wordpress回复查看安阳企业网站优化外包
前言:在医学领域,科技的进步一直是改变人类生活的关键驱动力之一。随着深度学习技术的不断发展,其在医学影像诊断领域的应用正日益受到关注。结直肠癌是一种常见但危害极大的恶性肿瘤,在早期发现和及时治疗方面具有重要意义。然而,传统的结直肠癌检测方法往往受限于操作复杂、依赖经验和易产生误诊等问题,因此急需一种准确、快速、非侵入性的检测方法。双深度学习模型的出现为解决这一难题带来了新的希望。通过结合不同深度学习技术,这些模型能够从结直肠癌医学影像中提取丰富的特征信息,实现对癌变组织的精准识别和定位。本文将探讨双深度学习模型在结直肠癌检测中的应用,剖析其原理和技术实现,并展望其在临床实践中的潜在价值。随着技术的不断演进,相信这些创新性的方法将为结直肠癌的早期筛查和诊断带来革命性的变革,为患者提供更加及时有效的医疗服务,实现医学与人工智能的完美融合。
本文所涉及所有资源均在传知代码平台可获取
目录
概述
演示效果
核心代码
写在最后
概述
结直肠癌是一种全球范围内常见的恶性肿瘤,其发病率和死亡率呈上升趋势,早期发现对提高治疗效果和患者生存率至关重要,但传统诊断方法存在主观性和时间成本高的问题,结直肠癌组织切片图像具有复杂结构,需要精确的图像处理技术来辅助诊断,开发基于深度学习的结直肠癌识别系统,旨在提高诊断效率,减少传统方法的局限性。利用深度学习技术自动分类结直肠癌图像,为医生提供可靠的辅助工具,提升临床决策质量。该系统通过自动化图像识别,有助于改善患者的治疗结果,提高生存率,同时为医学图像处理和深度学习在肿瘤诊断领域的应用提供新思路和实践基础。
ResNet34是残差网络(Residual Networks)的一个变种,由微软研究院提出,属于深度卷积神经网络(CNN)的一种。残差网络的设计初衷是为了解决深度网络训练中的退化问题,即随着网络层数的增加,网络的性能反而下降。ResNet通过引入“残差学习”来解决这个问题,允许训练更深的网络。ResNet34包含34个残差块,每个残差块由两个卷积层组成,中间通过跳跃连接(skip connection)连接。这种结构允许网络中的信号绕过一些层直接传递,从而缓解了梯度消失和梯度爆炸的问题,如下图所示:
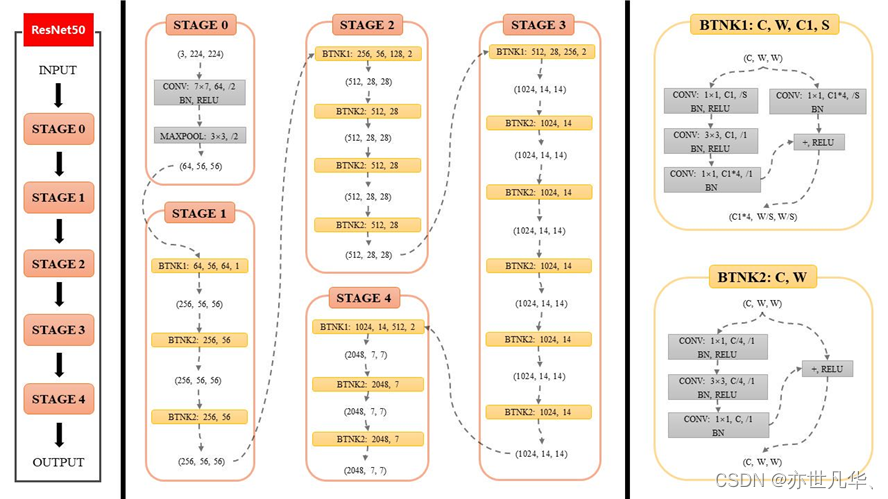
ResNet34的关键特性有以下特性:
1)残差学习:每个残差块学习的是层间的差异(即残差),而不是直接学习未加工的特征。这使得网络可以通过跳跃连接直接传递信息,即使网络非常深。
2)跳跃连接:跳跃连接允许网络中的信号绕过一些层直接传递,有助于梯度在训练过程中更有效地反向传播。
3)批量归一化:ResNet34在每个残差块的卷积层之后使用批量归一化,有助于加快训练速度并提高训练稳定性。
4)ReLU激活函数:在卷积层之后使用ReLU激活函数,引入非线性,增强网络的表达能力。
5)初始卷积层:在输入图像进入第一个残差块之前,首先通过一个7x7的卷积层进行特征提取,然后通过一个最大池化层进行下采样。
6)分类层:在网络的最后,使用一个全连接层(通常称为分类层)来进行图像分类。
Vision Transformer(ViT)是一种用于图像识别任务的深度学习模型,由Google Research在2017年提出。ViT模型是Transformer模型在计算机视觉领域的应用,它与传统的卷积神经网络(CNN)不同,主要依赖于自注意力机制来处理图像数据,ViT有以下特性:
自注意力机制:ViT模型的核心是自注意力机制,它允许模型在处理图像时考虑全局依赖关系,而不是仅依赖局部感受野。
无卷积操作:与CNN不同,ViT模型不使用卷积层。它将图像分割成大小相同的小块(patches),然后将这些小块线性嵌入到一个序列中,再应用标准的Transformer结构。
位置编码:由于Transformer模型本身不具备捕捉序列顺序的能力,ViT为图像块添加了位置编码,以保持图像的空间结构信息。
分类任务的头部:ViT模型通常在Transformer结构的顶部添加一个全连接层,用于图像分类任务。
对于ViT模型的工作流程如下:
1)图像分割:将输入图像分割成大小为(16x16)像素的小块,例如,对于一个(224x224)像素的图像,会得到(14x14)个小块。
2)线性嵌入:每个小块通过一个线性层进行嵌入,将小块的像素值映射到一个高维空间。
3)位置编码:为每个嵌入后的小块添加位置编码,以保持其在原始图像中的位置信息。
4)Transformer编码器:将编码后的序列输入到一个或多个Transformer编码器层中,每层都包括自注意力机制和前馈网络。
5)分类头部:在Transformer编码器的输出上应用一个全连接层,将特征映射到类别标签上。
演示效果
对于准确率(Accuracy)的可视化,可以通过不同的方式呈现模型的性能情况。以下是呈现出来的结果:
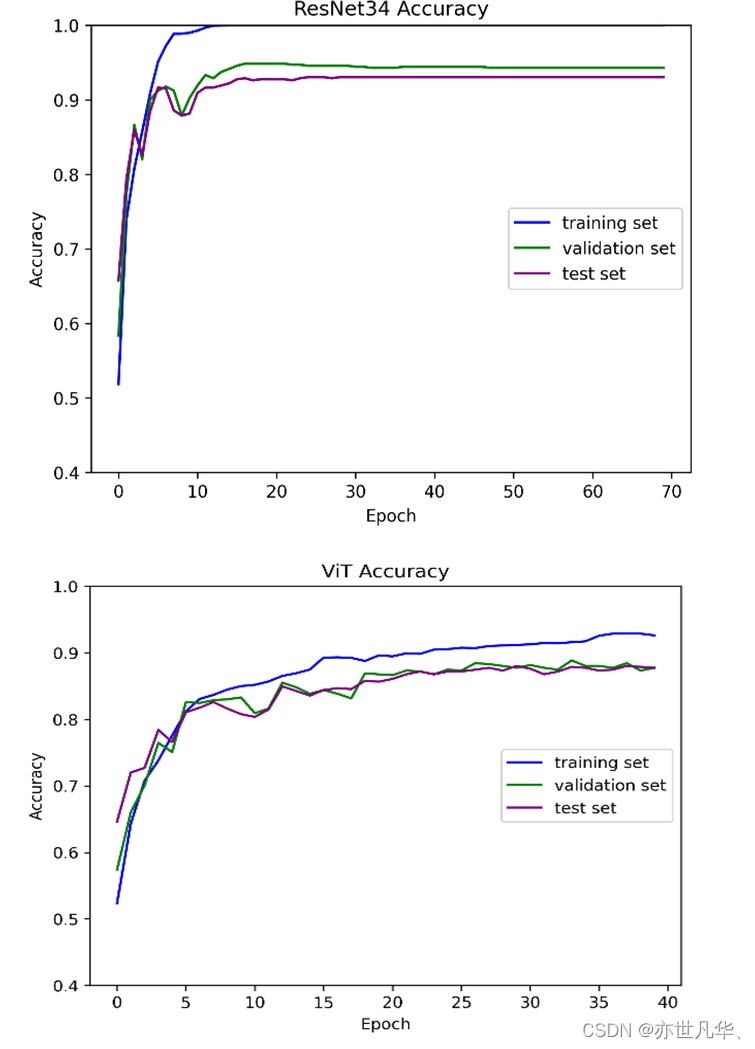
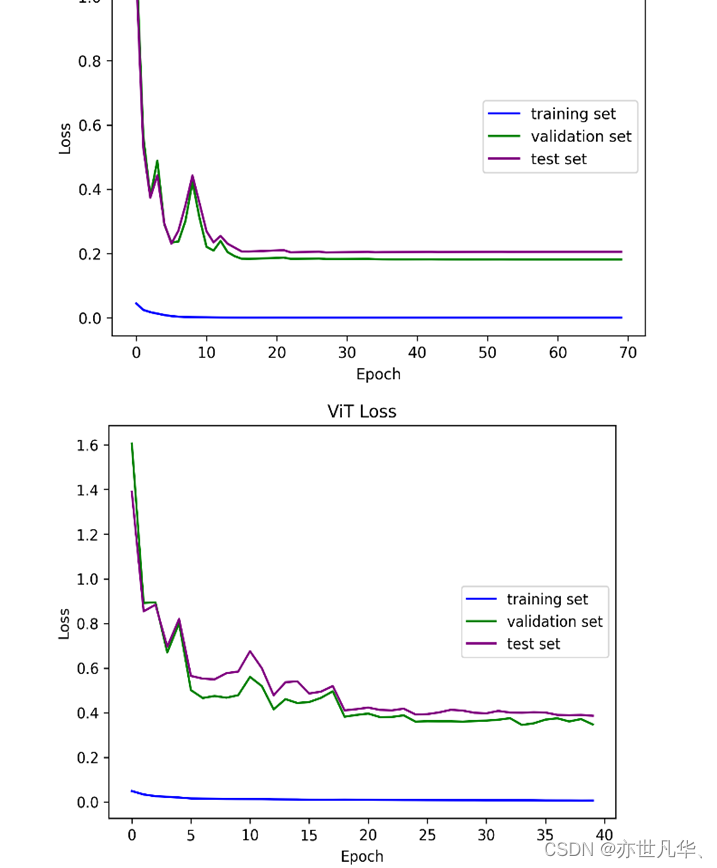
Loss(损失)的可视化是指将模型在训练过程中的损失值随着训练迭代次数的增加而变化的趋势进行可视化展示。损失值通常是用来衡量模型在训练过程中预测结果与真实标签之间的差异程度的指标,即模型预测的结果与真实标签之间的误差大小,如下图所示:
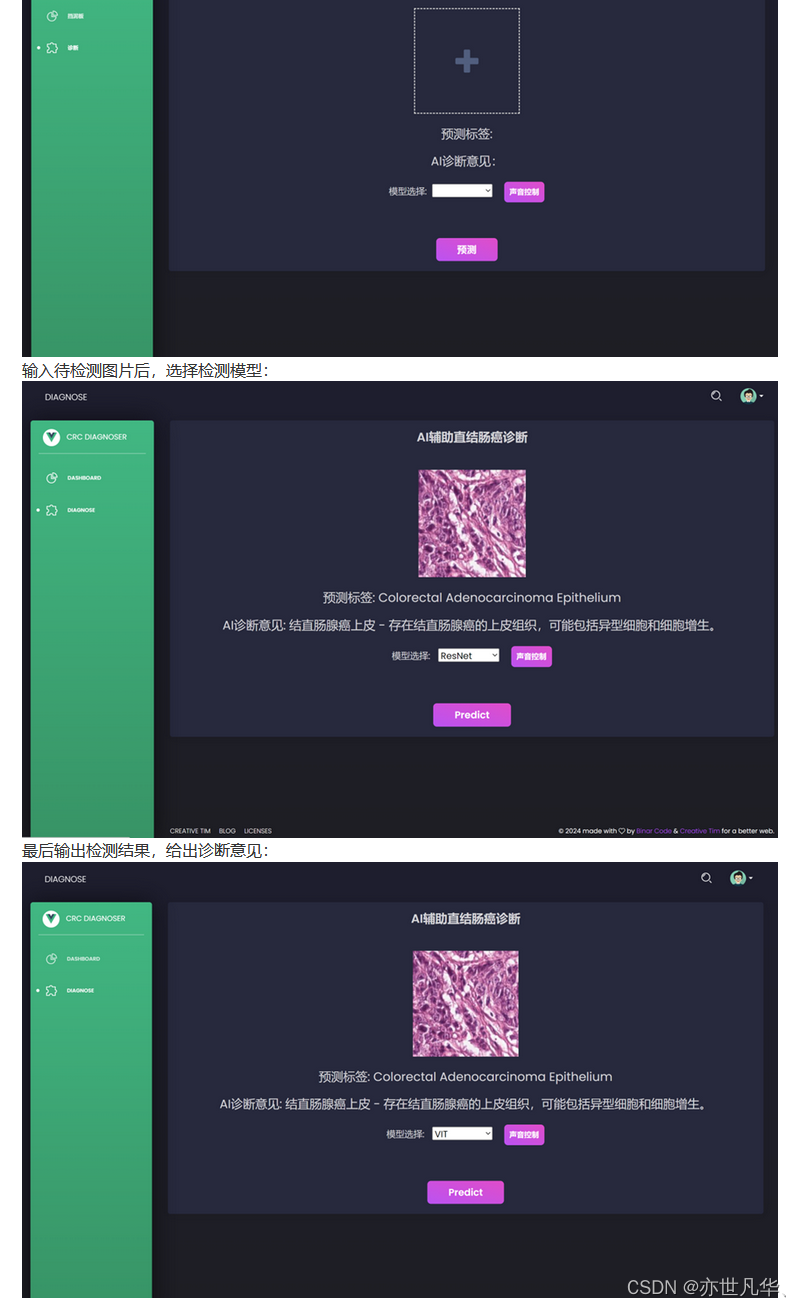
最终系统展示如下所示:
核心代码
下面这段代码定义了一个 ResNet 模型的类 ResNet,它用于构建 ResNet 网络结构,该方法定义了数据在网络中的正向传播过程,即输入数据经过各层的处理最终得到输出结果。通常会调用已经定义好的组件,如卷积层、残差块序列等,以完成整个网络的前向传播过程,通过这个类,可以创建并使用 ResNet 模型来进行图像分类任务:
class ResNet(nn.Module):def __init__(self, block, layers, nums, num_classes, type) -> None:super(ResNet,self).__init__()self.arch = typeself.conv1 = nn.Conv2d(in_channels=3, out_channels=layers[0], kernel_size=7, stride=2, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(layers[0])self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.in_channels = layers[0]self.layers = torch.nn.Sequential(self._make_layers(block, layers[0], nums[0]),self._make_layers(block, layers[1], nums[1], stride=2),self._make_layers(block, layers[2], nums[2], stride=2),self._make_layers(block, layers[3], nums[3], stride=2))self.size = layersself.avg = nn.AvgPool2d(kernel_size=7)self.linear = nn.Linear(layers[3]*block.expension, num_classes)self.relu = nn.ReLU(inplace=True)下面这段代码定义了一个名为 ViT(Vision Transformer)的模型类,用于实现图像分类任务,定义了 ViT 模型的基本参数,包括嵌入维度(embed_dim)、注意力头数(n_head)、类别数量(num_classes)、层数(depth)、输入通道数(in_chans)、输入图像尺寸(input_size)、图像分块大小(patch_size)、dropout 比率(drop_rate)等,作用是定义了一个 ViT 模型的结构,包括网络的初始化和前向传播过程。通过这个类,可以创建并使用 ViT 模型来进行图像分类任务:
class ViT(nn.Module):def __init__(self, embed_dim=768, n_head=12, num_classes=9, depth=6,in_chans=3, input_size=224, patch_size=16, drop_rate=0.2,ffn_radio=4) -> None:super().__init__()self.encoder = nn.ModuleList([EncoderLayer(embed_dim=embed_dim, n_head=n_head, ffn_radio=ffn_radio, dropout=drop_rate) for _ in range(depth)])self.norm = nn.LayerNorm(embed_dim)self.cls = nn.Linear(embed_dim, num_classes)self.patch = PatchEmbedded(in_chans, input_size, patch_size, drop_rate)def forward(self, x):x = self.patch(x)for layer in self.encoder:x = layer(x)x = self.norm(x)x = self.cls(x[:,0])return x写在最后
在深入探讨双深度学习模型在结直肠癌检测中的创新应用后,我们不禁为这一领域的飞速发展而赞叹。双深度学习模型以其独特的优势,不仅提高了诊断的准确性和效率,更为结直肠癌的早期发现和治疗开辟了新的道路,回顾我们的研究,双深度学习模型通过结合不同神经网络架构的优势,实现了对复杂医学图像数据的深度解析。这种模型能够捕捉到细微的图像特征,从而更准确地识别出结直肠癌的病变区域。同时,通过大量的数据训练和优化,模型逐渐学会了从海量信息中筛选出关键信息,为医生提供了更为可靠的诊断依据。
我们期待双深度学习模型能够在更多方面发挥其独特优势,为人类的健康事业贡献更多力量。同时,我们也呼吁更多的科研工作者和医学专家加入到这一领域中来,共同推动双深度学习模型的研究与应用取得更大的突破。让我们携手并进,为人类的健康事业谱写新的篇章!
详细复现过程的项目源码、数据和预训练好的模型可从该文章下方附件获取。
【传知科技】关注有礼 公众号、抖音号、视频号
