吉林省建设安全信息网官网seo关键词怎么选择
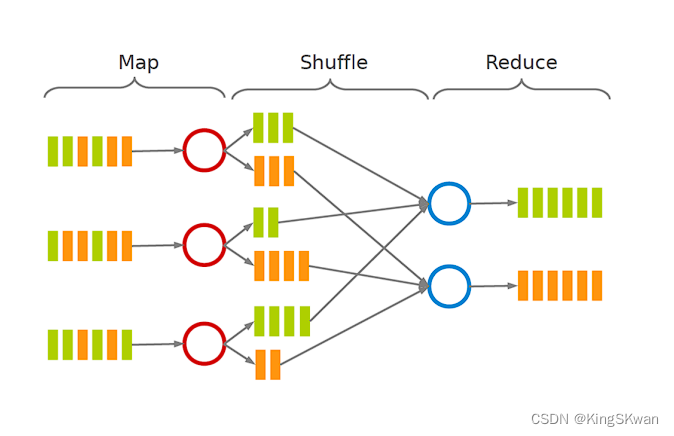
当谈到分布式计算和大数据处理时,MapReduce是一个经典的范例。它是一种编程模型和处理框架,用于在大规模数据集上并行运行计算任务。MapReduce包含三个主要阶段:Map、Shuffle 和 Reduce。
**
Map 阶段
**
Map 阶段是 MapReduce 的第一步,它负责将输入数据集分解成一系列键值对,并将这些键值对传递给各个 Mapper 函数进行处理。在 Map 阶段,用户自定义的 Map 函数会被并行应用于输入数据集中的每个元素。Map 函数的输出结果是一系列中间键值对,通常称为中间数据。
Map 阶段的工作原理可以概括为以下几个步骤:
数据分片: 输入数据集被划分成若干个大小合适的数据块,每个数据块被一个 Mapper 处理。
映射函数应用: 每个 Mapper 对数据块中的每个元素应用用户定义的映射函数。映射函数将每个输入元素转换为零个或多个中间键值对。
中间键值对生成: 映射函数的输出结果形成一系列中间键值对,其中键用于标识数据,值用于保存与键相关联的信息。
中间结果分发: 中间键值对被分发到后续的 Shuffle 阶段,以便根据键进行分组并传递给相应的 Reducer。
**
Shuffle 阶段
**
Shuffle 阶段是 MapReduce 中的一个关键步骤,它负责将 Map 阶段产生的中间键值对按键进行排序和分组,并将具有相同键的键值对传递给相同的 Reducer。Shuffle 阶段的主要任务是在不同的节点之间传输数据并进行合并操作,以便在 Reduce 阶段中能够高效地处理数据。
Shuffle 阶段的工作原理包括以下几个步骤:
分区: 根据中间键值对的键,对数据进行分区,将具有相同键的数据路由到同一个 Reducer。
排序: 在每个分区内部,对键值对按键进行排序,以便相同键的数据能够被紧密地聚集在一起。
合并: 对具有相同键的数据进行合并操作,以减少数据传输量和提高数据处理效率。
传输: 将分区后的数据传输给相应的 Reducer 节点,以便进行后续的 Reduce 操作。
**
Reduce 阶段
**
Reduce 阶段是 MapReduce 的最后一步,它负责将 Shuffle 阶段产生的分区数据集合并,并将具有相同键的键值对传递给用户定义的 Reduce 函数进行处理。Reduce 函数的输出结果是最终的计算结果。
Reduce 阶段的工作原理包括以下几个步骤:
数据传输: 接收到来自 Shuffle 阶段的分区数据。
合并: 将具有相同键的键值对合并为一个键值对列表,以便后续的处理。
Reduce 函数应用: 对每个键值对列表应用用户定义的 Reduce 函数,生成最终的计算结果。
结果输出: 将 Reduce 函数的输出结果写入到最终的输出数据存储中,完成整个 MapReduce 任务。
**
怎么理解MapReduce中的稳定存储到稳定存储的非循环数据流?
**
稳定存储到稳定存储的非循环数据流是指在分布式计算框架(比如MapReduce)中,数据在不同阶段之间的流动过程。在这种数据流模式下,数据从一个稳定的存储介质(例如磁盘)被读取,经过处理后再被写入到另一个稳定的存储介质中,而且数据的流动不会形成循环。
具体来说,在MapReduce中,这种数据流模式通常指的是数据在Map阶段的处理后,将中间结果写入到稳定的分布式文件系统(如HDFS),然后经过Shuffle和Reduce阶段的处理,最终的结果也会被写入到同样的稳定存储介质中。这里的稳定存储指的是持久性的、可靠的存储系统,例如分布式文件系统、数据库等。
非循环的含义是数据在处理过程中不会形成循环流动的情况,也就是说,数据流动的路径是单向的,没有反复读取和写入同一份数据的过程。这种模式的设计可以降低数据处理过程中的复杂性,提高系统的可靠性和性能。
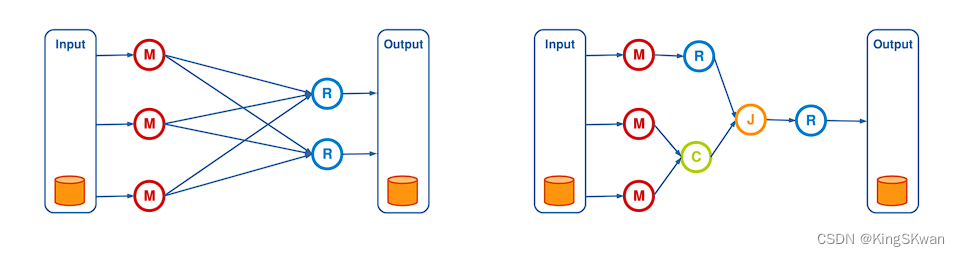
非循环数据流的优势
采用从稳定存储到稳定存储的非循环数据流模式具有以下几个优势:
- 数据可靠性: 数据在整个作业过程中都被存储在稳定的存储介质中,减少了数据丢失的风险。
- 性能优化:
通过将中间数据存储在稳定存储中,可以减少数据在节点之间的传输量,提高作业的处理性能。 - 作业容错:
在作业执行过程中,稳定存储可以帮助保持作业的状态,从而提高作业的容错能力。
**
了解MapReduce成本高昂的工作原理:磁盘与HDFS的不可或缺
**
在分布式计算中,MapReduce作为一种经典的并行计算框架,其设计初衷是为了能够有效地处理大规模数据集。然而,随着数据量的不断增加和任务的复杂性,MapReduce的成本问题也日益凸显。其中,成本高昂的一大原因是其常规实现方式总是倾向于频繁使用磁盘和HDFS(分布式文件系统),导致速度变慢。
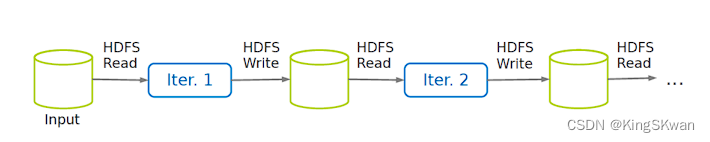
磁盘和HDFS的使用导致成本上升
- 频繁的磁盘读写操作:MapReduce的默认实现中,中间结果通常会被写入磁盘,以保证数据的持久性。然而,频繁的磁盘读写操作会导致IO开销增加,从而影响作业的整体性能。
- 数据的大规模传输:在Shuffle阶段,中间数据需要从Mapper传输到Reducer,而通常这些数据会存储在HDFS中。由于数据量庞大,需要进行大规模的数据传输,这也会增加网络带宽的压力,导致作业的执行速度变慢。
解决方案建议:优化数据处理与存储
- 内存计算:尽可能地减少对磁盘的依赖,采用内存计算的方式来提高数据处理速度。例如,可以将中间结果存储在内存中而不是写入磁盘,以减少IO开销。
- 增加节点和资源:通过增加集群节点和资源来提高作业的并行度,从而缩短作业的执行时间。这样可以分散数据处理的压力,加快数据的处理速度。
- 数据压缩和合并:在数据传输过程中,采用数据压缩和合并等技术来减少数据传输量,降低网络带宽的压力。