网站站点地图设计北京百度seo排名公司
系列文章
【如何训练一个中英翻译模型】LSTM机器翻译seq2seq字符编码(一)
【如何训练一个中英翻译模型】LSTM机器翻译模型训练与保存(二)
【如何训练一个中英翻译模型】LSTM机器翻译模型部署(三)
【如何训练一个中英翻译模型】LSTM机器翻译模型部署之onnx(python)(四)
训练一个翻译模型,我们需要一份数据集,以cmn.txt数据集为例:
取前两行数据来看看,如下:
Wait! 等等!
Hello! 你好。
对于中译英,我们希望让网络输入:“Wait!”,输出:“等等!”,输入:“Hello!”,输出:“你好。”
那么问题来了,这样的数据要如何输入网络进行训练呢?
显然需要进行编码,大白话说就是用“0101…”这样的数据来表示这些文字(为了方便表达,后面称为字符)。
先假设,我们的训练数据只取第一行,那就是只有“Wait! 等等!”,那么,我们开始对它进行编码,读取cmn.txt文件,并取第一行数据中英文分别保存在target_texts ,input_texts,,然后将所有的字符取出来,中英文字符并分别保存在target_characters ,input_characters
input_texts = [] # 保存英文数据集
target_texts = [] # 保存中文数据集
input_characters = set() # 保存英文字符,比如a,b,c
target_characters = set() # 保存中文字符,比如,你,我,她
with open(data_path, 'r', encoding='utf-8') as f:lines = f.read().split('\n')# 一行一行读取数据
for line in lines[: min(num_samples, len(lines) - 1)]: # 遍历每一行数据集(用min来防止越出)input_text, target_text = line.split('\t') # 分割中英文# We use "tab" as the "start sequence" character# for the targets, and "\n" as "end sequence" character.target_text = '\t' + target_text + '\n'input_texts.append(input_text)target_texts.append(target_text)for char in input_text: # 提取字符if char not in input_characters:input_characters.add(char)for char in target_text:if char not in target_characters:target_characters.add(char)input_characters = sorted(list(input_characters)) # 排序一下
target_characters = sorted(list(target_characters))
num_encoder_tokens = len(input_characters) # 英文字符数量
num_decoder_tokens = len(target_characters) # 中文文字数量
max_encoder_seq_length = max([len(txt) for txt in input_texts]) # 输入的最长句子长度
max_decoder_seq_length = max([len(txt) for txt in target_texts])# 输出的最长句子长度print('Number of samples:', len(input_texts))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)
可以得到这样的数据:
#原始数据:Wait! 等等!input_texts = ['Wait!']
target_texts = ['\t等等!\n']input_characters = ['!', 'W', 'a', 'i', 't']
target_characters = ['\t', '\n', '等', '!']
然后我们就可以开始编码啦。
先对input_characters 于target_characters 进行编号,也就是
['!', 'W', 'a', 'i', 't']0 1 2 3 4
['\t', '\n', '等', '!']0 1 2 3
代码如下:
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])
编号完之后就是:
input_token_index ={'!': 0,'W': 1,'a': 2,'i': 3,'t': 4}
target_token_index ={'\t': 0,'\n': 1,'等': 2,'!': 3}
有了input_token_index 与target_token_index ,我们就可以开始对输入输出进行编码,先来看输入。
假设我们的输入只有一个字符W,那么根据input_token_index 对W进行编码就如下:
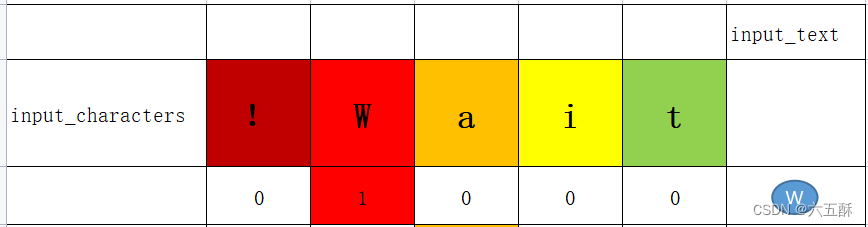
可看到W用向量01000表示了,只有W的那个位置被标为1,其余标为0
依次类推对Wait!进行编码,结果如下:
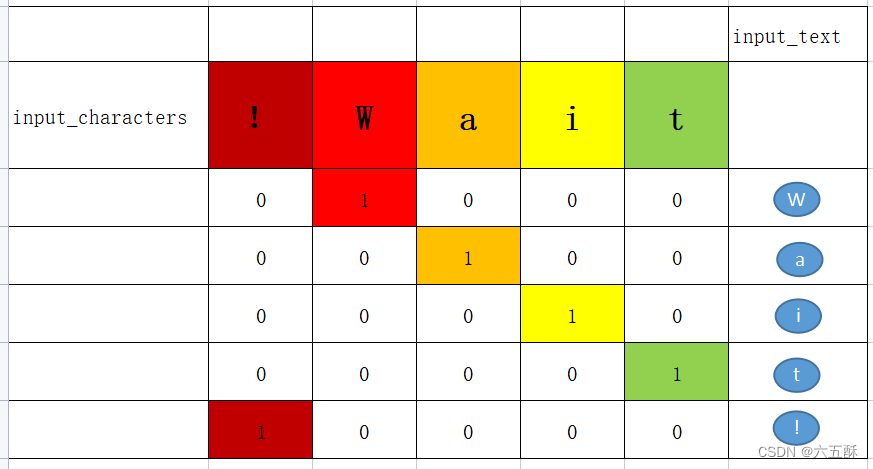
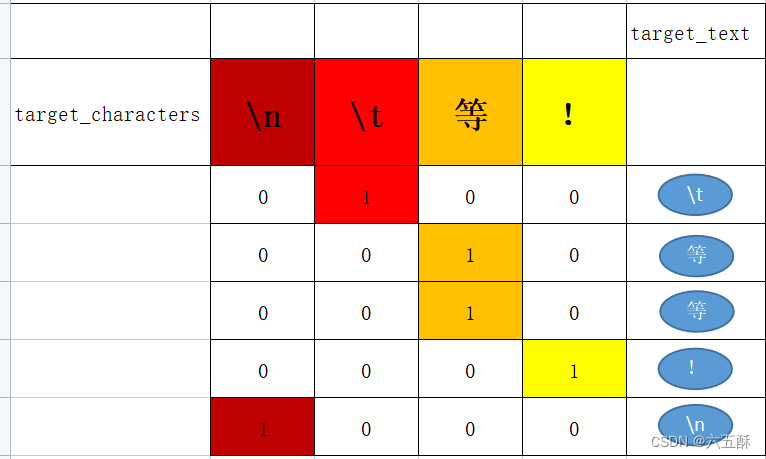
对中文进行编码也是一样的操作:
因此输入输出分别可以用encoder_input_data与decoder_input_data这两个矩阵来表示了,这两个矩阵里面的值是一堆01
['!', 'W', 'a', 'i', 't']
encoder_input_data
[[[0. 1. 0. 0. 0.] W[0. 0. 1. 0. 0.] a[0. 0. 0. 1. 0.] i[0. 0. 0. 0. 1.] t[1. 0. 0. 0. 0.]]] !target_texts通过编码得到
['\t', '\n', '等', '!']
decoder_input_data
[[[1. 0. 0. 0.] \t[0. 0. 1. 0.] 等[0. 0. 1. 0.] 等[0. 0. 0. 1.] ![0. 1. 0. 0.]]] \n
为了进一步说明,我们这时候将训练集改为2,也就是num_samples = 2,那么
input_texts = ['Wait!', 'Hello!']
target_texts = ['\t等等!\n', '\t你好。\n']
input_characters = ['!', 'H', 'W', 'a', 'e', 'i', 'l', 'o', 't']
target_characters = ['\t', '\n', '。', '你', '好', '等', '!']
分别对输入输出的内容进行编码,可得到:
encoder_input_data =
[[[0. 0. 1. 0. 0. 0. 0. 0. 0.] # 第一句 Wait![0. 0. 0. 1. 0. 0. 0. 0. 0.][0. 0. 0. 0. 0. 1. 0. 0. 0.][0. 0. 0. 0. 0. 0. 0. 0. 1.][1. 0. 0. 0. 0. 0. 0. 0. 0.][0. 0. 0. 0. 0. 0. 0. 0. 0.]][[0. 1. 0. 0. 0. 0. 0. 0. 0.] # 第二句 Hello[0. 0. 0. 0. 1. 0. 0. 0. 0.][0. 0. 0. 0. 0. 0. 1. 0. 0.][0. 0. 0. 0. 0. 0. 1. 0. 0.][0. 0. 0. 0. 0. 0. 0. 1. 0.][1. 0. 0. 0. 0. 0. 0. 0. 0.]]]decoder_input_data =
[[[1. 0. 0. 0. 0. 0. 0.] # 第一句 \t等等!\n[0. 0. 0. 0. 0. 1. 0.][0. 0. 0. 0. 0. 1. 0.][0. 0. 0. 0. 0. 0. 1.][0. 1. 0. 0. 0. 0. 0.]][[1. 0. 0. 0. 0. 0. 0.] # 第二句 \t你好。\n[0. 0. 0. 1. 0. 0. 0.][0. 0. 0. 0. 1. 0. 0.][0. 0. 1. 0. 0. 0. 0.][0. 1. 0. 0. 0. 0. 0.]]]
到这里,我们就清楚了这些文字用向量是怎么表示的,有了向量我们可以进行计算,也就是可以搭建一个网络来训练这些数据了,这个网络的输入是一堆0 1矩阵,输出也是一堆0 1矩阵,输入矩阵在输入字符那里索引得出这个矩阵是什么句子,而输出矩阵在输出字符那里索引得出这个句子代表什么句子,因此我们就可以来训练一个翻译模型了。
总结下来:翻译模型实际上就是输入一个0 1矩阵,输出另外一个0 1矩阵。
句子->输入矩阵->运算->输出矩阵->句子
下面是相应的代码:
# mapping token to index, easily to vectors
# 处理方便进行编码为向量
# {
# 'a': 0,
# 'b': 1,
# 'c': 2,
# ...
# 'z': 25
# }
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])# np.zeros(shape, dtype, order)
# shape is an tuple, in here 3D
encoder_input_data = np.zeros( # (12000, 32, 73) (数据集长度、句子长度、字符数量)(len(input_texts), max_encoder_seq_length, num_encoder_tokens),dtype='float32')
decoder_input_data = np.zeros( # (12000, 22, 2751)(len(input_texts), max_decoder_seq_length, num_decoder_tokens),dtype='float32')
decoder_target_data = np.zeros( # (12000, 22, 2751)(len(input_texts), max_decoder_seq_length, num_decoder_tokens),dtype='float32')# 遍历输入文本(input_texts)和目标文本(target_texts)中的每个字符,
# 并将它们转换为数值张量以供深度学习模型使用。
#编码如下
#我,你,他,这,国,是,家,人,中
#1 0 0 0 1 1 0 1 1,我是中国人
#1 0 1 0 0 1 1 1 0,他是我家人
# input_texts contain all english sentences
# output_texts contain all chinese sentences
# zip('ABC','xyz') ==> Ax By Cz, looks like that
# the aim is: vectorilize text, 3D
# zip(input_texts, target_texts)成对取出输入输出,比如input_text = 你好,target_text = you goodfor i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):for t, char in enumerate(input_text):# 3D vector only z-index has char its value equals 1.0encoder_input_data[i, t, input_token_index[char]] = 1.for t, char in enumerate(target_text):# decoder_target_data is ahead of decoder_input_data by one timestepdecoder_input_data[i, t, target_token_index[char]] = 1.if t > 0:# decoder_target_data will be ahead by one timestep# and will not include the start character.# igone t=0 and start t=1, meansdecoder_target_data[i, t - 1, target_token_index[char]] = 1.
在进行模型推理的时候,你同样需要相同的一份input_token_index 与target_token_index ,那么就需要将input_characters与target_characters保存下来,在推理之前,将你输入的内容进行编码,因为只有同一份位置编码,你的网络才能认识,要不然全乱套了,下面是将input_characters与target_characters保存为txt与读取的方法:
# 将 input_characters保存为 input_words.txt 文件
with open('input_words.txt', 'w', newline='') as f:for char in input_characters:if char == '\t':f.write('\\t\n')elif char == '\n':f.write('\\n\n')else:f.write(char + '\n')# 将 target_characters保存为 target_words.txt 文件
with open('target_words.txt', 'w', newline='') as f:for char in target_characters:if char == '\t':f.write('\\t\n')elif char == '\n':f.write('\\n\n')else:f.write(char + '\n')# 从 input_words.txt 文件中读取字符串
with open('input_words.txt', 'r') as f:input_words = f.readlines()input_characters = [line.rstrip('\n') for line in input_words]# 从 target_words.txt 文件中读取字符串
with open('target_words.txt', 'r', newline='') as f:target_words = [line.strip() for line in f.readlines()]target_characters = [char.replace('\\t', '\t').replace('\\n', '\n') for char in target_words]#字符处理,以方便进行编码
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])