西宁网站建设君博推荐爱站网关键词挖掘
目录
前一章博客
前言
主函数的代码实现
逐行代码解析
获取链接
获取标题
获取网页源代码
获取各个文章的链接
函数的代码
导入库文件
获取文章的标题
获取文章的源代码
提取文章目录的各个文章的链接
总代码
下一章内容
前一章博客
用python从零开始做一个最简单的小说爬虫带GUI界面(1/3)_木木em哈哈的博客-CSDN博客而且当时的爬虫代码有许多问题但是最近学了PyQt5想着搞个带界面的爬虫玩玩那就啥也不说开搞!!!https://blog.csdn.net/mumuemhaha/article/details/132394257?spm=1001.2014.3001.5501
前言
前一章博客我们讲了怎么通过PyQt5来制作图形化界面,并且进行一些基本设置
接下来两章我们主要讲核心爬虫代码的实现

主函数的代码实现
前一章中的代码
self.Button_run.clicked.connect(self.F_run)代表点击按钮执行F_run函数(注意这里不要打括号)
那么我们就需要定义这个函数
思路大概就是这样
def F_run(self):link_1=self.line_link.text()title_1=F_gettitle(link_1)self.text_result.setText(f"标题获取成功——{title_1}")# file_1=open(f'{title_1}.txt',mode='w',encoding='utf-8 ')test_1=F_getyuan(link_1)self.text_result.setText("提取源代码成功")time.sleep(1)search_1=F_searchlink(test_1)self.text_result.append("提取文章链接成功")pachong(search_1,title_1)逐行代码解析
获取链接
首先通过
self.line_link.text()命令获取在输入框中输入的链接
并且把它赋值到link_1中
获取标题
同时我会通过爬取网页链接的源代码进行提取关键字获得文章的标题
也就是小说的名字
title_1=F_gettitle(link_1)获取网页源代码
爬取小说文章目录网页的源代码并且赋值为test_1(用于后续提取各个文章的链接)
test_1=F_getyuan(link_1)获取各个文章的链接
search_1=F_searchlink(test_1)把得到的源代码进行提取筛选获得各个文章的链接
其中self.text_result.setText以及self.text_result.append是在下面红圈中显示的东西
(美观用,可以不加)
函数的代码
这里为了不让代码过于长,我自己有单独新建了两个python文件用于存放python函数
导入库文件
import requests
import re
import numpy as np
from lxml import etreerequest用于网络请求
re以及lxml用于过滤源代码的信息
而numpy用于存储元素
获取文章的标题
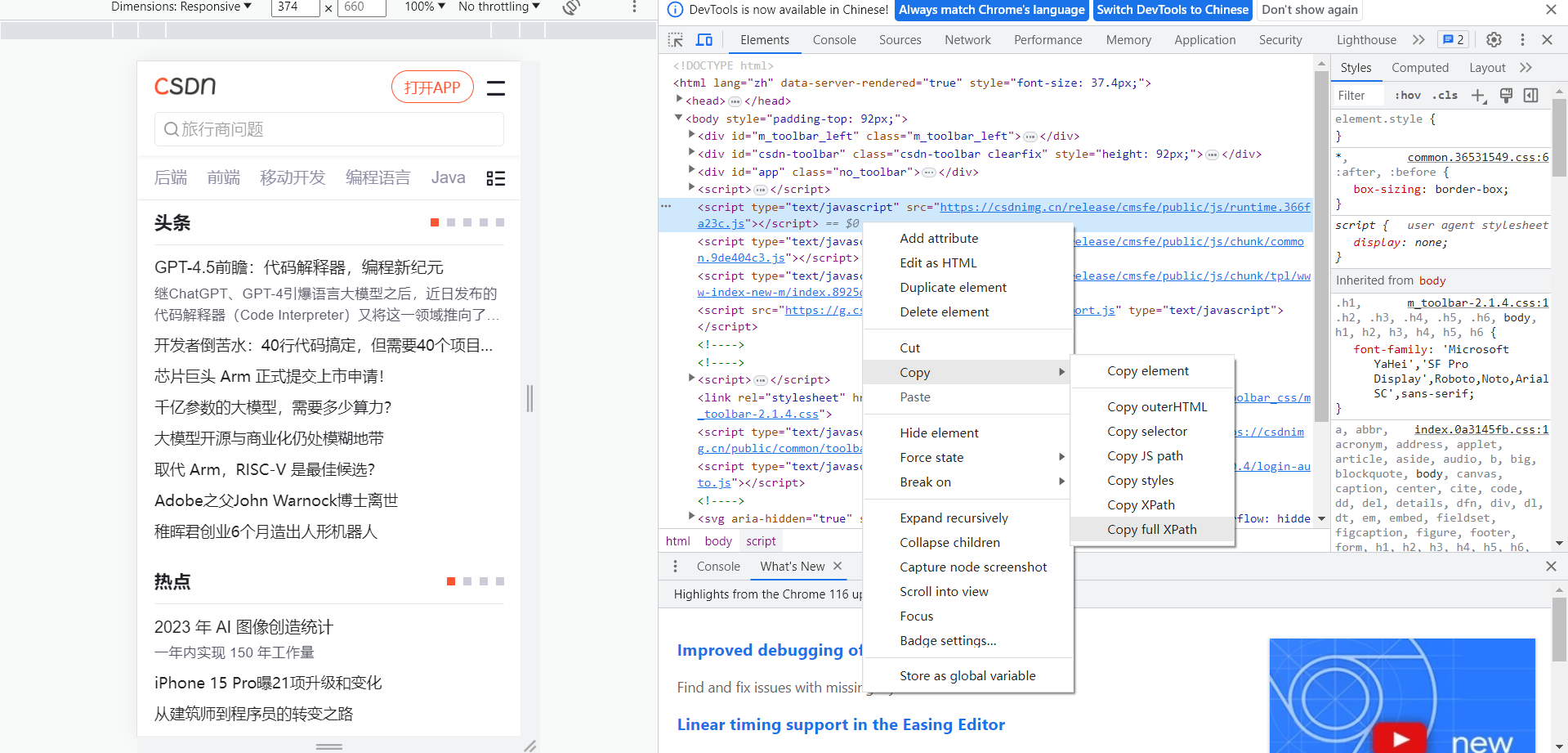
def F_gettitle(link_0):head_qb={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'}test_1=requests.get(url=link_0,headers=head_qb)test_yuan=test_1.textdom=etree.HTML(test_yuan)test_2=dom.xpath('/html/body/article[1]/div[2]/div[2]/h1/text()')return test_2[0]很简单的一个的结构
由requests来获取源代码
之后用lxml中的tree来筛选源代码
(用xpath路径时最后要加text()输出文本形式,不然出不了源代码)
xpath路径可以通过按f12控制台来提取
获取文章的源代码
应该很好理解,就直接写代码了
def F_getyuan(link_1):head_qb={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'}test_1=requests.get(url=link_1,headers=head_qb)test_yuan=test_1.texttest_yuan=str(test_yuan)return test_yuan提取文章目录的各个文章的链接
def F_searchlink(link_2):re_1='<a id="haitung" href="(.*?)" rel="chapter">'re_1=re.compile(re_1)link_3=re.findall(re_1,link_2)link_max=np.array([])for link_1 in link_3:link_4=f'http://www.biquge66.net{link_1}'link_max=np.append(link_max,link_4)return link_max这里我直接用re库的正则来进行匹配了匹配的链接
注意由于匹配的链接不是完整链接
所以还需要进行拼接
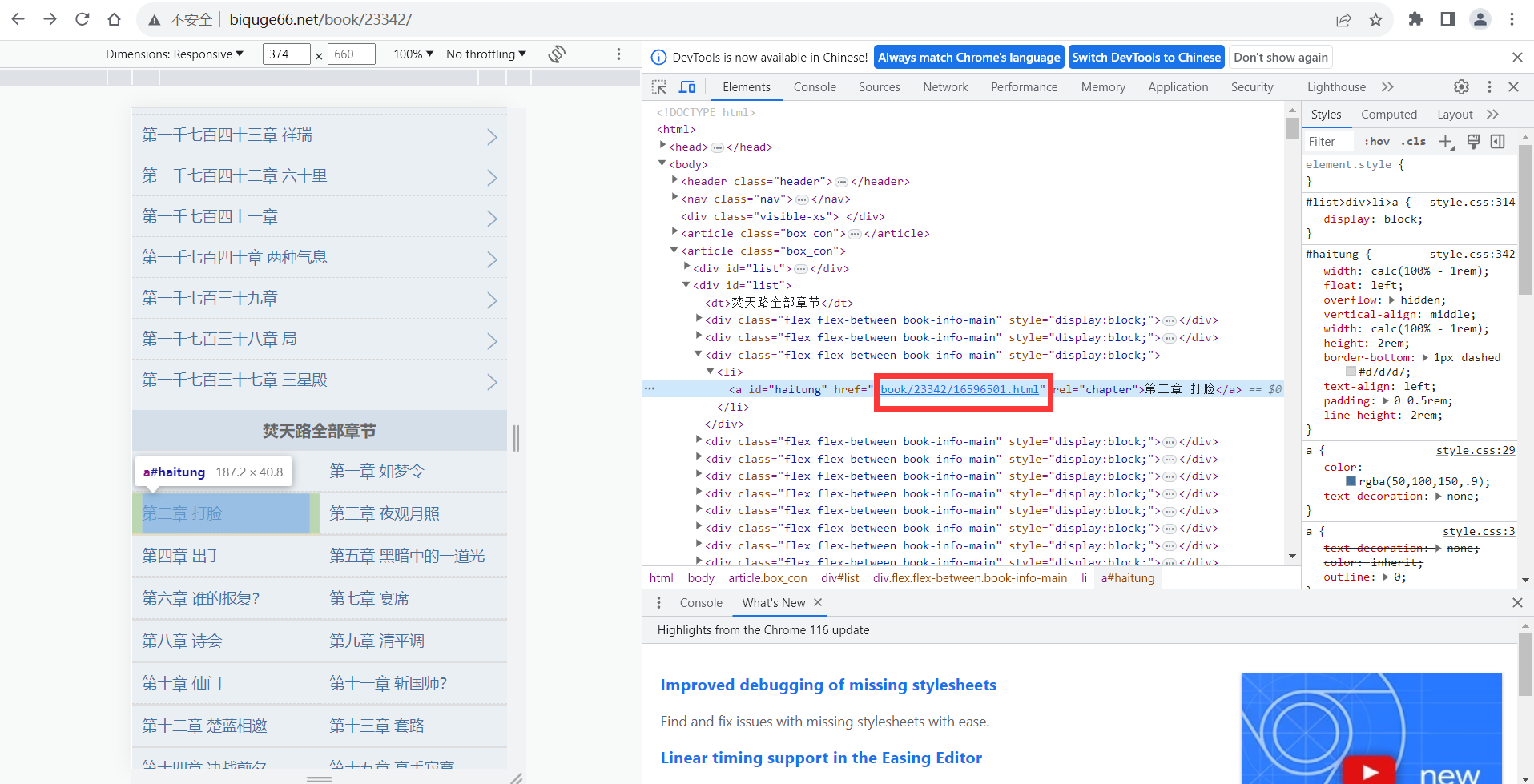
拼接完成后便可以直接打开
在这里我先存储到数组中方便之后爬取各个文章的源代码
然后进行返回
总代码
main.py
import sys
# PyQt5中使用的基本控件都在PyQt5.QtWidgets模块中
from PyQt5.QtWidgets import QApplication, QMainWindow
# 导入designer工具生成的login模块
from win import Ui_MainWindow
from test_1 import *
import time
class MyMainForm(QMainWindow, Ui_MainWindow):def __init__(self, parent=None):super(MyMainForm, self).__init__(parent)self.setupUi(self)self.Button_close.clicked.connect(self.close)self.Button_run.clicked.connect(self.F_run)def F_run(self):link_1=self.line_link.text()title_1=F_gettitle(link_1)self.text_result.setText(f"标题获取成功——{title_1}")# file_1=open(f'{title_1}.txt',mode='w',encoding='utf-8 ')test_1=F_getyuan(link_1)self.text_result.append("提取源代码成功")time.sleep(1)search_1=F_searchlink(test_1)self.text_result.append("提取文章链接成功")pachong(search_1,title_1)if __name__ == "__main__":# 固定的,PyQt5程序都需要QApplication对象。sys.argv是命令行参数列表,确保程序可以双击运行app = QApplication(sys.argv)# 初始化myWin = MyMainForm()# 将窗口控件显示在屏幕上myWin.show()# 程序运行,sys.exit方法确保程序完整退出。sys.exit(app.exec_())test_1.py
import requests
import re
import numpy as np
from lxml import etree
#获取文章标题
def F_gettitle(link_0):head_qb={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'}test_1=requests.get(url=link_0,headers=head_qb)test_yuan=test_1.textdom=etree.HTML(test_yuan)test_2=dom.xpath('/html/body/article[1]/div[2]/div[2]/h1/text()')return test_2[0]#提取源代码
def F_getyuan(link_1):head_qb={'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'}test_1=requests.get(url=link_1,headers=head_qb)test_yuan=test_1.texttest_yuan=str(test_yuan)return test_yuan#查询所有小说章节链接
def F_searchlink(link_2):re_1='<a id="haitung" href="(.*?)" rel="chapter">'re_1=re.compile(re_1)link_3=re.findall(re_1,link_2)link_max=np.array([])for link_1 in link_3:link_4=f'http://www.biquge66.net{link_1}'link_max=np.append(link_max,link_4)return link_max# #输出文章内容
# def F_edittxt(link_3):
# head_qb={
# 'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Mobile Safari/537.36'
# }
# trytimes = 3
# for i in range(trytimes):
# try:
# proxies = None
# test_1=requests.get(url=link_3,headers=head_qb, verify=False, proxies=None, timeout=3)
# if test_1.status_code == 200:
# break
# except:
# print(f'requests failed {i} time')
# #提取文章链接
# re_2='<p>(.*?)</p>'
# re_2=re.compile(re_2)
# #提取文章标题
# re_3='<h1 class="bookname">(.*?)</h1>'
# re.compile(re_3)
# test_2=np.array([])
# test_3=np.array([])
# test_2=re.findall(re_2,test_1.text)
# test_3 = re.findall(re_3, test_1.text)
# #放在数组的最后一个
# test_2=np.append(test_3,test_2)
# return test_2下一章内容
最后获取了所有的章节链接了,接下来就要爬取文章了
本来可以一起写的(可以看到我test_1.py中注释掉的部分),但是后面发现出了一些问题
才有了下一章内容
下一章会详细说明的