧数据部分查找对应的数据。
- 环型缓冲区一般为100M,实际是指Map的读取数据写入缓冲区和缓冲区索引快排后溢写磁盘的那种往返行为,两者的方向是相反的,一般来说进行快排和溢写(是追加写)的速度是很快的,可以保证写入数据无需等待同时进行,提升效率。
- 先填充数据,到达80%时停止填充,进行快速排序后溢写数据到磁盘中,同时数据继续反向填充。
- Map在进行溢写后会产生很多局部有序的分区文件,将数据交付给Map前会先进行归并排序,将局部有序的分区文件合并为整体有序的分区数据。
Reduce阶段
copy:从不同Map中拉取分区后的数据sort:由于是不同Map中的数据,仍然是局部有序,整体无序的数据,Reduce需要将其进行归并排序成为整体有序的数据。reduce:进行数据的计算
Shuffle机制
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。
- Combiner操作:归并排序后有一次默认的合并操作,第二次合并需要考虑溢写的次数,由于combine合并时需要从磁盘读取数据,数据数量太少时进行合并效率并不高。
- Combiner操作是将计算过程提前到了Map阶段,由于Map阶段的数据量较少,一般情况下每次最多128M的数据,减少Reduce阶段的压力。
- 进行combiner操作后的结果会一部分放入内存,一部分放入磁盘,后续使用时需要分别进行归并排序合并总体结果,公共需要进行3次归并排序。
- 当设置reduceNum为0时,只有map阶段,没有reduce阶段,就没有shuffle阶段。
Partition分区
分区器
- 默认分区器
- 自定义分区器
机制
- 分区操作在map阶段之后
- key.hashCode() & Integer.MAX_VALUE去除负数
- reduce阶段中有默认分区器:
- 相同的key永远进入同一个分区
- 不同的key有可能进入不同分区
- 分区无论怎么算都不会有负数诞生,已经不会超过reduce的上限
- 如果对输出结果有具体的分区要求,需要定义分区,继承Partition类
- 根据业务逻辑定义分区数量
- 分区数量确定时,分区号已经确定了
- 如果分区数量大于返回的分区号,会导致reduce空转
- 如果reduce的数量小于返回的分区号,会报错
- 当分区数为1时,代码会使用默认的分区器
Combiner合并
- Combiner是MR程序中的Mapper和Reducer之外的一种组件
- Combiner组件的父类就是Reducer
- Combiner和Reducer的区别在于运行的位置
- Combiner是在每一个MapTask所在的节点运行
- Reducer是在ReduceTask节点运行 - 本质上代码都是一样的,可以直接使用原本的Reduce类作为Combiner类
- 如果将ReduceTask的数量设置为0,Combiner将直接不执行,输出结果连排序都没有做,在map阶段直接退出了。即shuffle和reduce两个过程都没有执行。
OutputFormat数据输出
基本上不需要自己实现,有很多现成的工具类,比如Flume, 除非您的公司有自己的文件系统,否则不需要自己操心。
总结
- MapTask做了什么?
- input = 切割 + 读取
- map:索引快排后缓冲区往返溢写
- sort:快排后写入磁盘
- ReduceTask做了什么?
- copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
- sort阶段:对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
- reduce阶段:进行数据的规约合并并将结果写入HDFS。