手机版做我女朋友网站北京seo公司排名
前言
Python网络爬虫是利用Python编写的程序,通过自动化地访问网页、解析html或json数据,并提取所需信息的技术。下面将详细介绍一些与Python网络爬虫相关的重要知识点。
1、Python基础语法:
变量和数据类型:学习如何声明变量以及Python中的常用数据类型,如数字、字符串、列表、字典等。
- 条件语句和循环语句:掌握if语句、for循环和while循环,用于条件判断和循环执行代码块。2.函数和模块:了解如何定义和使用函数,以及如何使用Python的模块(库)来扩展功能 3.文件操作:学习如何读取和写入文件,可以用于存储和处理爬虫数据。
2、HTML网络结构:
- HTML基础:了解HTML的基本标签(如<html>、<head>、<body>等),了解标签的嵌套关系和属性的使用。
- CSS选择器:掌握通过CSS选择器定位网页元素,在爬虫中可以使用第三方库如BeautifulSoup、lxml来解析HTML,并提供灵活强大的CSS选择器功能。
3、JSON格式数据:
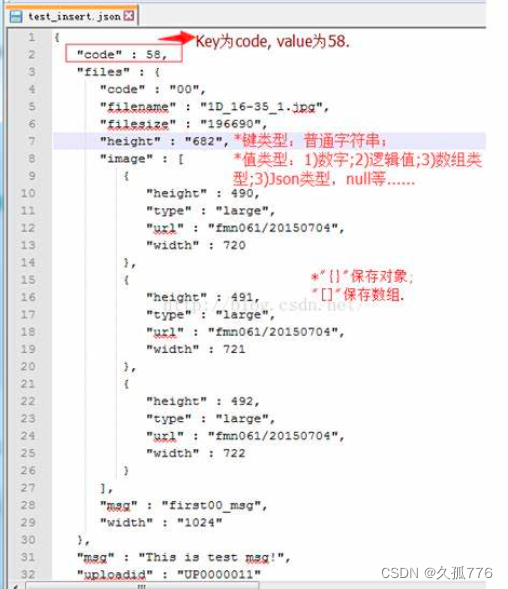
- JSON基础:了解JSON(JavaScript Object Notation)的基本语法和数据结构,包括对象、数组、键值对等。
- JSON解析:学习如何使用Python内置的json模块来解析和处理JSON数据,将其转换为Python对象进行操作。
4、爬虫流程:
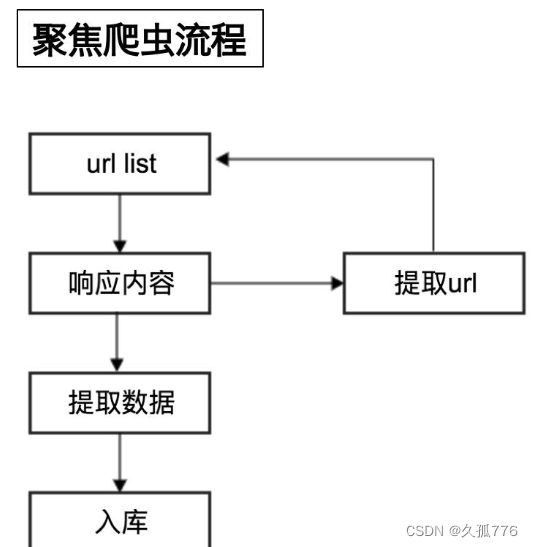
- 发起HTTP请求:使用Python中的第三方库(如Requests、urllib)发送HTTP请求,获取网页内容。
- 解析HTML或JSON:利用第三方库(如BeautifulSoup、lxml、json)解析HTML或JSON数据,提取目标信息。
- 数据处理与存储:对提取到的数据进行处理和清洗,可以使用Python内置的字符串处理方法,然后将数据存储到文件或数据库中。
- 反爬虫与限制:了解反爬虫机制,掌握绕过常见限制的方法,例如设置请求头信息、使用代理IP、处理验证码等。
5、实践案例:
- 爬取网页内容:利用Requests库发送HTTP请求,获得网页内容,并使用BeautifulSoup或lxml解析HTML,提取所需信息。
- 解析JSON数据:读取包含JSON格式数据的文件或通过HTTP请求获得JSON数据,使用Python的json模块解析数据并进行操作。