在日本做色情网站广告联盟看广告赚钱
Chapter4:Activation Functions
声明:本篇博客笔记来源于《Neural Networks from scratch in Python》,作者的youtube
其实关于神经网络的入门博主已经写过几篇了,这里就不再赘述,附上链接。
1.一文窥见神经网络
2.神经网络入门(上)
3.神经网络入门(下)
前三章内容:
1.Coding Our First Neurons
2.Adding Hidden Layers
4.1 Activation functions
激活函数的作用:将输入值映射到输出,如果激活函数是非线性的,那么将输入进行非线性映射
如果激活函数是线性的,例如f(x)=x,即输入什么就输出什么,那么由这种神经元组成的网络就会输入什么就输出什么
The activation function is applied to the output of a neuron (or layer of neurons), which modifies outputs.
We use activation functions because if the activation function itself is nonlinear, it allows for neural networks with usually two or more hidden layers to map nonlinear functions.
激活函数用在两个方面:1.隐藏层中的神经元、2.输出层的神经元
In general, your neural network will have two types of activation functions. The first will be the activation function used in hidden layers, and the second will be used in the output layer.
The Step Activation Function
如果输入值大于0的数,那么将输出为1,如果输入值小于等于0,那么将输出0
This activation function has been used historically in hidden layers, but nowadays, it is rarely a choice.

The Linear Activation Function
This activation function is usually applied to the last layer’s output in the case of a regression model — a model that outputs a scalar value instead of a classification.

The Sigmoid Activation Function
当输入值小于0时,输出值范围为0~0.5,当输入值大于0时,输出值范围0.5~1

The Rectified Linear Activation Function
The Sigmoid function, historically used in hidden layers, was eventually replaced by the Rectified Linear Units activation function (or ReLU).

4.2 Linear Activation in the Hidden Layers
偏置和权重对激活函数的作用
the bias to offset the function horizontally, and the weight to influence the slope of the activation.
we’re also able to control whether the function is one for determining where the neuron activates or deactivates
从下面情况看,这个神经元的权重和偏置(权重和偏置这种组合模拟了y=x这个函数的作用)


4.3 ReLU Activation in a Pair of Neurons
下面这个神经元的权重和偏置组合模拟了ReLU函数

如果数量大于一个神经元,则每个偏置和权重对激活函数的联合作用
第二个神经元的偏置相当于对ReLU函数进行了上下平移

将第二个神经元的权重取负数,相当于把激活函数进行了垂直方向的翻转

4.4 ReLU Activation in the Hidden Layers
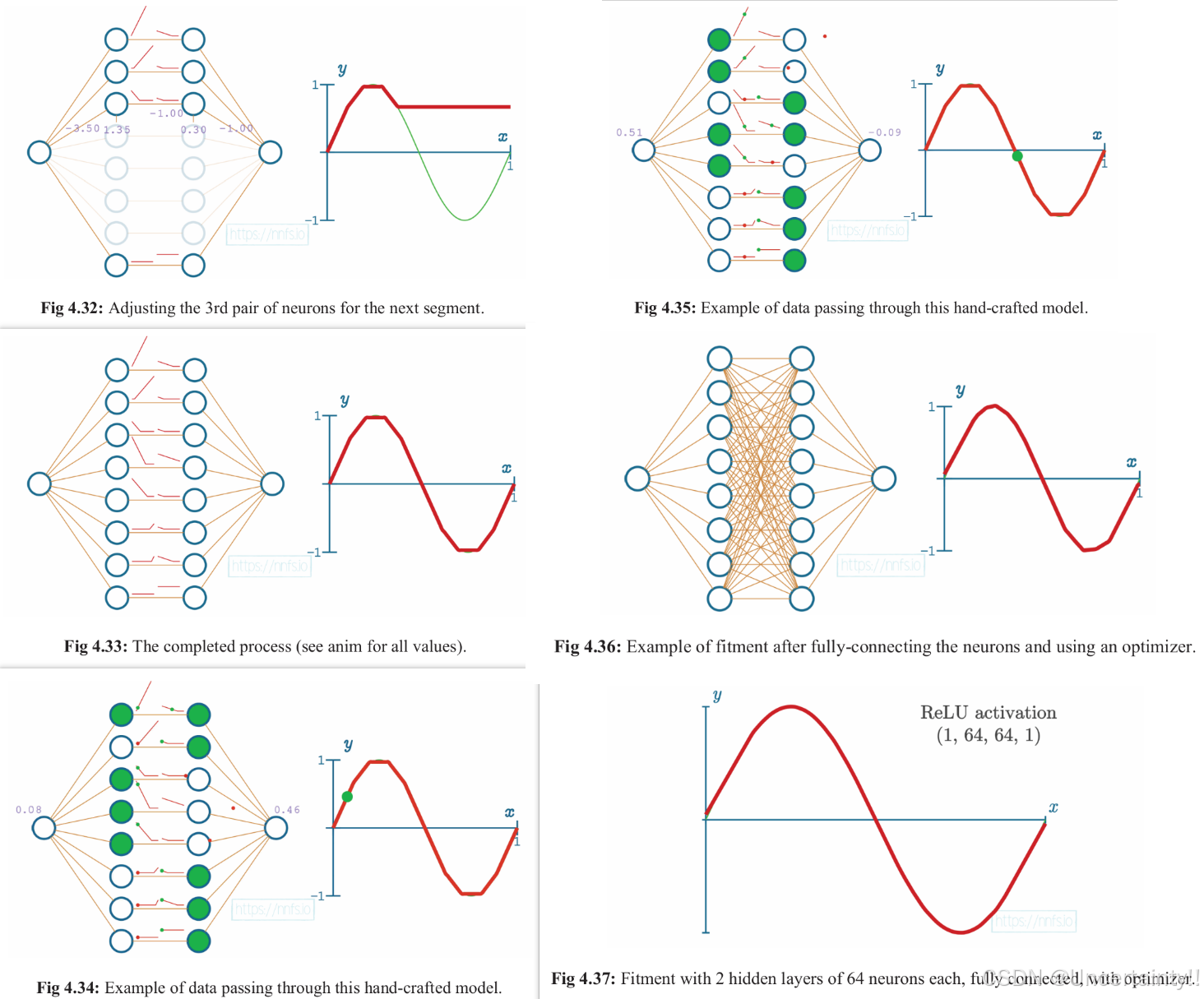
使用2个隐藏层,每层8个神经元,激活函数使用ReLU、这些元素组成的神经网络来模拟sine函数
该模型输入一个值,输出一个类似经过sine函数的函数值。隐藏层使用激活函数ReLU
我们尝试手动调节权重和偏置来使得该模型最终达到模拟sine函数的能力
Fig 4.20–Fig4.25

Fig 4.26–Fig 4.31

Fig 4.32–Fig37
4.5 ReLU Activation Function Code
inputs = [0, 2, -1, 3.3, -2.7, 1.1, 2.2, -100]
outputs = []
# ReLU激活函数 当x>0时输出x,当x<=0时输出0
for i in inputs:if i > 0:outputs.append(i)else:outputs.append(0)print(outputs)
inputs = [0, 2, -1, 3.3, -2.7, 1.1, 2.2, -100]
outputs = []
for i in inputs:outputs.append(max(0, i))
print(outputs)
import numpy as np
inputs = [0, 2, -1, 3.3, -2.7, 1.1, 2.2, -100]
outputs = []
outputs = np.maximum(0, inputs)
print(outputs)
# import numpy as np
# inputs = [0, 2, -1, 3.3, -2.7, 1.1, 2.2, -100]
# outputs = []
# ReLU激活函数 当x>0时输出x,当x<=0时输出0
# for i in inputs:
# if i > 0:
# outputs.append(i)
# else:
# outputs.append(0)
#
# print(outputs)# for i in inputs:
# outputs.append(max(0, i))
# print(outputs)# outputs = np.maximum(0, inputs)
# print(outputs)import numpy as np
import nnfs
from nnfs.datasets import spiral_data
# The spiral_data function allows us to create a dataset with as many classes as we want. The
# function has parameters to choose the number of classes and the number of points/observations
# per class in the resulting non-linear dataset.
'''
nnfs.init() does three things:
(1)it sets the random seed to 0 (by the default),
(2)creates a float32 dtype default, and
(3)overrides the original dot product from NumPy.
All of these are meant to ensure repeatable results for following along.
'''
nnfs.init()class Layer_Dense:def __init__(self, n_inputs, n_neurons):self.weights = 0.01 * np.random.randn(n_inputs, n_neurons)self.biases = np.zeros((1, n_neurons))def forward(self, inputs):self.outputs = np.dot(inputs, self.weights) + self.biasesclass ReLU:def forward(self, inputs):self.output = np.maximum(0, inputs)'''X是每个数据(x,y)坐标值X (0,1)0 0.00299, 0.009641 0.01288, 0.01556y表示类别y 00 01 02 1
'''X, y = spiral_data(samples=100, classes=3)
network = Layer_Dense(2, 3)
network.forward(X) # 将输入前向传播
activation = ReLU() # 实例化激活函数
activation.forward(network.outputs) # 将神经元的值输入到将期货函数
print(activation.output[:5]) # 显示0-4行结果
4.6 The Softmax Activation Function
如果想要让模型具备分类能力,可以使用softmax激活函数,此函数将输入值映射到0~1范围内,输出值代表归属于某个类的概率,即输入值属于某个类的概率是多少,在输出层中的神经元中有一个最大值,即输入值大概率归属于该神经元对应的类别
S i , j = e z i , j ∑ l = 1 L e z i , j S_{i,j}=\frac{e^{z_{i,j}}}{\sum_{l=1}^Le^{z_{i,j}}} Si,j=∑l=1Lezi,jezi,j
先对输入到某层神经元的所有值进行指数运算,将这些指数运算后的值加和,将每个神经元指数运算后的值除以这个所有值指数运算值加和,完成对所有值的归一化
import numpy as np
layer_outputs = [4.8, 1.21, 2.385]
exp_values = np.exp(layer_outputs)
print(exp_values) # 对每个神经元的值进行指数运算
norm_exp = exp_values / np.sum(exp_values) # 对每个指数运算后的值进行归一化
print(norm_exp)
print('sum of norm_values:', np.sum(norm_exp)) # 归一化后的所有值总和为1,概率和为1
========
[121.51041752 3.35348465 10.85906266]
[0.89528266 0.02470831 0.08000903]
sum of norm_values: 0.9999999999999999
To train in batches, we need to convert this functionality to accept layer outputs in batches.
import numpy as np
layer_outputs = np.array([[4.8, 1.21, 2.385],[8.9, -1.81, 0.2],[1.41, 1.051, 0.025]])
print('sum without axis')
print(np.sum(layer_outputs))
print('this will be identical to the above since default is None')
print(np.sum(layer_outputs, axis=None)) # 所有值求和
# in a 2D array/matrix, axis 0 refers to the rows, and axis 1 refers to the columns
print('Another way to think of it w/ a matrix == axis 0: columns:')
print(np.sum(layer_outputs, axis=0)) # 按列求和
print('sum of raws')
print(np.sum(layer_outputs, axis=1)) # 按行求和(结果默认转为一行)
print('Sum axis 1, but keep the same dimensions as input:')
print(np.sum(layer_outputs, axis=1, keepdims=True)) # 按行求和后,保持与输入值维度一致(可以仍然保持一列)
===========
sum without axis
18.171
this will be identical to the above since default is None
18.171
Another way to think of it w/ a matrix == axis 0: columns:
[15.11 0.451 2.61 ]
sum of raws
[8.395 7.29 2.486]
Sum axis 1, but keep the same dimensions as input:
[[8.395][7.29 ][2.486]]
我们知道指数函数在其输入值接近负无穷时趋向于0,并且当输入为0时,输出为1,我们可以利用这个性质来防止指数爆炸,也就是说如果给指数函数输入一个较大值,输出可能超过浮点数能够表示的范围,造成overflow
假设我们从输入值列表中减去最大值,则输出值会落在 [负值,0] 的范围内,归一化后将范围映射到[0,1]
class Activation_Softmax:def forward(self, inputs):exp_vals = np.exp(inputs - np.max(inputs, axis=1, keepdims=True))probability = exp_vals / np.sum(exp_vals, axis=1, keepdims=True)self.output = probabilitysoftmax = Activation_Softmax()
softmax.forward([[1, 2, 3]]) # inputs [[1, 2, 3]] max(inputs)=3 exp(1-3, 2-3, 3-3)=[[0.135, 0.3678, 1]]
print(softmax.output)
softmax.forward([[-2, -1, 0]]) # inputs [[-2, -1, 0]] max(inputs)=-1 exp(-2-0, -1-0, 0-0)=[[0.135, 0.3678, 1]]
print(softmax.output)
softmax.forward([[0.5, 1, 1.5]]) # 将inputs[[1, 2, 3]]除以2变为[[0.5, 1, 1.5]],输出softmax的值并不是[[0.135, 0.3678, 1]]除以2得到的结果
print(softmax.output)
=========
[[0.09003057 0.24472847 0.66524096]]
[[0.09003057 0.24472847 0.66524096]]
[[0.18632372 0.30719589 0.50648039]]
我们创造一个神经网络,输入层2个神经元,第二层(隐藏层)3个神经元(该层神经元使用ReLU激活函数),第三层(输出层)3个神经元(使用softmax激活函数,该函数可以接收未归一化的数据,并输出概率值)
给神经网络输入3个类别的样本,每个类别100个样本,输出层输出3个概率值,神经元由上到下分别对于三个类别,三个输出值对于归属于类别的概率值
# add a dense layer as output layer
import numpy as np
import nnfs
from nnfs.datasets import spiral_data
nnfs.init()# nn结构
class Layer_Dense:def __init__(self, n_inputs, n_neurons):self.weights = 0.01 * np.random.randn(n_inputs, n_neurons) # 使用正态分布随机初始化权重self.biases = np.zeros((1, n_neurons)) # 将偏置初始化为0def forward(self, inputs):self.ouput = np.dot(inputs, self.weights) + self.biases# ReLU
class Activation_ReLU:def forward(self, inputs):self.output = np.maximum(0, inputs)# Softmax
class Activation_Softmax:def forward(self, inputs):exp_vals = np.exp(inputs - np.max(inputs, axis=1, keepdims=True))probability = exp_vals / np.sum(exp_vals, axis=1, keepdims=True)self.output = probabilityX, y = spiral_data(samples=100, classes=3)
dense1 = Layer_Dense(2, 3) # 输入层2,第一层3个neurons
dense1.forward(X) # 将样本输入到输入层,并传递到第一层
activation1 = Activation_ReLU() # 实例化ReLU激活函数
activation1.forward(dense1.ouput) # 对第一层的所有值输入到第一层的激活函数中
dense2 = Layer_Dense(3, 3) # 第二层3个神经元,第三层3个神经元
dense2.forward(activation1.output) # 将第一层激活后的值输入到第三层
activation2 = Activation_Softmax() # 实例化softmax激活函数
activation2.forward(dense2.ouput) # 将到达第三层的值输入到激活函数
print(activation2.output[:5]) # 只输出5个样本(下标0-4)的结果
========
[[0.33333334 0.33333334 0.33333334][0.33333316 0.3333332 0.33333367][0.3333329 0.33333293 0.3333342 ][0.3333326 0.33333263 0.33333474][0.3333323 0.33333242 0.33333525]]
我们构建的神经网络其权重是随机初始化的,该网络并不具备实际应用的能力,假设将该神经网络用于分类,它的预测误差将会很大,我们要想办法调节权重和偏置使得该神经网络的分类误差减小,由此引入loss(误差,损失),我们想让模型的误差尽量小以逼近0