电子设计全国网站建设微信营销怎么做
Hung-yi Lee 课件整理
预训练得到的模型我们叫自监督学习模型(Self-supervised Learning),也叫基石模型(foundation modle)。
文章目录
- 机器是怎么学习的
- ChatGPT里面的监督学习
- GPT-2
- GPT-3和GPT-3.5
- GPT
- ChatGPT
- 支持多语言
- ChatGPT里面的自监督学习
G:generative
P:pre-train
T:transformer
机器是怎么学习的
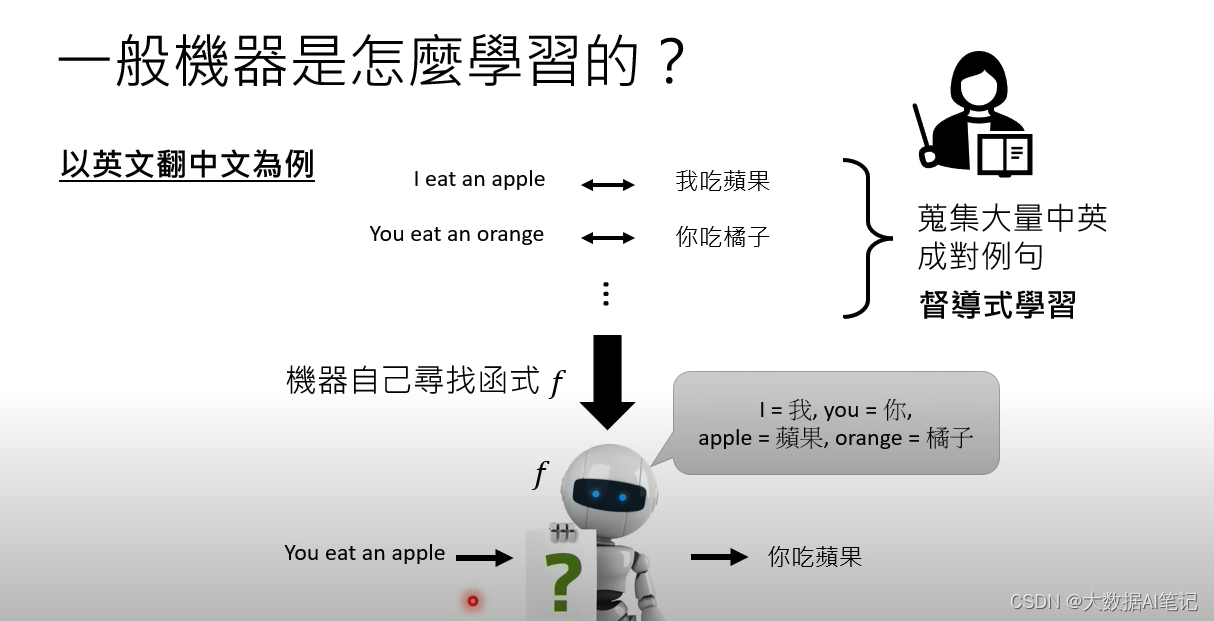
有监督学习一般需要成对的语料来训练模型,比如机器翻译为例,需要中文和英文成对的语料来训练模型。
ChatGPT里面的监督学习
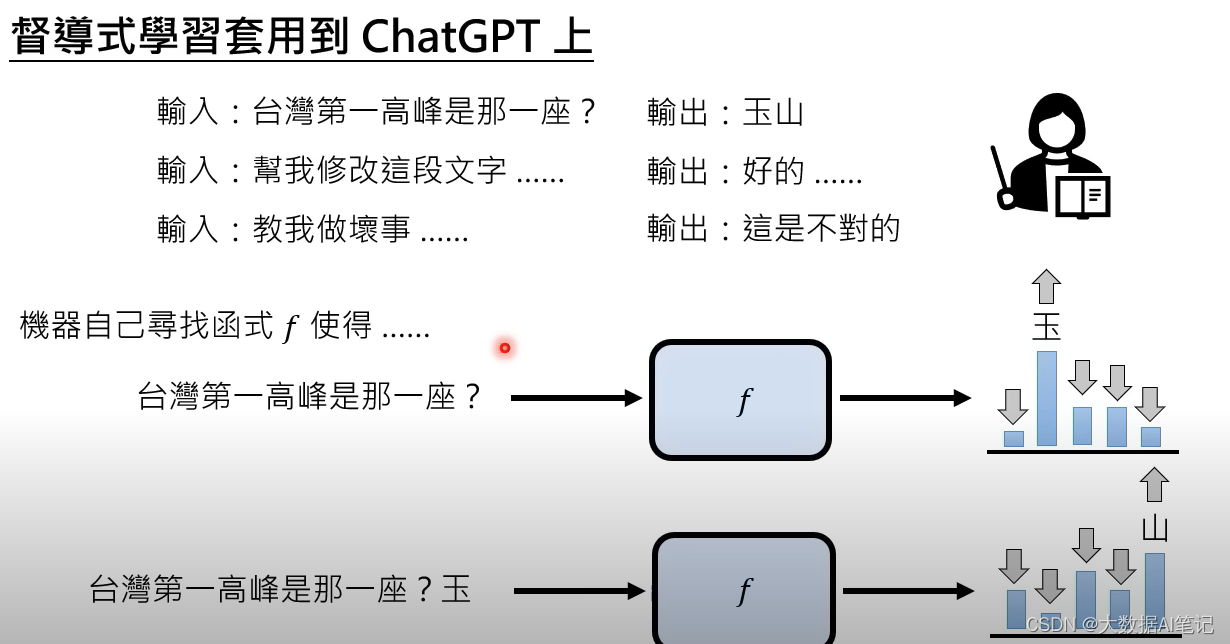
这里讲怎么把有监督学习套用到ChatGPT上,还是成对的语料,一问一答给到模型,机器自己寻找一个函数使得,当我们输入“台湾第一高峰是哪一座?”的时候输出“玉”的概率最大,当把“玉”再加到问句后面输入给模型的时候,输出“山”的概率最大。

但是这时候出现一个问题,假设机器真的是根据老师的教导来寻找函数,它的能力会非常有限,因为人类老师可以提供的成对资料十分有限。比如我们问它:世界第一高山是哪一座?它的学习语料里面没有喜马拉雅这个词,那么它就不会输出正确的结果。
实际上ChatGPT有一个机制可以无痛制造成对的语料。
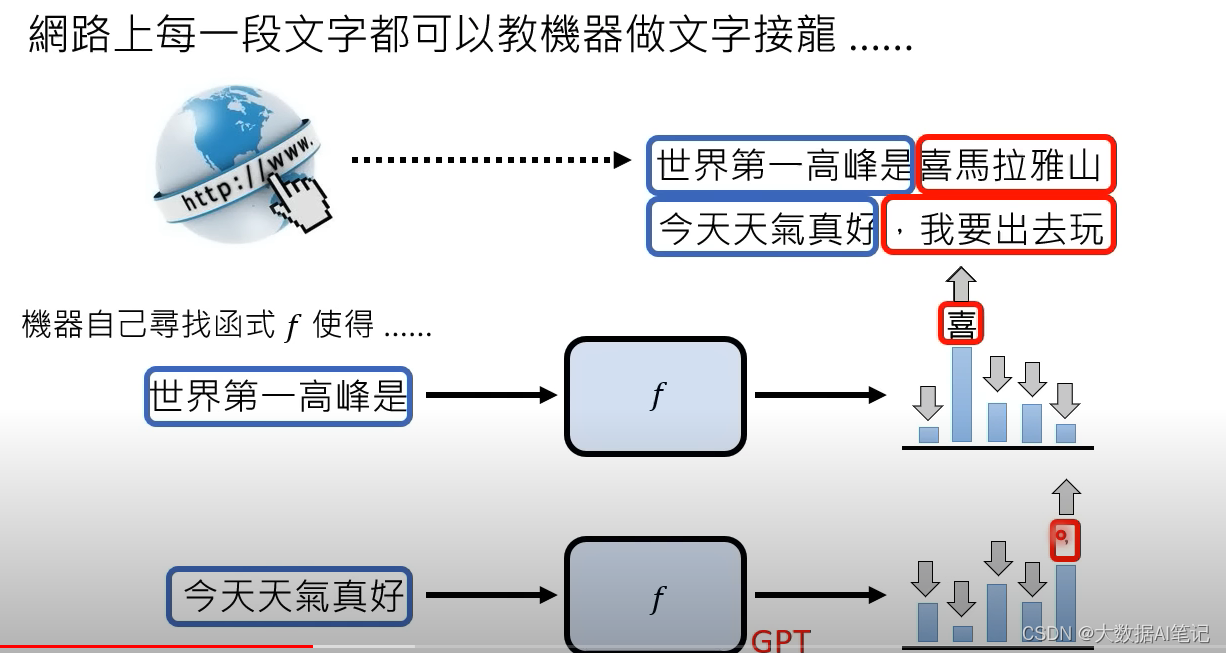
网络上的每一段文字都可以教机器做文字接龙,比如“世界第一高峰是喜马拉雅山”,ChatGPT可以把前半段当作输入,后半段当作输出。
当输入“世界第一高峰是”的时候输出“喜”字的概率最大。
当输入“今天天气真好”的时候,输出“,”的概率最大。
ChatGPT的上一代模型GPT,它设计的目标就是这样一个文字接龙模型。
GPT-2
GPT模型在2018年就已经出现了,那时候模型比较小,只有117M的参数,使用的数据也只有1GB。
第二年(2019年)公开了GPT-2,模型大小到了1542M的参数,训练数据是40G。
这时候的GPT就可以瞎掰了,讲出来的东西就开始像模像样了。
GPT-2能做很多事情,比如回答“世界第一高峰”这个问题,给一段文字让它输出摘要。
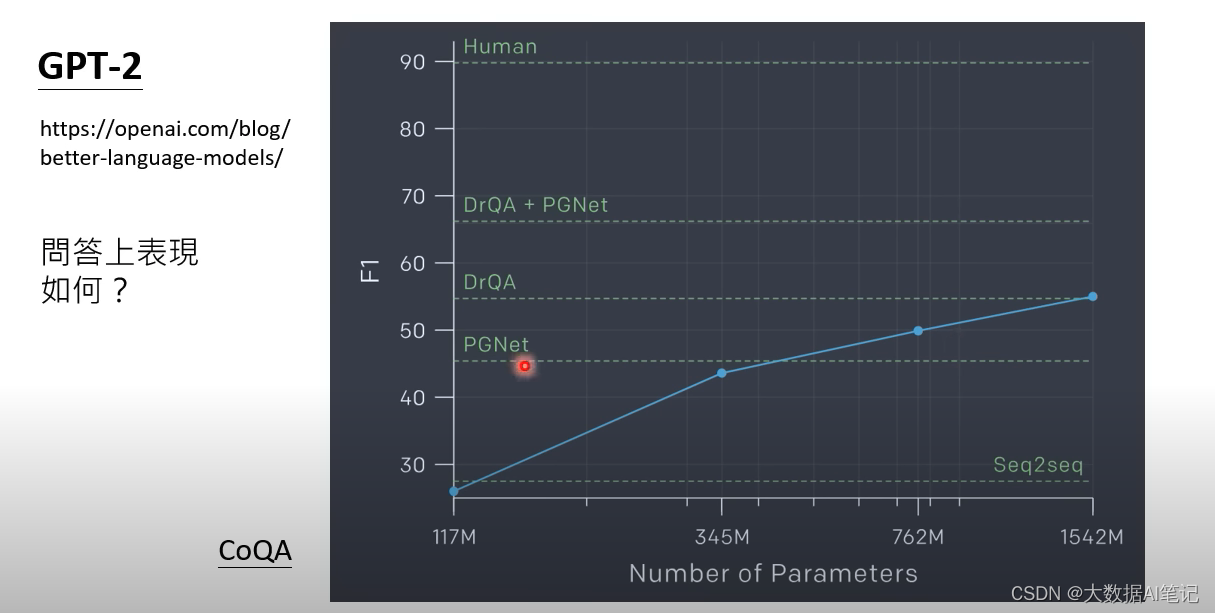
对于GPT-2在回答问题上的表现有这样一个测试。
横轴表示模型的大小,纵轴表示F1(不知道的可以理解为准确率),我们看出它的能力和人类的回答还有很大的差距,但是比一些常见的模型好很多了。
就算只是做文字接龙,这时候的GPT就已经有能力回答问题了。
GPT-3和GPT-3.5

到了2020年,GPT-3的参数量是GPT-2的100倍了,有175B的参数,它的训练数据有570GB,这个数据量相当于阅读哈利波特30万遍,实际上OpenAI从网络上爬取了45T的数据,从中筛选了570GB数据出来训练模型。
那么什么是GPT-3.5呢,其实没有任何一篇文章明确说明它的含义,OpenAI官方的说法是只要是在GPT-3上做微调,再来做其他事情的模型都是GPT-3.5。
我们来看看GPT-3能做什么事情。
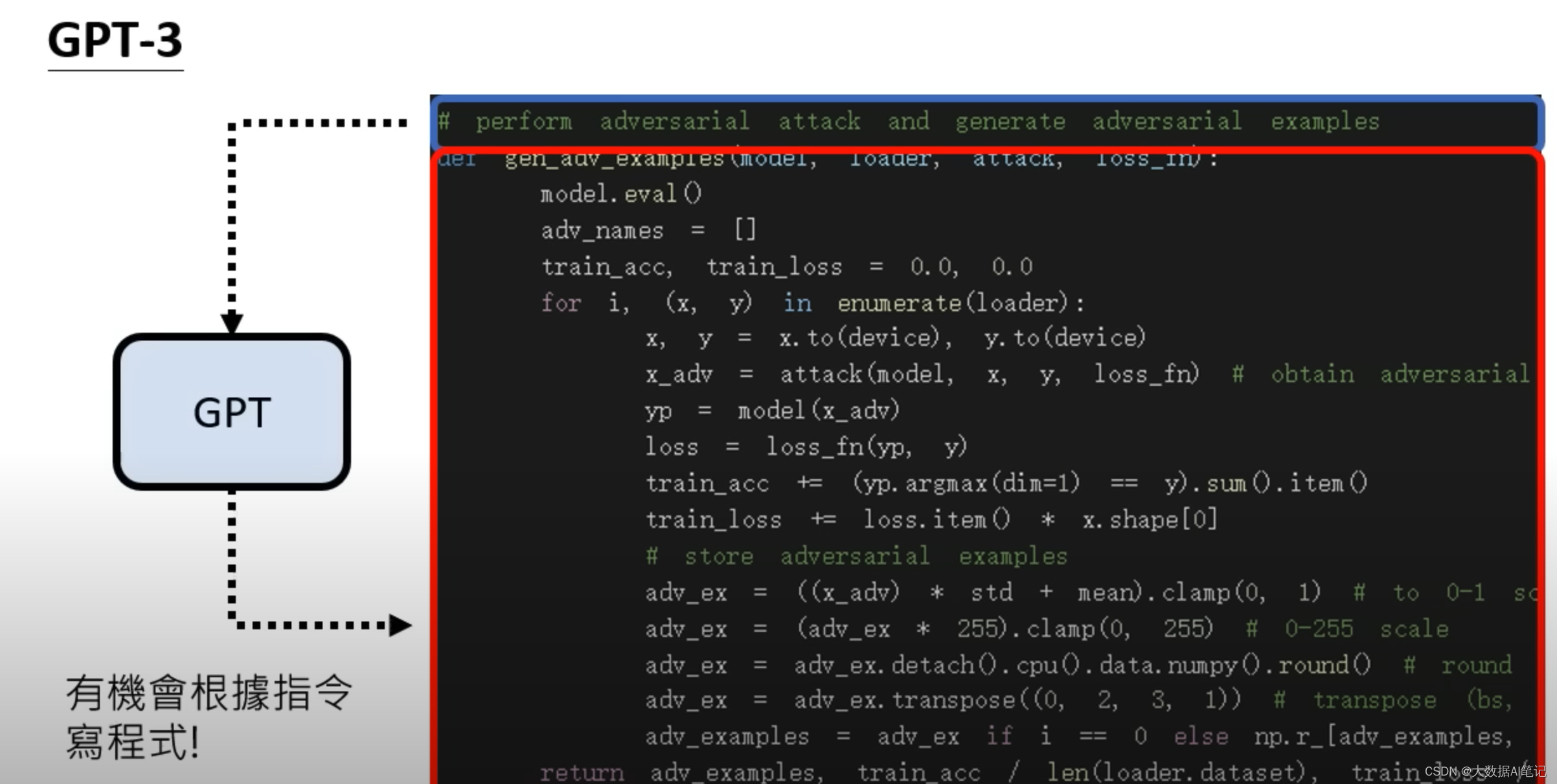
我们给GPT-3输入这样的语料,输入是程序代码的描述,输出是程序代码,这样它就可以写程序了,这不是很惊人的事情。
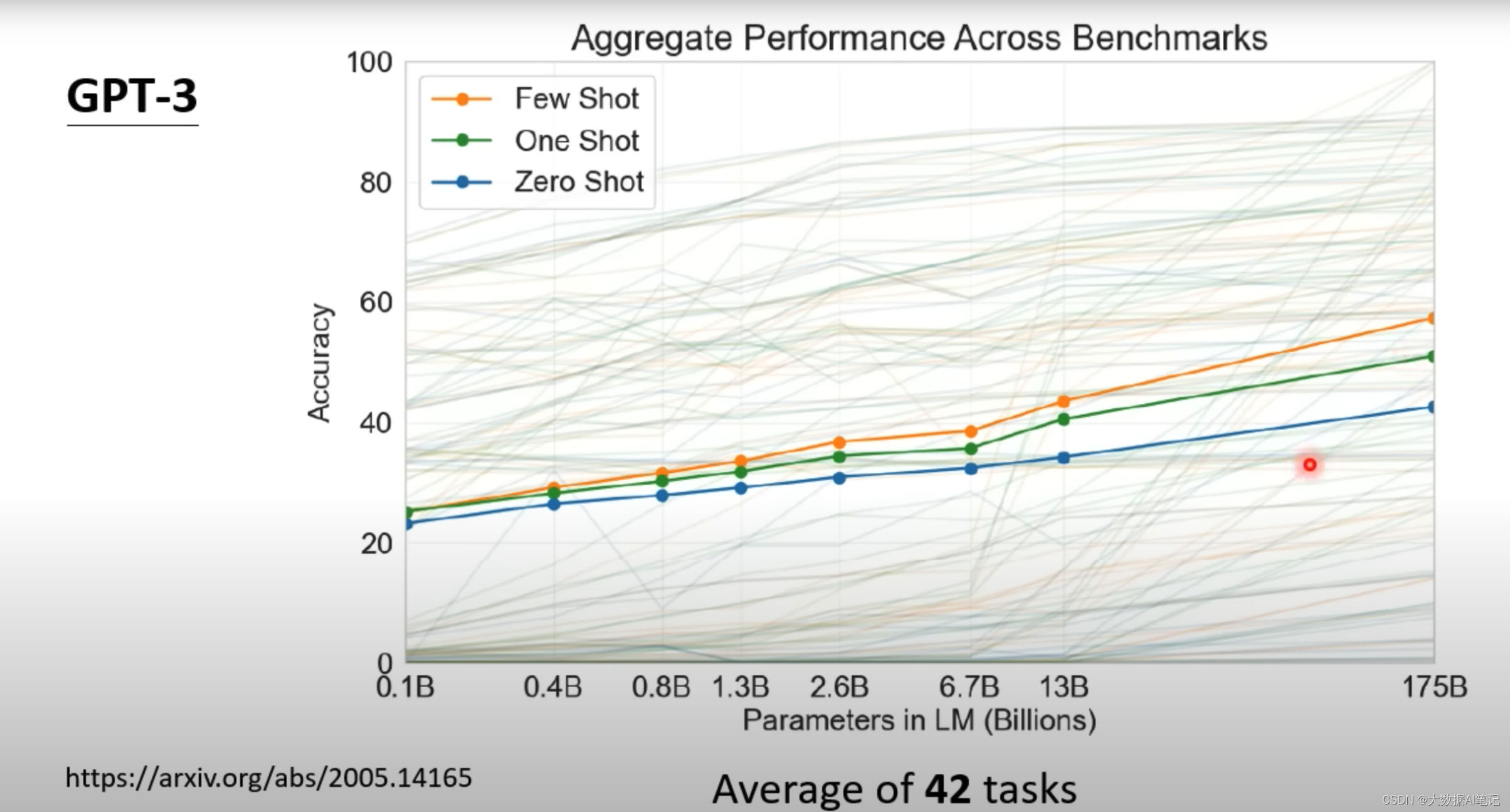
这里我们可以看到在42个NLP任务上做的测试,先不考虑细节,整体上可以看到随着模型越来越大准确率在提高,但是最大的也就是不到60%的准确率,难道GPT-3智能这么大点能耐吗?
GPT
其实GPT很多时候是不受控制的。
比如说你给它一段描述,让它剖析一下这段程序语言,问他这段代码里面的C的目的是什么,它给出的答案是这样的,出一个选择题给你让你选择。
这是因为它学习了网上很多试题,它的学习能力很强,但是给出的答案不一定是我们想要的,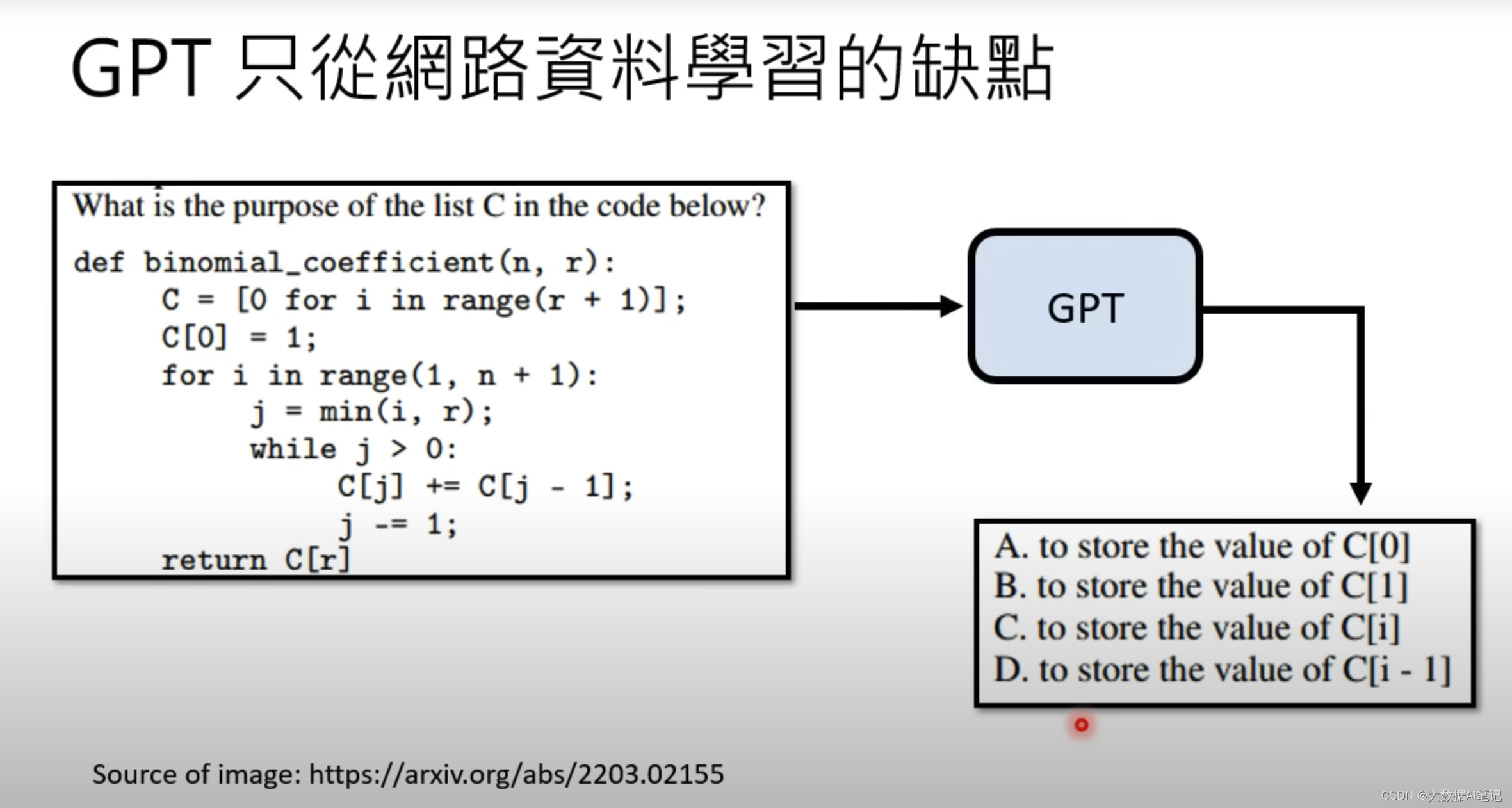
ChatGPT
怎么办呢,怎么才能强化它的能力呢。
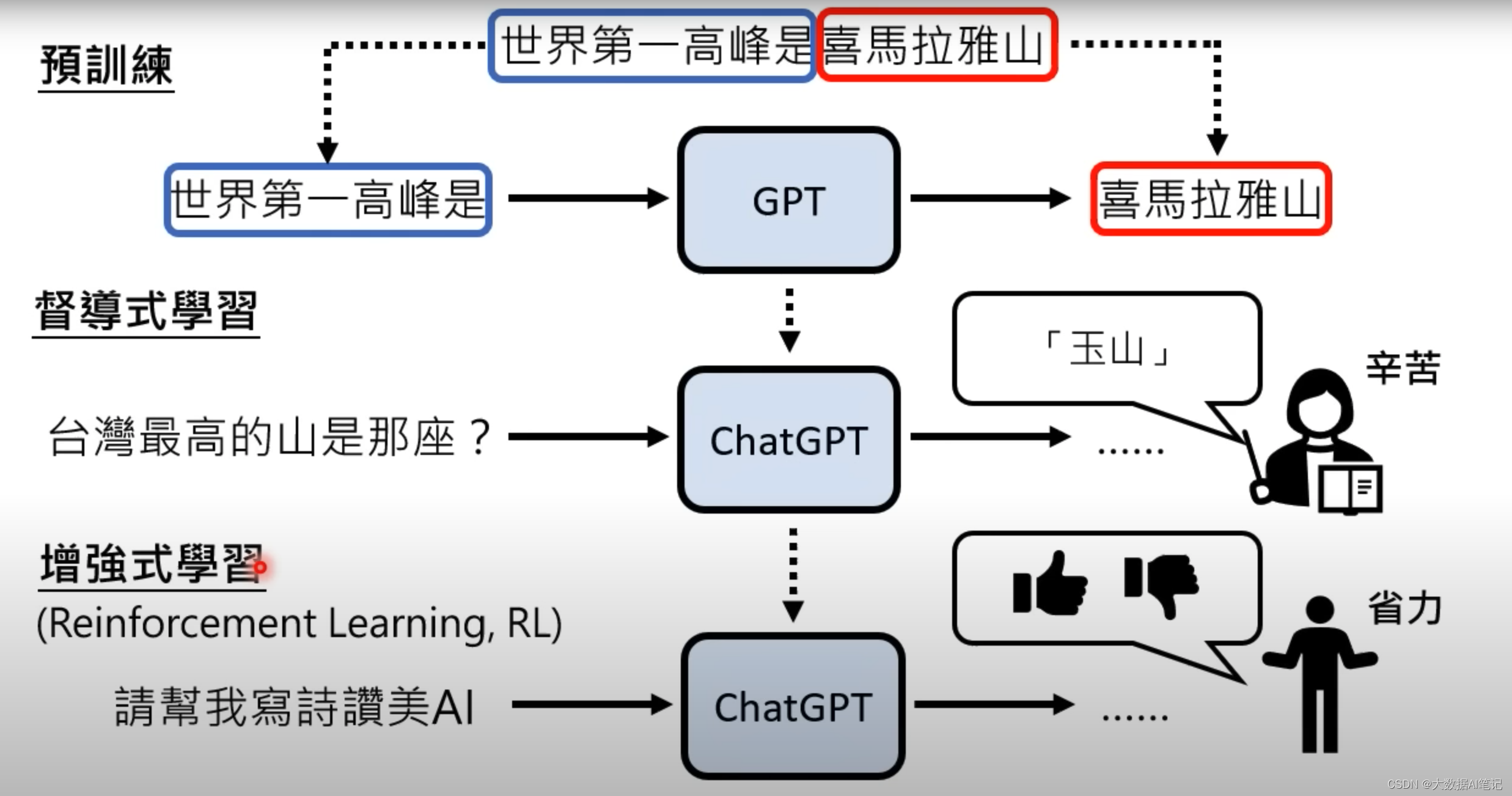
再下一代就到ChatGPT了。需要介入人类老师了,在这之前是不需要人类老师的,从GPT到ChatGPT就需要人类老师的介入了,所以ChatGPT是GPT经过监督学习的模型。
人类老师告诉它,以后别人问你“台湾最高的山是什么山”你要告诉他是“玉山”。
这个有监督学习的过程也叫finetune,或者是继续学习,之前的GPT模型是预训练模型,也是自监督学习。
这里用于有监督学习的语料不是人类整理的,是用一些方法无痛生成的,这种方式就叫做自监督学习,也叫基石模型。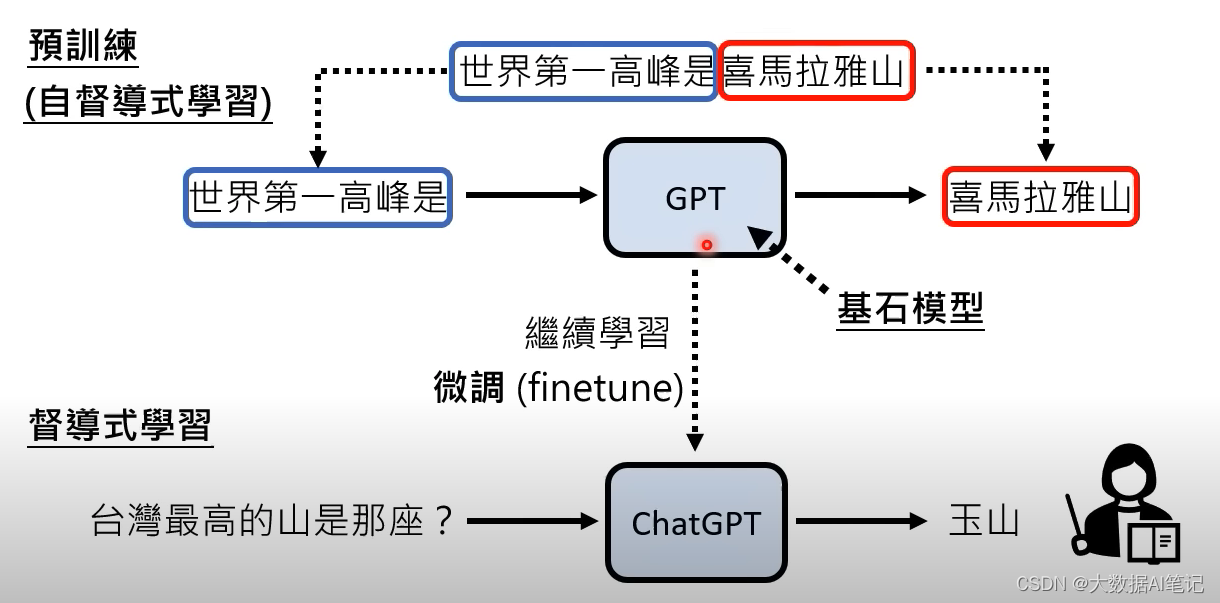
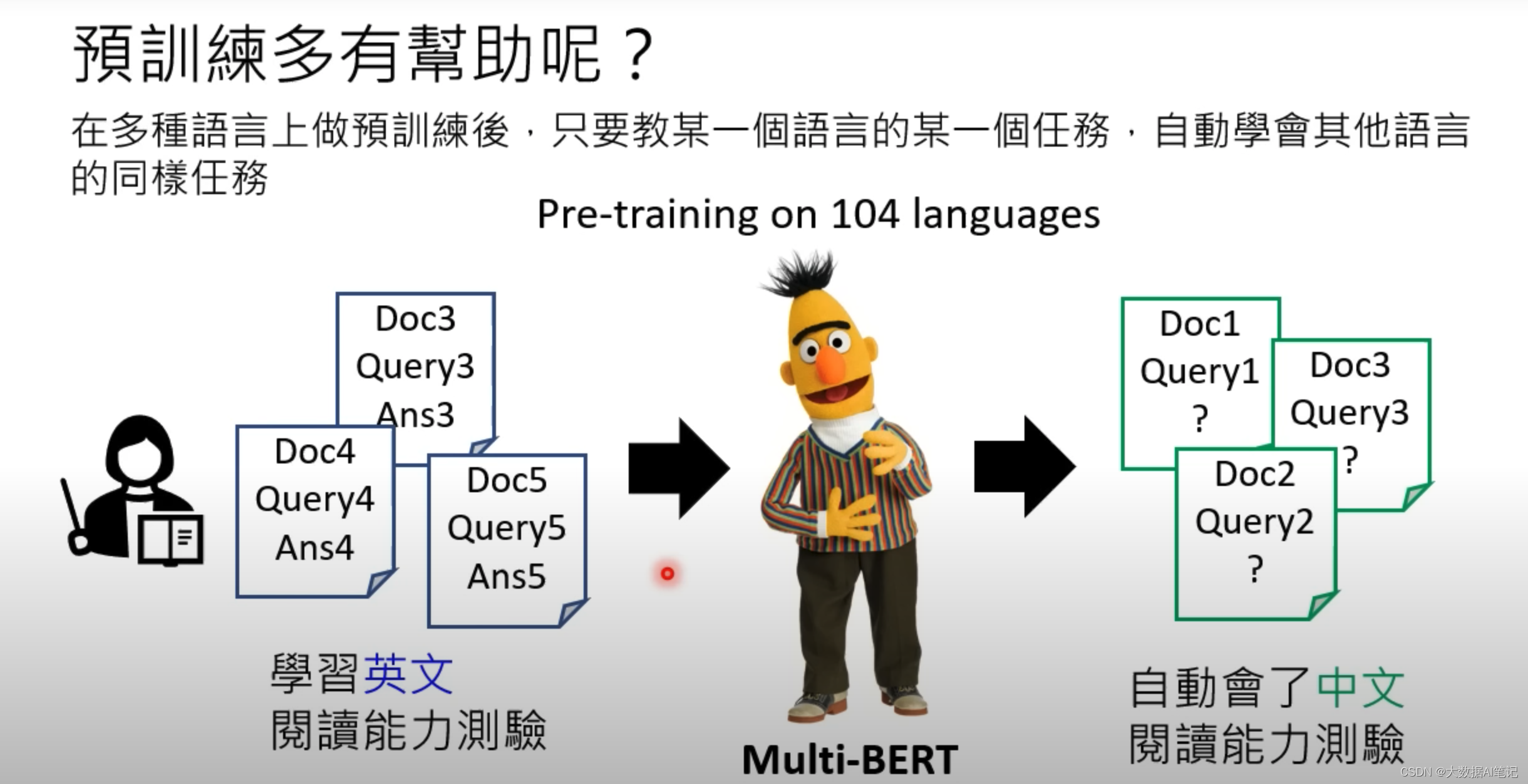
支持多语言
它是怎么做到支持多语言的呢?
ChatGPT不是在单一的预训练模型上做的finetune,里面可能就包含Muti-Bert这样的语言模型。
Muti-Bert支持104种语言,当我们给它只做了英文的阅读理解后,它自动的其他语言也都学会了。
所以ChatGPT不需要单独做翻译这件事情,它自己就学会了翻译。
来看看真正的实验数据。
最下面一行显示人类的表现是93%的准确率。
- 在AQNet模型的Pre-train里面没有中文语料,用中文语料做finetune,然后再在中文上做测试,准确率只有78.1;
- 在Bert模型的Pre-train里面只有中文语料,用中文语料做finetune,然后再在中文上做测试,准确率是89.1,提升了不少;
- 神奇的是,在Bert模型的Pre-train里面有104中语言,用英文语料做finetune,然后再在中文上做测试,准确率也能达到78.8,这说明了我们教它英文,它自己学会了中文。
怎么理解呢,在机器学完很多种语言后,对它来说所有的语言都是一种语言了,没有差别。

ChatGPT里面的自监督学习
我们知道,ChatGPT除了自监督学习,有监督学习还做了强化学习。
在强化学习里面人不是告诉机器答案是什么,而是告诉机器现在的答案是好还是不好。
增强学习有什么好处呢,监督学习的老师是比较辛苦的,需要知道正确的答案,强化学习的老师就可以偷懒,只需要点个赞或者点个倒赞就可以。
增强学习还有一个优势是适合用在人类自己都不知道答案的时候,比如“请帮我写诗赞美AI”,这样的问题,人类不需要给答案,只要给反馈就可以了。
那么ChatGPT就是这样三个过程,先做预训练,然后做有监督学习,最后做强化学习。
至于增强学习其他的细节,我们下一篇博客再细讲。