佛山网站建设优化大师百科
目录
一、状态转化
二、kafka topic A→SparkStreaming→kafka topic B
(一)rdd.foreach与rdd.foreachPartition
(二)案例实操1
1.需求:
2.代码实现:
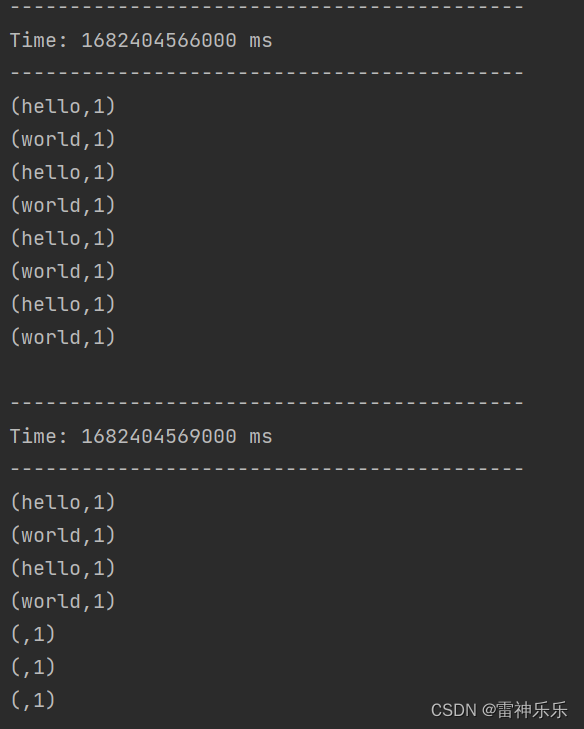
3.运行结果
(三)案例实操2
1.需求:
2.代码实现:
3.运行结果
三、WindowOperations
1.WindowOperations 窗口概述
2.代码示例
3.运行结果
一、状态转化
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。
有状态转化操作就是窗口与窗口之间的数据有关系。上次一UpdateStateByKey 原语用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例如流计算中累加 wordcount)。针对这种情况,updateStateByKey()为我们提供了对一个状态变量的访问,用于键值对形式的 DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指 定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}object SparkStreamingKafkaSource {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("sparkKafkaStream").setMaster("local[*]")val streamingContext = new StreamingContext(conf, Seconds(5))streamingContext.checkpoint("checkpoint")val kafkaParams = Map((ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "lxm147:9092"),(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.GROUP_ID_CONFIG -> "sparkstreamgroup1"))val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe(Set("sparkkafkastu"), kafkaParams))// TODO 无状态:每个窗口数据独立/*val wordCountStream: DStream[(String, Int)] = kafkaStream.flatMap(_.value().toString.split("\\s+")).map((_, 1)).reduceByKey(_ + _)wordCountStream.print()*/// TODO 有状态:窗口与窗口之间的数据有关系val sumStateStream: DStream[(String, Int)] = kafkaStream.flatMap(x => x.value().toString.split("\\s+")).map((_, 1)).updateStateByKey {case (seq, buffer) => {println("进入到updateStateByKey函数中")println("seqvalue:", seq.toList.toString())println("buffer:", buffer.getOrElse(0).toString)val sum: Int = buffer.getOrElse(0) + seq.sumOption(sum)}}sumStateStream.print()streamingContext.start()streamingContext.awaitTermination()}
}
有状态转化会将之前的历史记录与当前输入的数据进行计算:

二、kafka topic A→SparkStreaming→kafka topic B
(一)rdd.foreach与rdd.foreachPartition
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}import java.util/*** 将数据从kafka的topic A取出数据后加工处理,之后再输出到kafka的topic B中*/
object SparkStreamKafkaSourceToKafkaSink {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("sparkKafkaStream2").setMaster("local[*]")val streamingContext = new StreamingContext(conf, Seconds(5))streamingContext.checkpoint("checkpoint")streamingContext.checkpoint("checkpoint")val kafkaParams = Map( // TODO 连接生产者端的topic(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "lxm147:9092"),(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.GROUP_ID_CONFIG -> "kfkgroup2"))val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,// 如果没有topic需要创建// kafka-topics.sh --create --zookeeper lxm147:2181 --topic sparkkafkademoin --partitions 1 --replication-factor 1ConsumerStrategies.Subscribe(Set("sparkkafkademoin"), kafkaParams))println("1.配置spark消费kafkatopic")// TODO 使用foreachRDD太过消耗资源——不推荐kafkaStream.foreachRDD( // 遍历rdd => {println("2.遍历spark DStream中每个RDD")// 每隔5秒输出一次/* rdd.foreach(y => { // y:kafka中的keyValue对象println(y.getClass + " 遍历RDD中的每一条kafka的记录")val props = new util.HashMap[String, Object]()// TODO 连接消费者端的topicprops.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "lxm147:9092")props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")val producer = new KafkaProducer[String, String](props)val words: Array[String] = y.value().toString.trim.split("\\s+") // hello worldfor (word <- words) {val record = new ProducerRecord[String, String]("sparkkafkademoout", word + ",1")producer.send(record)}}) */rdd.foreachPartition(rdds => { // rdds是包含rdd某个分区内的所有元素println("3.rdd 每个分区内的所有kafka记录集合")val props = new util.HashMap[String, Object]() // TODO 连接消费者端的topicprops.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "lxm147:9092")props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")val producer = new KafkaProducer[String, String](props)rdds.foreach(y => {println("4.遍历获取rdd某一个分区内的每一条消息")val words: Array[String] = y.value().trim.split("\\s+")for (word <- words) {val record = new ProducerRecord[String, String]("sparkkafkademoout", word + ",1")producer.send(record)}})})})streamingContext.start()streamingContext.awaitTermination()}
}
(二)案例实操1
1.需求:
清洗前:
user , friends
3197468391,1346449342 3873244116 4226080662 1222907620清洗后:
user ,friends 目标topic:user_friends2
3197468391,1346449342
3197468391,3873244116
3197468391,4226080662
3197468391,1222907620
2.代码实现:
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}import java.utilobject SparkStreamUserFriendrawToUserFriend {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("sparkufStream2").setMaster("local[2]")val streamingContext = new StreamingContext(conf, Seconds(5))streamingContext.checkpoint("checkpoint")val kafkaParams = Map( // TODO 连接生产者端的topic(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "lxm147:9092"),(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.GROUP_ID_CONFIG -> "sparkuf3"),(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "earliest"))val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,// 如果没有topic需要创建// kafka-topics.sh --create --zookeeper lxm147:2181 --topic user_friends2 --partitions 1 --replication-factor 1ConsumerStrategies.Subscribe(Set("user_friends_raw"), kafkaParams))kafkaStream.foreachRDD(rdd => {rdd.foreachPartition(x => {val props = new util.HashMap[String, Object]() // TODO 连接消费者端的topicprops.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "lxm147:9092")props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")val producer = new KafkaProducer[String, String](props)x.foreach(y => {val splits: Array[String] = y.value().split(",")if (splits.length == 2) {val userid: String = splits(0)val friends: Array[String] = splits(1).split("\\s+")for (friend <- friends) {val record = new ProducerRecord[String, String]("user_friends2", userid + "," + friend)producer.send(record)}}})})})streamingContext.start()streamingContext.awaitTermination()}
}
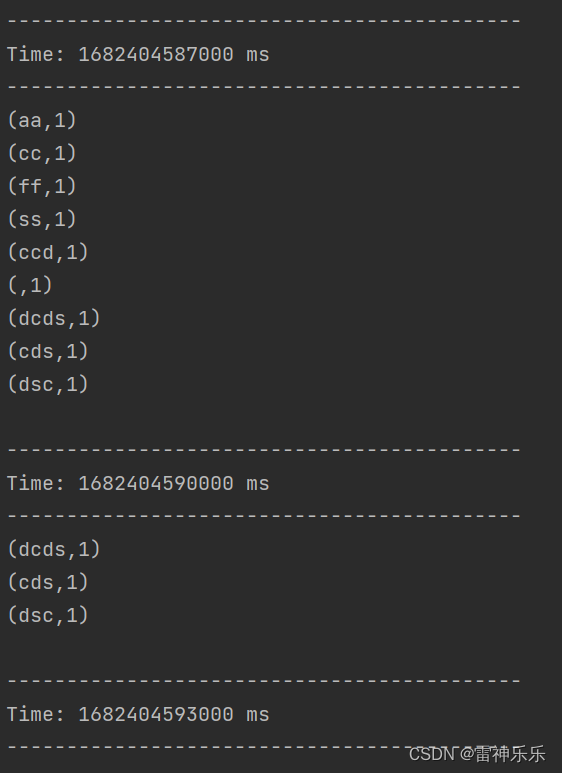
3.运行结果

(三)案例实操2
1.需求:
清洗前:
event , yes , maybe , invited ,no
1159822043,1975964455 3973364512,2733420590 ,1723091036 795873583,3575574655清洗前后:
eventid ,friendid ,status
1159822043,1975964455,yes
1159822043,3973364512,yes
1159822043,2733420590,maybe
1159822043,1723091036,invited1159822043,795873583,invited
1159822043,3575574655,no
2.代码实现:
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}import java.utilobject SparkStreamEventAttToEvent2 {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("sparkufStream2").setMaster("local[2]")val streamingContext = new StreamingContext(conf, Seconds(5))streamingContext.checkpoint("checkpoint")val kafkaParams = Map( // TODO 连接生产者端的topic(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "lxm147:9092"),(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.GROUP_ID_CONFIG -> "sparkevent"),(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "earliest"))val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,// 如果没有topic需要创建// kafka-topics.sh --create --zookeeper lxm147:2181 --topic event2 --partitions 1 --replication-factor 1ConsumerStrategies.Subscribe(Set("event_attendees_raw"), kafkaParams))kafkaStream.foreachRDD(rdd => {rdd.foreachPartition(x => {val props = new util.HashMap[String, Object]() // TODO 连接消费者端的topicprops.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "lxm147:9092")props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer")val producer = new KafkaProducer[String, String](props)x.foreach(y => { // todo 遍历获取rdd某一个分区内的每一条消息val splits: Array[String] = y.value().split(",")val eventID: String = splits(0)if (eventID.trim.nonEmpty) {if (splits.length >= 2) {val yesarr: Array[String] = splits(1).split("\\s+")for (yesID <- yesarr) {val yes = new ProducerRecord[String, String]("event2", eventID + "," + yesID + ",yes")producer.send(yes)}}if (splits.length >= 3) {val maybearr: Array[String] = splits(2).split("\\s+")for (maybeID <- maybearr) {val yes = new ProducerRecord[String, String]("event2", eventID + "," + maybeID + ",maybe")producer.send(yes)}}if (splits.length >= 4) {val invitedarr: Array[String] = splits(3).split("\\s+")for (invitedID <- invitedarr) {val invited = new ProducerRecord[String, String]("event2", eventID + "," + invitedID + ",invited")producer.send(invited)}}if (splits.length >= 5) {val noarr: Array[String] = splits(4).split("\\s+")for (noID <- noarr) {val no = new ProducerRecord[String, String]("event2", eventID + "," + noID + ",no")producer.send(no)}}}})})})streamingContext.start()streamingContext.awaitTermination()}
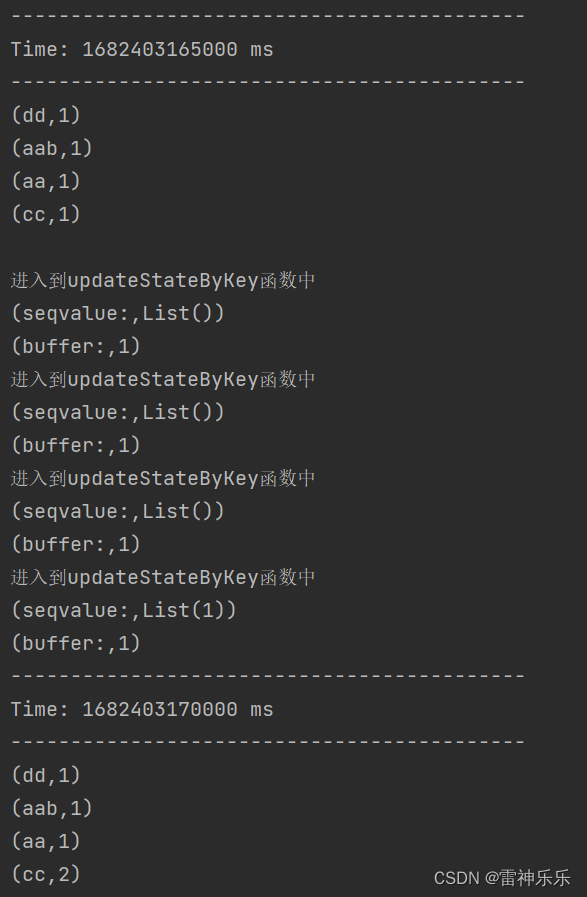
}3.运行结果

三、WindowOperations
1.WindowOperations 窗口概述
Window Operations 可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming 的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
➢ 窗口时长:计算内容的时间范围;
➢ 滑动步长:隔多久触发一次计算。
注意:这两者都必须为采集周期大小的整数倍。
2.代码示例
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}object SparkWindowDemo1 {def main(args: Array[String]): Unit = {val conf: SparkConf = new SparkConf().setAppName("sparkwindow1").setMaster("local[*]")val streamingContext = new StreamingContext(conf, Seconds(3))streamingContext.checkpoint("checkpoint")val kafkaParams = Map( // TODO 连接生产者端的topic(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "lxm147:9092"),(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer"),(ConsumerConfig.GROUP_ID_CONFIG -> "sparkwindow"),(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "latest"))val kafkaStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(streamingContext,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe(Set("sparkkafkastu"), kafkaParams))val winStream: DStream[(String, Int)] = kafkaStream.flatMap(x => x.value().trim.split("\\s+")).map((_, 1)).window(Seconds(9), Seconds(3))winStream.print()streamingContext.start()streamingContext.awaitTermination()}
}注意:window的步长不进行设置,默认是采集周期
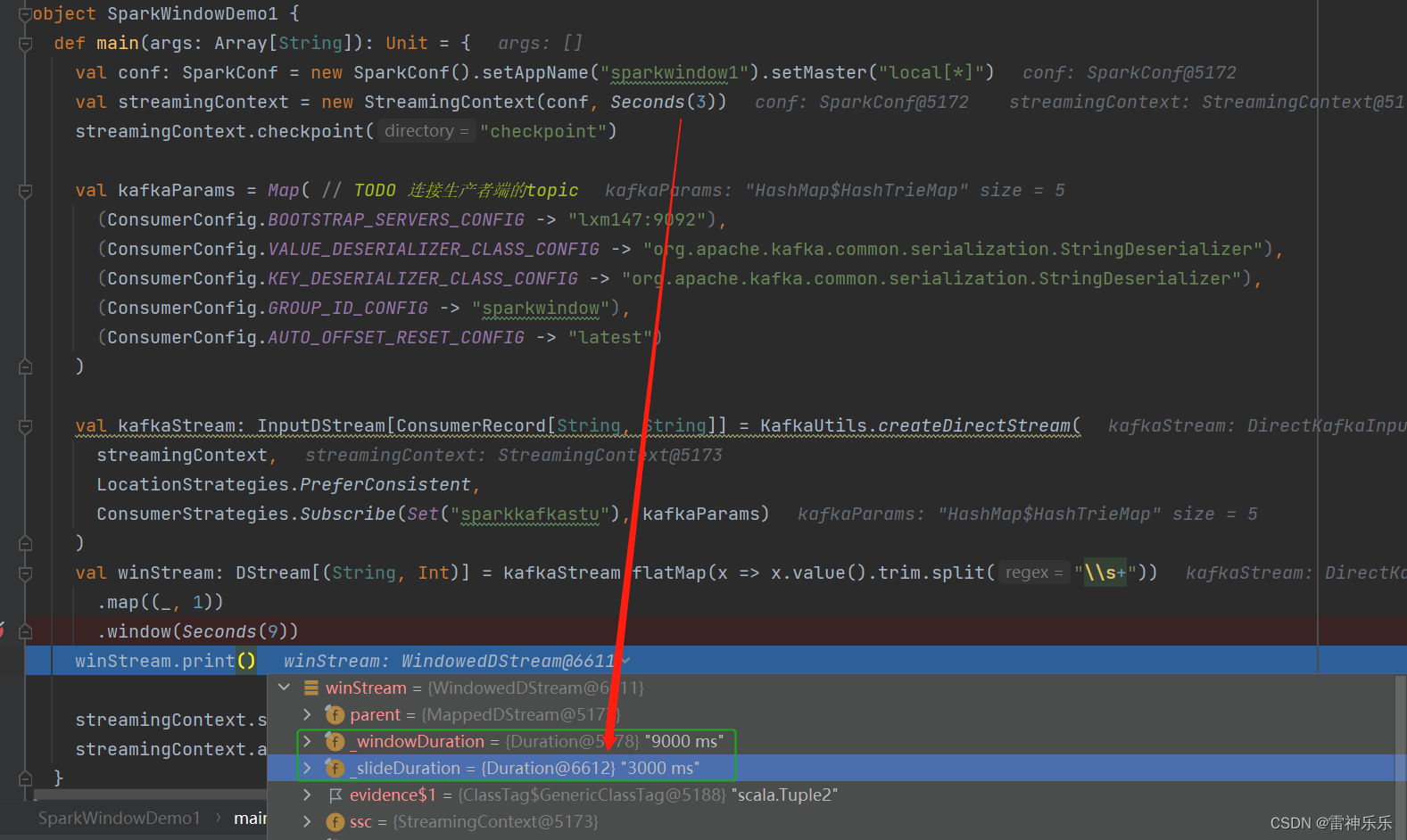
3.运行结果