深圳福田区怎么样seo标题生成器
介绍Flink的安装、启动以及如何进行Flink程序的开发,如何运行部署Flink程序等
2.1 Flink的安装和启动
本地安装指的是单机模式
0、前期准备
- java8或者java11(官方推荐11)
- 下载Flink安装包 https://flink.apache.org/zh/downloads/
- hadoop(后面Flink on Yarn部署模式需要)
- 服务器(我是使用虚拟机创建了三个centos的实例hadoop102、hadoop103、Hadoop104)
1、本地安装(单机)
第一步:解压
[root@hadoop102 software]# tar -zxvf flink-1.17.1-bin-scala_2.12.tgz -C /opt/module/
第二步:启动
[root@hadoop102 bin]# cd /opt/module/flink-1.17.1/bin
[root@hadoop102 bin]# ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop102.
查看进程:
[root@hadoop102 ~]# jps
24817 StandaloneSessionClusterEntrypoint
25330 Jps
25117 TaskManagerRunner
有StandaloneSessionClusterEntrypoint和TaskManagerRunner就说明成功启动。
第三步:提交作业
# 命令
./flink run xxx.jar
Flink提供了一些示例程序,已经打成了jar包可直接运行
# 运行一个统计单词数量的Flink示例程序
[root@hadoop102 bin]# ./flink run ../examples/streaming/WordCount.jar# 查看输出
[root@hadoop102 bin]# tail ../log/flink-*-taskexecutor-*.out
(nymph,1)
(in,3)
(thy,1)
(orisons,1)
(be,4)
(all,2)
(my,1)
(sins,1)
(remember,1)
(d,4)
第四步:停止集群
[root@hadoop102 bin]# ./stop-cluster.sh
★★★ 在企业中单机模式无法支撑业务,所以都是以集群的方式安装,故后续内容都是以集群展开。
2、集群安装
(0)集群角色
为了更好理解安装配置过程,这里先提一下Flink集群的几个关键组件
三个关键组件:
-
客户端(JobClient):接收用户的代码,并做一些转换,会生成一个执行计划,这个执行计划我们也叫数据流(data flow),然后发送给JobManager去进行下一步的执行,执行完成后客户端会将结果返回给用户。客户端并不是Flink程序执行的内部组成部分,但它是执行的起点。
-
JobManager:主进程,Flink集群的“管事人”,对作业进行中央调度管理,主要职责包括计划任务、管理检查点、故障恢复等。获取到要执行的作业后,会做进一步的转换,然后分发给众多的TaskManager。
-
TaskManager:真正"干活"的人,数据的处理操作都是他们来做的。
(1)集群规划
| 节点服务器 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| 角色 | JobManager TaskManager | TaskManager | TaskManager |
(2)集群安装及启动
第一步:下载解压(见本地安装)
下载jar上传到hadoop102上,然后解压。如果本地安装已经操作则无需操作。
第二步:修改集群配置
进入conf目录:
/opt/module/flink-1.17.1/conf
a.进入conf目录,修改flink-conf.yaml文件
[root@hadoop102 conf]# vim flink-conf.yaml
以下几个地方需要修改:
# JobManager节点地址.
jobmanager.rpc.address: hadoop102
jobmanager.bind-host: 0.0.0.0
rest.address: hadoop102
rest.bind-address: 0.0.0.0
# TaskManager节点地址.需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: hadoop102
b.workers指定hadoop102、hadoop103和hadoop104为TaskManager
[root@hadoop102 conf]# vim workers
修改为:
hadoop102
hadoop103
hadoop104
c.修改masters文件,指定hadoop102为JobManager
[root@hadoop102 conf]# vim masters
hadoop102:8081
在flink-conf.yaml文件中还可以对集群中的JobManager和TaskManager组件进行优化配置,可先自行了解下
主要配置项如下:
- jobmanager.memory.process.size
- taskmanager.memory.process.size
- taskmanager.numberOfTaskSlots
- parallelism.default
第三步:发送到其它所有服务器(hadoop103、Hadoop04)
[root@hadoop102 module]# scp -r flink-1.17.1 root@hadoop103:/opt/module/
[root@hadoop102 module]# scp -r flink-1.17.1 root@hadoop104:/opt/module/
hadoop103、hadoop104配置修改 taskmanager.host
[root@hadoop103 conf]# vim flink-conf.yaml
taskmanager.host: hadoop103[root@hadoop104 conf]# vim flink-conf.yaml
taskmanager.host: hadoop104
第四步:启动集群
hadoop102上执行start-cluster.sh
[root@hadoop102 bin]# ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop103.
Starting taskexecutor daemon on host hadoop104.
查看进程:
[root@hadoop102 bin]# jps
28656 TaskManagerRunner
28788 Jps
28297 StandaloneSessionClusterEntrypoint[root@hadoop103 conf]# jps
4678 TaskManagerRunner
4750 Jps[root@hadoop104 ~]# jps
6593 TaskManagerRunner
6668 Jps
StandaloneSessionClusterEntrypoint:JobManager进程
TaskManagerRunner:TaskManager进程
访问WEB UI:http://hadoop102:8081/
第五步:停止集群
[root@hadoop102 bin]# ./stop-cluster.sh
2.2 Flink应用开发
开发工具:IDEA
0、创建项目
1)创建工程
(1)打开IntelliJ IDEA,创建一个Maven工程。
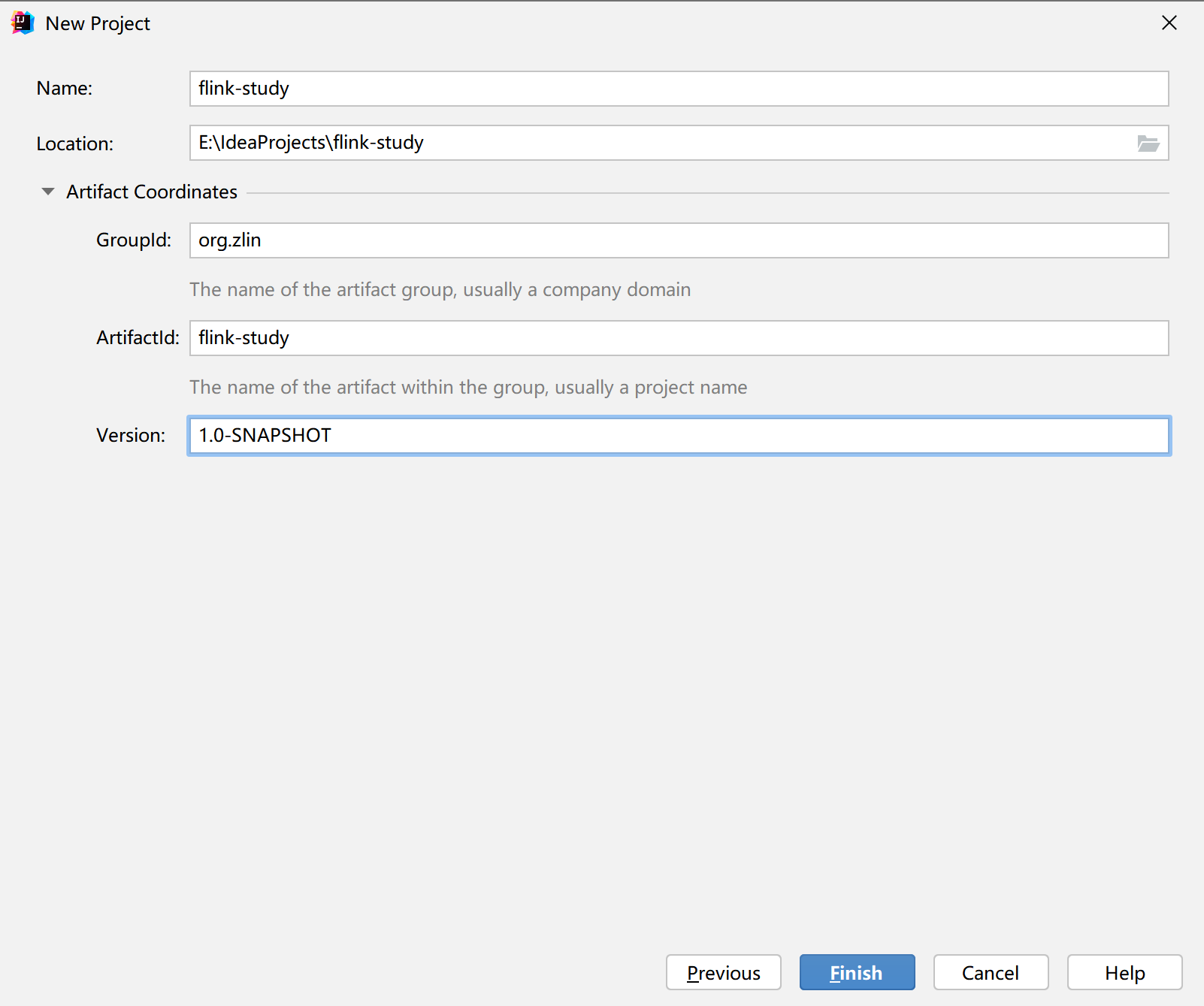
(2)填写项目信息
(3) 添加项目依赖
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.zlin</groupId><artifactId>flink-study</artifactId><packaging>pom</packaging><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><flink.version>1.17.0</flink.version><slf4j.version>2.0.5</slf4j.version></properties><dependencies><!-- Flink相关依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-files</artifactId><version>${flink.version}</version></dependency><!-- 日志管理相关依赖 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>2.19.0</version></dependency></dependencies></project>
1、代码编写(WordCount)
在开发中,如果我们有很多子项目,则可以创建一个个Module。相当于一个个子项目,这样结构清晰而且所有子项目都拥有父项目pom文件中的依赖。
需求:统计一段文字中,每个单词出现的频次。
环境准备:在src/main/java目录下,新建一个包,命名为com.atguigu.wc
这里也给出了批处理的代码,可以和流处理做下对比。
1.批处理
1)数据准备
工程目录下创建一个目录 input, 目录下创建一个文件,文件名随意,写一些单词
1.txt
hello udian hello flink
test test
2)代码编写
创建package com.zlin.wc 创建类BatchWordCount
package com.zlin.wc;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;/*** 单词统计(批处理)* @author ZLin* @since 2022/12/17*/
public class BatchWordCount {public static void main(String[] args) throws Exception {// 1. 创建执行环境ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 2. 从文件读取数据,按行读取DataSource<String> lineDs = env.readTextFile("input/");// 3. 转换数据格式FlatMapOperator<String, Tuple2<String, Long>> wordAndOnes = lineDs.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}).returns(Types.TUPLE(Types.STRING, Types.LONG));// 4. 按照word(下标为0)进行分组UnsortedGrouping<Tuple2<String, Long>> wordAndOneUg = wordAndOnes.groupBy(0);// 5. 分组内聚合统计AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUg.sum(1);// 6. 打印结果sum.print();}
}
3)输出
(java,1)
(flink,1)
(test,2)
(hello,2)
2.流处理
a.从文件读取
package com.zlin.wc;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.file.src.reader.TextLineInputFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.util.Collector;import java.util.Arrays;/*** 有界流* @author ZLin* @since 2022/12/19*/
public class BoundedStreamWordCount {public static void main(String[] args) throws Exception {// 1. 创建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 配置数据源FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineInputFormat(),new Path("input/")).build();// 3. 从数据源中读取数据DataStreamSource<String> lineDss = env.fromSource(fileSource, WatermarkStrategy.noWatermarks(),"file-source");// 4.转换格式 (word, 1L)SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDss.flatMap((String line, Collector<String> words) -> Arrays.stream(line.split(" ")).forEach(words::collect)).returns(Types.STRING).map(word -> Tuple2.of(word, 1L)).returns(Types.TUPLE(Types.STRING, Types.LONG));// 5. 按单词分组KeyedStream<Tuple2<String, Long>, String> wordAndOneKs = wordAndOne.keyBy(t -> t.f0);// 6. 求和SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKs.sum(1);// 7. 打印result.print();// 8. 执行env.execute("单词统计(有界流");}
}
输出:
(java,1)
(flink,1)
(test,2)
(hello,2)
b.从socket读取
package com.zlin.wc;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;import java.util.Arrays;/*** 单词统计(无界流)* @author ZLin* @since 2022/12/20*/
public class StreamWordCount {public static void main(String[] args) throws Exception {// 1. 创建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//2. 从socket读取文本流DataStreamSource<String> lineDss = env.socketTextStream("hadoop102", 7777);//3. 转换数据格式SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDss.flatMap((String line, Collector<String> words) -> Arrays.stream(line.split(" ")).forEach(words::collect)).returns(Types.STRING).map(word -> Tuple2.of(word, 1L)).returns(Types.TUPLE(Types.STRING, Types.LONG));//4. 分组KeyedStream<Tuple2<String, Long>, String> wordAndOneKs = wordAndOne.keyBy(t -> t.f0);//5. 求和SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKs.sum(1);//6. 打印result.print();//7. 执行env.execute("单词统计(无界流)");}
}
测试->在hadoop102中用 netcat 命令进行发送测试
nc -lk 7777注意:这里要先在hadoop102上先执行nc -lk 7777把端口打开,再在IDEA中运行程序,否则连不上端口会报错。
输出:
4> (hello,1)
2> (java,1)
4> (hello,2)
10> (flink,1)
7> (test,1)
7> (test,2)
2.3 Flink应用提交到集群
在IDEA中,我们开发完了项目后我们需要把我们的项目部署到集群中。
首先将程序打包:
(1)pom.xml文件添加打包插件的配置
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.1.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins>
</build>
点击Maven->你的moudle->package 进行打包,显示如下即打包成功。
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 15.263 s
[INFO] Finished at: 2022-12-22T00:53:50+08:00
[INFO] ------------------------------------------------------------------------Process finished with exit code 0可在target目录下看到打包成功的jar包

-with-dependencies是带依赖的,另一个是不带依赖的。
如果运行的环境中已经有程序所要运行的依赖则直接使用不带依赖的。
1. Web UI
点击+Add New上传我们的jar包,然后填写配置,最后点击提交
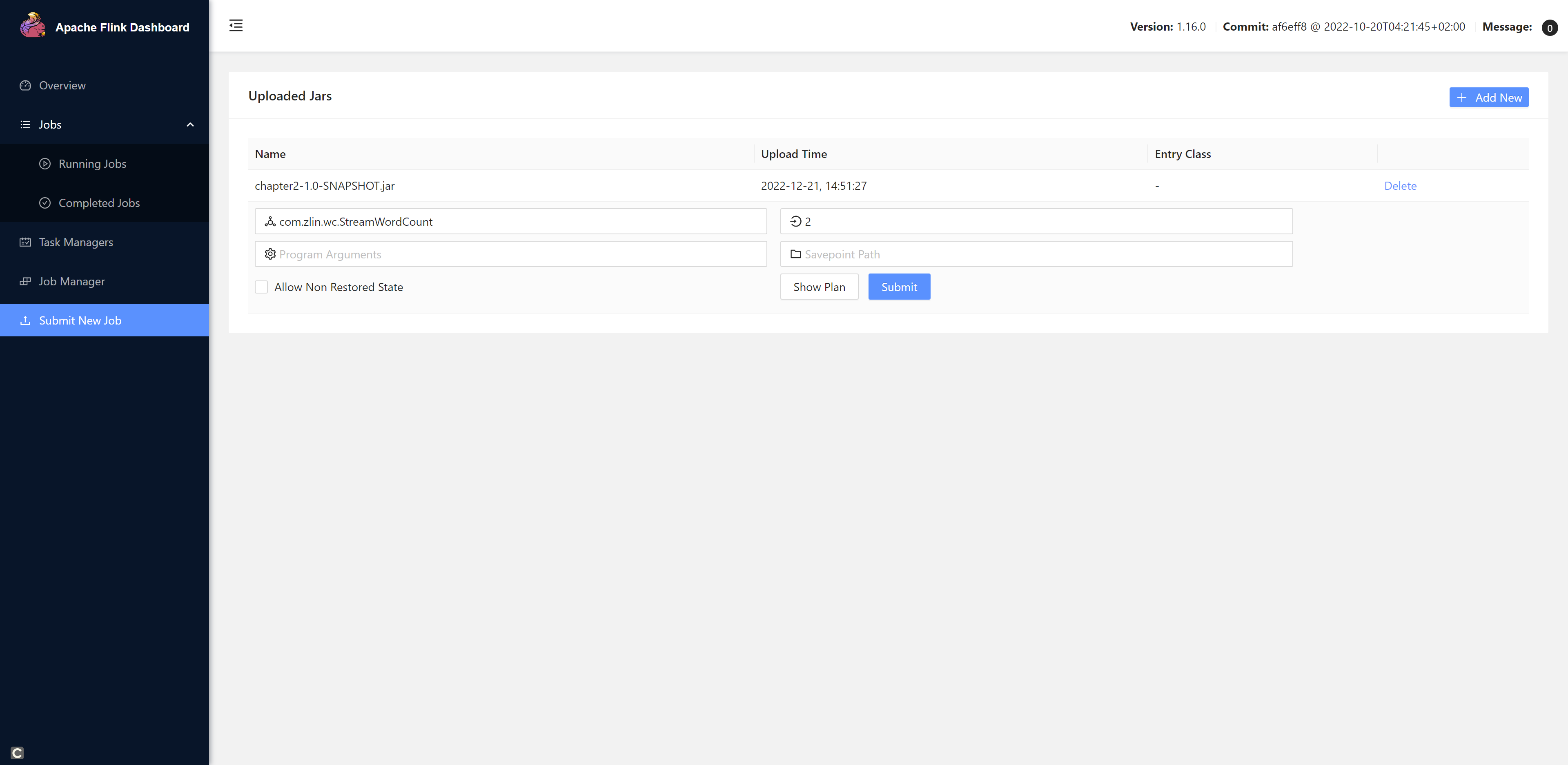
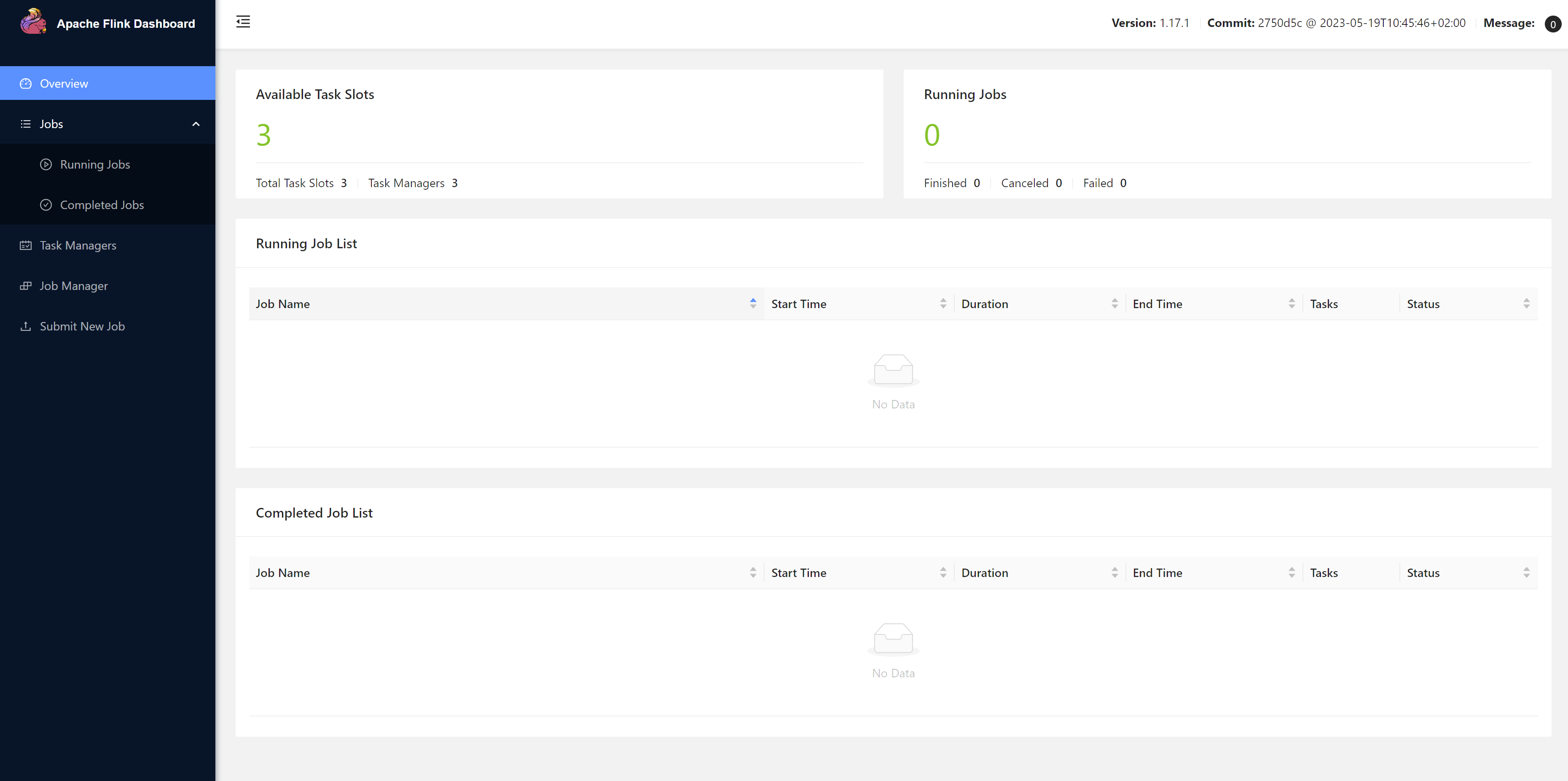
注意: 由于我们的程序是统计Hadoop102:7777这个端口发送过来的数据,所以我们需要先开启这个端口。不然程序提交会报错。
[root@hadoop102 bin]# nc -lk 7777之后我们再submit我们的任务。
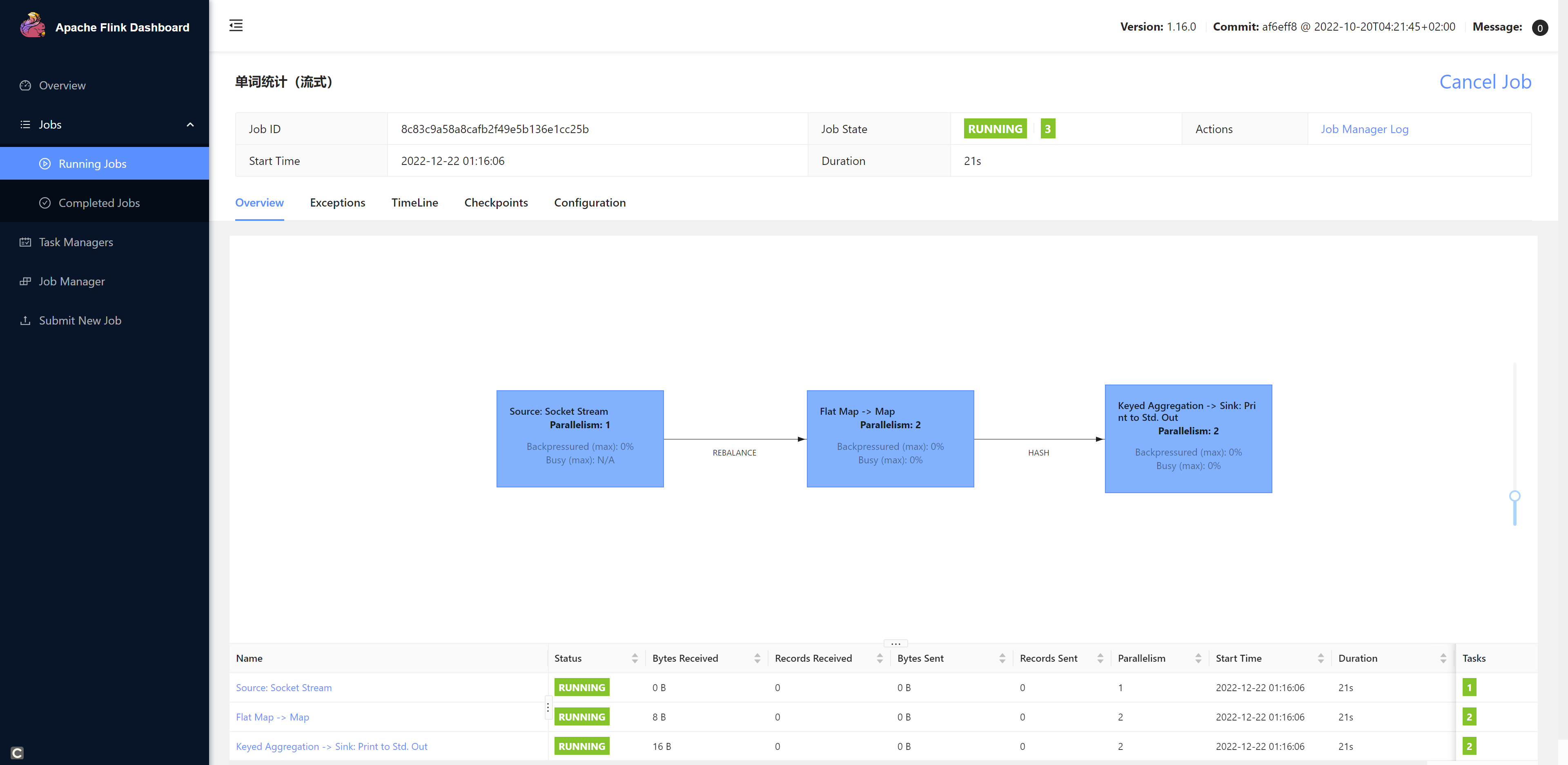
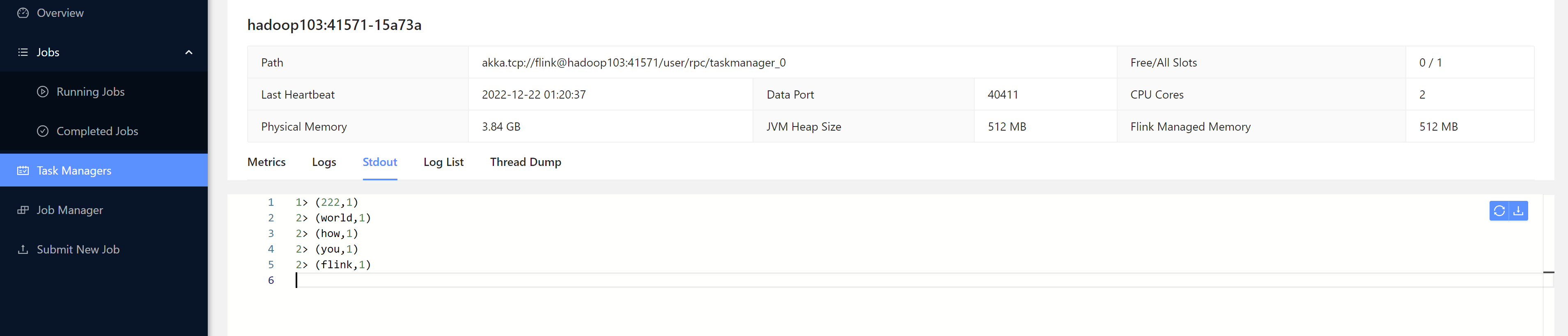
我们发送一些数据测试一下:
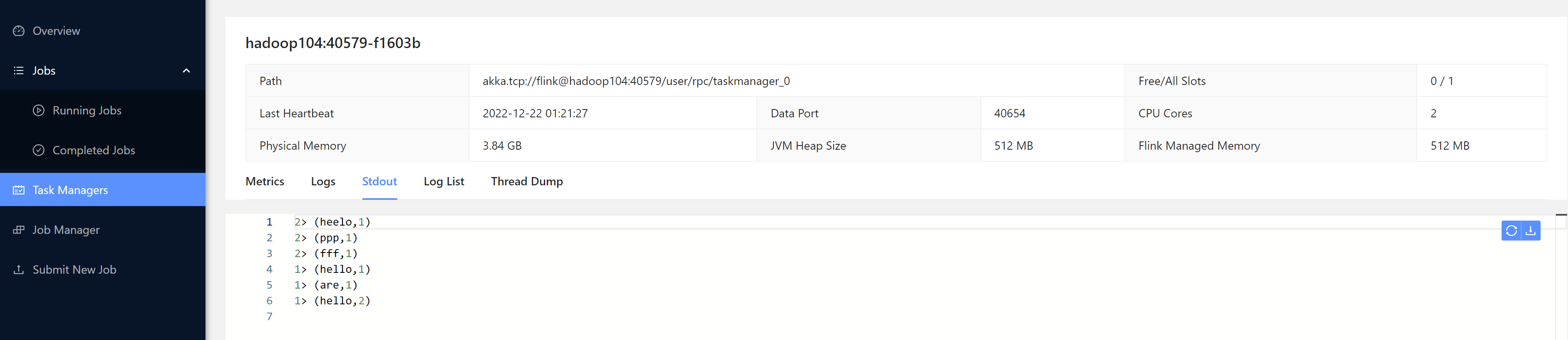
[root@hadoop102 bin]# nc -lk 7777
heelo 222
ppp
fff
hello world
how are you
hello flink
2. 命令行方式
确认flink集群已经启动
第一步:将jar包上传到服务器上
第二步:开启hadoop102:7777端口
[root@hadoop102 bin]# nc -lk 7777
第三步:提交作业
[root@hadoop102 jars]# flink run -m hadoop102:8081 -c com.zlin.wc.StreamWordCount ./chapter2-1.0-SNAPSHOT.jar
Job has been submitted with JobID f00421ad4c893deb17068047263a4e9e

发送一些数据
[root@hadoop102 bin]# nc -lk 7777
666
777
888