做网站的代码网站查询域名解析
Efficient Graph-Based Image Segmentation
- 一、完整代码
- 二、论文解读
- 2.1 GPT架构
- 2.2 GPT的训练方式
- Unsupervised pre_training
- Supervised fine_training
- 三、过程实现
- 3.1 导包
- 3.2 数据处理
- 3.3 模型构建
- 3.4 模型配置
- 四、整体总结
论文:Improving Language Understanding by Generative Pre-Training
作者:Alec Radford,Karthik Narasimhan,Tim Salimans,Ilya Sutskever
时间:2018
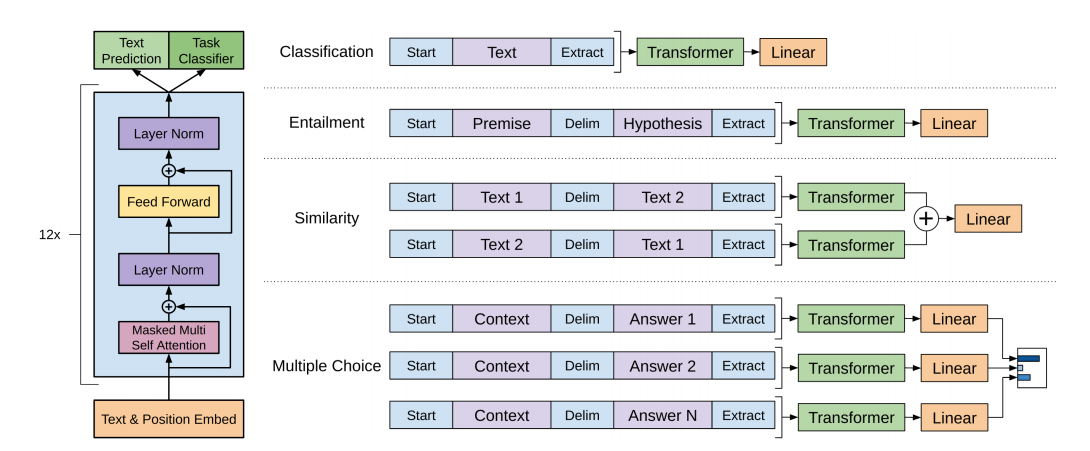
一、完整代码
这里我们使用tensorflow代码进行实现
# 完整代码在这里
import tensorflow as tf
import keras_nlp
import jsondef get_merges():with open('./data/GPT_merges.txt') as f:merges = f.read().split('\n')return mergesmerges = get_merges()
vocabulary = json.load(open('./data/GPT_vocab.json'))tokenizer = keras_nlp.tokenizers.BytePairTokenizer(vocabulary=vocabulary,merges=merges
)pad = tokenizer.vocabulary_size()
start = tokenizer.vocabulary_size() + 1
end = tokenizer.vocabulary_size() + 2corpus = open('./data/shakespeare.txt').read()
data = tokenizer(corpus)
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset = dataset.batch(63, drop_remainder=True)
def process_data(x):x = tf.concat([tf.constant(start)[tf.newaxis], x, tf.constant(end)[tf.newaxis]], axis=-1)return x[:-1], x[1:]dataset = dataset.map(process_data).batch(16)inputs, outputs = dataset.take(1).get_single_element()class GPT(tf.keras.Model):def __init__(self, vocabulary_size, sequence_length, embedding_dim, num_layers, intermediate_dim, num_heads, dropout=0.1):super().__init__()self.embedding = keras_nlp.layers.TokenAndPositionEmbedding(vocabulary_size=vocabulary_size,sequence_length=sequence_length,embedding_dim=embedding_dim,)self.lst = [keras_nlp.layers.TransformerDecoder(intermediate_dim=intermediate_dim,num_heads=num_heads,dropout=dropout,) for _ in range(num_layers)]self.dense = tf.keras.layers.Dense(vocabulary_size, activation='softmax')def call(self, x):decoder_padding_mask = x!= 0 output = self.embedding(x)for item in self.lst:output = item(output, decoder_padding_mask=decoder_padding_mask)output = self.dense(output)return outputvocabulary_size = tokenizer.vocabulary_size() + 3
sequence_length= 64
embedding_dim=512
num_layers=12
intermediate_dim=1024
num_heads=8gpt = GPT(vocabulary_size, sequence_length, embedding_dim, num_layers, intermediate_dim, num_heads)gpt(inputs)
gpt.summary()def masked_loss(label, pred):mask = label != padloss_object = tf.keras.losses.SparseCategoricalCrossentropy(reduction='none')loss = loss_object(label, pred)mask = tf.cast(mask, dtype=loss.dtype)loss *= maskloss = tf.reduce_sum(loss)/tf.reduce_sum(mask)return lossdef masked_accuracy(label, pred):pred = tf.argmax(pred, axis=2)label = tf.cast(label, pred.dtype)match = label == predmask = label != padmatch = match & maskmatch = tf.cast(match, dtype=tf.float32)mask = tf.cast(mask, dtype=tf.float32)return tf.reduce_sum(match)/tf.reduce_sum(mask)gpt.compile(loss=masked_loss,optimizer='adam',metrics=[masked_accuracy]
)gpt.fit(dataset, epochs=3)
二、论文解读
GPT全称为Generative Pre-Training,即生成式的预训练模型;
2.1 GPT架构
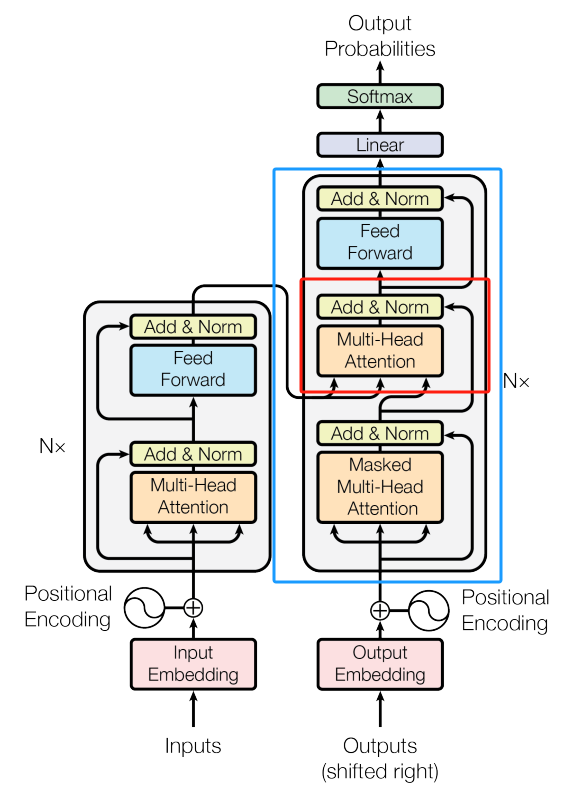
其模型架构非常简单,就是Transformer的decoder修正后的叠加,因为这是文本生成任务,并没有类似于seq2seq翻译模型的对应句子,GPT的处理方式是直接把Transformer中的decoder中的CrossAtention直接删除;
如图所示:蓝色方框部分为Transformer的decoder层,其中红色方框部分为被删除的多头注意力层;
得到的模型如下:
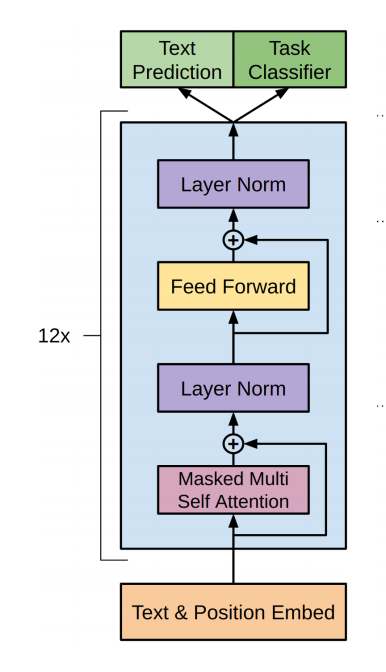
是不是特别简单;
2.2 GPT的训练方式
首先要声明的是GPT采用的是semi-supervised即半监督学习方法,其本质是一个两阶段的训练过程,第一阶段是无监督学习,就是单纯的利用Transformer的decoder来做预测下一个词的任务;第二阶段是有监督学习,利用带标签的语料信息对模型进行训练;
接下来对这两个过程进行详细的分析;
Unsupervised pre_training
原文如图所示:

其根本目的是最大化语言模型的极大似然估计,其本质就是一个链式法则取对数;
L 1 ( u ) = l o g ( P ( u i , u i − 1 , … , u 1 ) ) P ( u i , u i − 1 , … , u 1 ) = P ( u 1 ) ⋅ P ( u 2 ∣ u 1 ) ⋅ P ( u 3 ∣ u 2 , u 1 ) ⋅ ⋅ ⋅ P ( u i ∣ u i − 1 , … , u 1 ) \begin{aligned} & L_1(u) = log(P(u_i,u_{i-1},\dots,u_1)) \\ \\ & P(u_i,u_{i-1},\dots,u_1) = P(u_1)·P(u_2|u_1)·P(u_3|u_2,u_1)···P(u_i|u_{i-1},\dots,u_1) \end{aligned} L1(u)=log(P(ui,ui−1,…,u1))P(ui,ui−1,…,u1)=P(u1)⋅P(u2∣u1)⋅P(u3∣u2,u1)⋅⋅⋅P(ui∣ui−1,…,u1)
而下面计算 P P P 的过程,就是利用 mask 的机制来制造类似于RNN的过程;
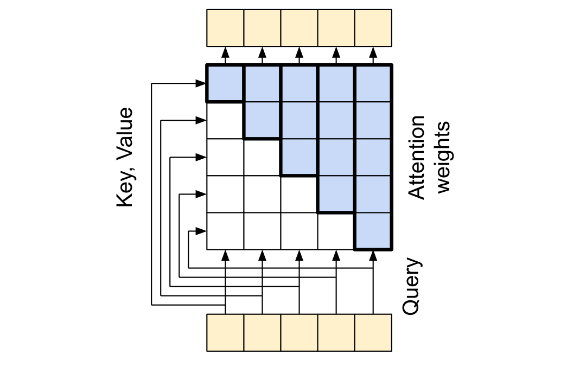
如果对注意力机制不理解的,可以去看一下Attention Is All You Need这篇论文,我也在其他博客中简单介绍了一下;
Supervised fine_training
原文如图所示:

与unsupervised pre_training不同的是,其去掉了最后一层的 W e W_e We换成了一个新的参数 W y W_y Wy,利用新的参数去预测新的标签;这里我的理解是这样的,在unsupervised pre_training中,我们相当于在大炮不停调整弹药量,大炮的对准方向 W e W_e We也在不停的向下一个单词调整;当弹药合理时,方向正确时,我们调整大炮方向去攻打supervised fine_tuning;
这里的目标函数进行了一次正则化处理,避免一味的调整方向而忽略了弹药量;
L 3 ( C ) = L 2 ( C ) + λ L 1 ( C ) L_3(C) = L_2(C) + \lambda L_1(C) L3(C)=L2(C)+λL1(C)
至此,模型的训练就结束了;
三、过程实现
3.1 导包
这里使用tensorflow,keras_nlp和json三个包进行过程实现;
import tensorflow as tf
import keras_nlp
import json
3.2 数据处理
第一部分是无监督训练,我们需要导入一段长文本构建数据集进行训练即可,这里我们使用莎士比亚的作品 storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt;
第二部分是有监督训练,我们可以使用CoLA语料进行文本分类,CoLA语料来自GLUE Benchmark中的The Corpus of Linguistic Acceptability;
def get_merges():with open('./data/GPT_merges.txt') as f:merges = f.read().split('\n')return mergesmerges = get_merges()
vocabulary = json.load(open('./data/GPT_vocab.json'))tokenizer = keras_nlp.tokenizers.BytePairTokenizer(vocabulary=vocabulary,merges=merges
)pad = tokenizer.vocabulary_size()
start = tokenizer.vocabulary_size() + 1
end = tokenizer.vocabulary_size() + 2corpus = open('./data/shakespeare.txt').read()
data = tokenizer(corpus)
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset = dataset.batch(63, drop_remainder=True)
def process_data(x):x = tf.concat([tf.constant(start)[tf.newaxis], x, tf.constant(end)[tf.newaxis]], axis=-1)return x[:-1], x[1:]dataset = dataset.map(process_data).batch(16)inputs, outputs = dataset.take(1).get_single_element()
# inputs
# <tf.Tensor: shape=(16, 64), dtype=int32, numpy=
# array([[50258, 5962, 220, ..., 14813, 220, 1462],
# [50258, 220, 44769, ..., 220, 732, 220],
# [50258, 16275, 470, ..., 220, 1616, 220],
# ...,
# [50258, 220, 1350, ..., 220, 19205, 198],
# [50258, 271, 220, ..., 54, 18906, 220],
# [50258, 10418, 268, ..., 40, 2937, 25]])>3.3 模型构建
在这里构建模型:
class GPT(tf.keras.Model):def __init__(self, vocabulary_size, sequence_length, embedding_dim, num_layers, intermediate_dim, num_heads, dropout=0.1):super().__init__()self.embedding = keras_nlp.layers.TokenAndPositionEmbedding(vocabulary_size=vocabulary_size,sequence_length=sequence_length,embedding_dim=embedding_dim,)self.lst = [keras_nlp.layers.TransformerDecoder(intermediate_dim=intermediate_dim,num_heads=num_heads,dropout=dropout,) for _ in range(num_layers)]self.dense = tf.keras.layers.Dense(vocabulary_size, activation='softmax')def call(self, x):decoder_padding_mask = x!= 0 output = self.embedding(x)for item in self.lst:output = item(output, decoder_padding_mask=decoder_padding_mask)output = self.dense(output)return outputvocabulary_size = tokenizer.vocabulary_size() + 3
sequence_length= 64
embedding_dim=512
num_layers=12
intermediate_dim=1024
num_heads=8gpt = GPT(vocabulary_size, sequence_length, embedding_dim, num_layers, intermediate_dim, num_heads)gpt(inputs)
gpt.summary()
构建模型结构如下:
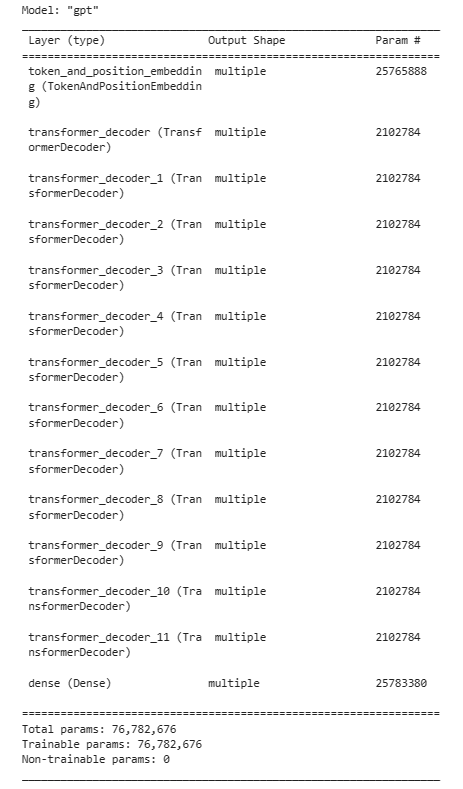
3.4 模型配置
模型配置如下:
def masked_loss(label, pred):mask = label != padloss_object = tf.keras.losses.SparseCategoricalCrossentropy(reduction='none')loss = loss_object(label, pred)mask = tf.cast(mask, dtype=loss.dtype)loss *= maskloss = tf.reduce_sum(loss)/tf.reduce_sum(mask)return lossdef masked_accuracy(label, pred):pred = tf.argmax(pred, axis=2)label = tf.cast(label, pred.dtype)match = label == predmask = label != padmatch = match & maskmatch = tf.cast(match, dtype=tf.float32)mask = tf.cast(mask, dtype=tf.float32)return tf.reduce_sum(match)/tf.reduce_sum(mask)gpt.compile(loss=masked_loss,optimizer='adam',metrics=[masked_accuracy]
)gpt.fit(dataset, epochs=3)
训练过程不知道为什么masked_accuracy一直不变,需要分析;

四、整体总结
模型结构很简单,但是在实现过程中出现了和Bert一样的问题;