建网站要seo搜索引擎优化方法
各种激活函数总结
目录
- 一、sigmoid
- 二、tanh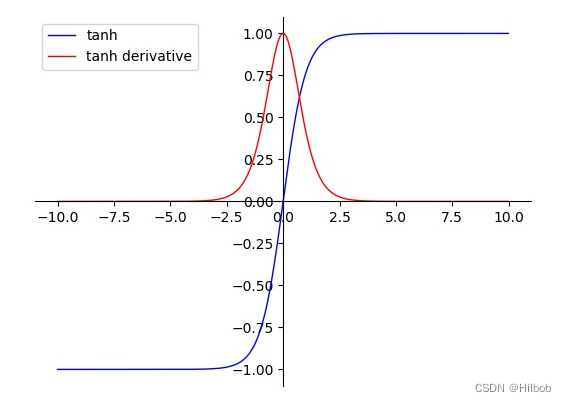
- 三、ReLU系列
- 1.原始ReLU
- 2.ReLU改进:Leaky ReLU
- 四、swish
- 五、GeLU
一、sigmoid

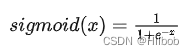
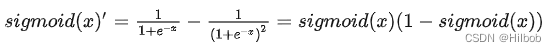
优点:
1.可以将任意范围的输出映射到 (0, 1) 范围内,表示它对每个神经元的输出进行了归一化,适合用于将概率作为输出的模型。
2.易于求导缺点
1.计算量大;
2.Sigmoid导数取值范围是[0, 0.25],且当x过大或过小时,sigmoid函数的导数接近于0,由于神经网络反向传播时的“链式反应”,容易造成梯度消失,难以更新网路参数。高层网络的误差相对第一层卷积的参数的梯度将是一个非常小的值,这就是所谓的“梯度消失”。
3.Sigmoid的输出不是0均值(即zero-centered);这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入,随着网络的加深,会改变数据的原始分布。
二、tanh
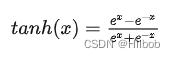
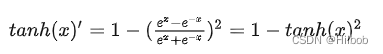
优点:
1.tanh的输出范围时(-1, 1),解决了sigmoid不是0均值输出问题;
2.在靠近0处的导数值较sigmoid更大,即神经网络的收敛速度相对于sigmoid更快;
3.在一般的分类问题中,可将tanh用于隐藏层,sigmoid 函数用于输出层。
缺点:
1.计算量大;
2.tanh导数范围在(0, 1)之间,相比sigmoid导数的范围(0, 0.25),梯度消失问题会得到缓解,但仍然存在。
三、ReLU系列
1.原始ReLU
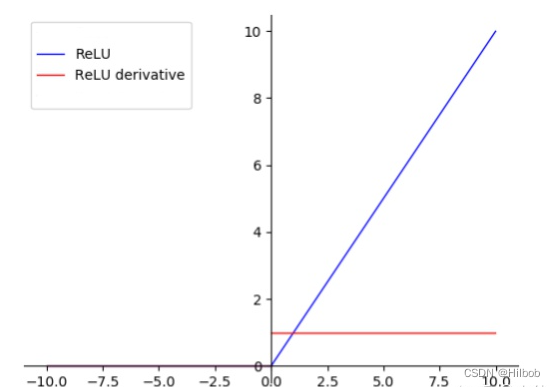
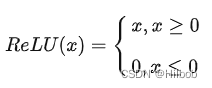
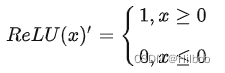
优点:
1.计算速度更快;
2.ReLU是非线性函数(所谓非线性,就是一阶导数不为常数;对ReLU求导,在输入值分别为正和为负的情况下,导数是不同的,即ReLU的导数不是常数,所以ReLU是非线性的,只是不同于sigmoid和tanh,ReLU的非线性不是光滑的);
2.梯度只有 0, 1 两个常量,有效地解决梯度消失的问题。
3.ReLU的单侧抑制(当ReLU的输入x为负时,ReLU输出为0)提供了网络的稀疏表达能力。(深度学习是根据大批量样本数据,从错综复杂的数据关系中,找到关键信息。换句话说,就是把密集矩阵转化为稀疏矩阵,去除噪音,保留数据的关键信息,这样的模型就有了鲁棒性。ReLU将x<0的输出置为0,就是一个去噪音,稀疏矩阵的过程。而且在训练过程中,这种稀疏性是动态调节的,网络会自动调整稀疏比例,保证矩阵具备最优的关键特征。)
缺点:
1.ReLU 函数不是zero-centered输出;。
2.训练过程中会导致神经元死亡的问题,即ReLU 强制将<0的输入置为0(屏蔽该特征),导致网络的部分神经元处于无法更新的状态,这种现象称为死亡 ReLU 问题 (Dying ReLU
Problem);
3.虽然采用ReLU在“链式反应”中不会出现梯度消失,但梯度下降的幅值就完全取决于权值的乘积,这样可能会出现梯度爆炸问题。 可以通过以下两种思路解决这类问题:一是控制权值的大小,让权值在(0,1)范围内;二是做梯度裁剪,控制梯度下降强度,如ReLU(x)=min(6, max(0,x))。
2.ReLU改进:Leaky ReLU
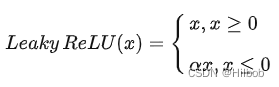
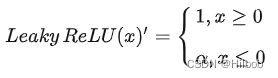
优点:
1.解决了ReLU的神经元死亡问题。Leaky ReLU中引入了超参数,一般设置为0.01。在反向传播过程中,对于Leaky ReLU的输入小于零的情况,也可以计算得到一个梯度(而不是像ReLU一样值为0)。
缺点:
1.相较于ReLU,神经网络的稀疏性要差一些;
2.引入了额外的超参数。
四、swish
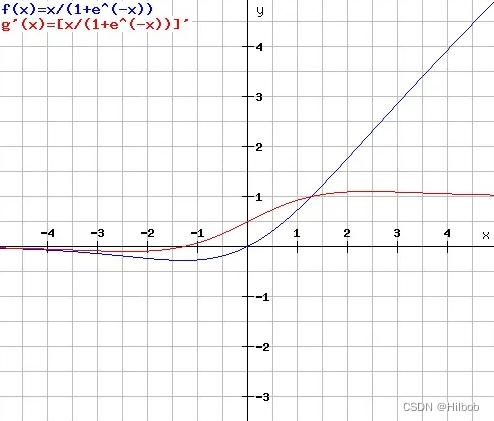
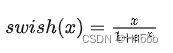
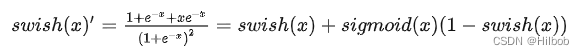
优点:
1.Swish是通过NAS搜索得到的,其取值范围是[-0.278, +∞),且平滑、非单调;
2.Swish 在深层模型上的效果优于 ReLU。例如,仅仅使用 Swish 单元替换 ReLU 就能把 Mobile NASNetA 在 ImageNet 上的 top-1 分类准确率提高 0.9%,Inception-ResNet-v 的分类准确率提高 0.6%。
缺点:
1.计算量大
五、GeLU
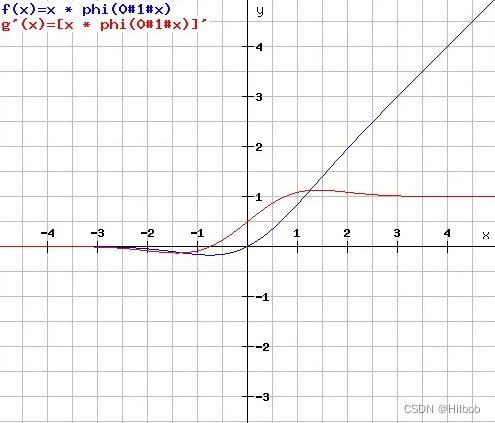
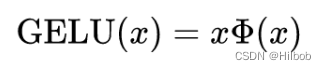
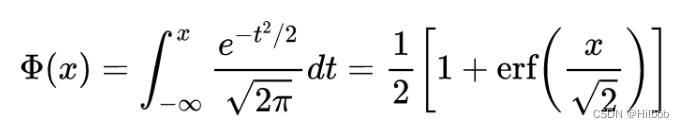
erf为高斯误差函数:
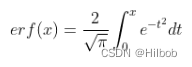
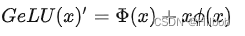
优点:
受 Dropout、ReLU 等机制的影响,希望将神经网络中不重要的激活信息置为零。可以理解为,对于输入的值,我们根据它的情况乘上 1 或
0。更「数学」一点的描述是,对于每一个输入 x,其服从于标准正态分布N(0, 1),它会乘上一个伯努利分布Bernoulli(Φ(x)),其中Φ(x) = P(X ≤ x)。随着 x 的降低,它被归零的概率会升高。对于 ReLU来说,这个界限就是 0,输入小于零就会被归零。这一类激活函数,不仅保留了概率性,同时也保留了对输入的依赖性。
我们经常希望神经网络具有确定性决策,这种想法催生了 GELU 激活函数的诞生。这种函数的非线性希望对输入 x上的随机正则化项做一个转换,具体来说可以表示为:Φ(x)×1×x+(1−Φ(x))×0×x=xΦ(x)Φ(x) × 1 × x + (1 − Φ(x)) × 0 × x = xΦ(x)Φ(x)×1×x+(1−Φ(x))×0×x=xΦ(x)。我们可以理解为,对于一部分Φ(x),它直接乘以输入 x,而对于另一部分 (1 −Φ(x)),它们需要归零。不太严格地说,上面这个表达式可以按当前输入 x 比其它输入大多少来缩放 x。GeLU取值范围(-0.17,+∞),平滑、非单调,似乎是 NLP 领域的当前最佳,尤其在 Transformer 模型中表现最好,被GPT-2、BERT、RoBERTa、ALBERT 等NLP模型所采用;
缺点:
计算量大,通常采用GeLU的近似式来代替原式计算,源论文给出了两个近似:
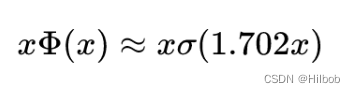

参考文献:
https://zhuanlan.zhihu.com/p/450361606