html5做的网站seo站长查询
8. 主从复制
8.1 简介
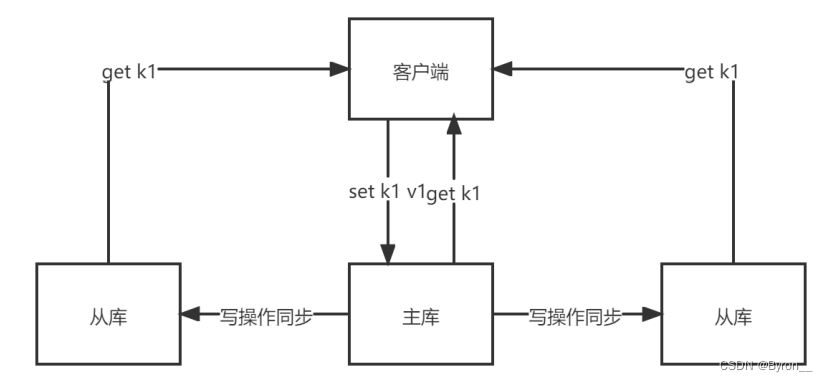
主从库采用读写分离的方式
- 读操作:主库、从库都可以处理
- 写操作:首先写到主库执行,然后再将主库同步给从库。
实现读写分离,性能扩展
容灾快速恢复
8.2 主从复制步骤
- 创建一个目录 ,在root下创建一个myredis的目录
mkdir myredis//创建目录 cd myredis //进行目录 cp /opt/reids-6.2.6/redis.conf redis_1.conf //cp 源文件 目标文件 ls - 关闭aof
- 使用vi编辑三个conf文件,redis_6379.conf,redis_6380.conf,redis_6381.conf做为一主二从配置,配置文件内容如下所示:
include redis_1.conf pidfile /var/run/reids_6379.pid port 6379 dbfilename dump6379.rdb - 分别启动三个服务
[root@localhost myredis]# redis-server redis_6379.conf [root@localhost myredis]# redis-server redis_6380.conf [root@localhost myredis]# redis-server redis_6381.conf [root@localhost myredis]# ps -ef|grep redis root 7289 1 0 17:35 ? 00:00:00 redis-server 127.0.0.1:6379 root 7296 1 0 17:35 ? 00:00:00 redis-server 127.0.0.1:6380 root 7302 1 0 17:35 ? 00:00:00 redis-server 127.0.0.1:6381 root 7316 6663 0 17:35 pts/0 00:00:00 grep --color=auto redis - 在三个客户端,模拟分别连接到不同服务器
redis-cli -p 端口号 redis-cli -p 6379 redis-cli -p 6380 redis-cli -p 6381 - 查看服务器状态
info replication - 在6380和6381上调用replicaof ,将其从属于6379(如果是三台服务器以上步骤可以跳过,直接配置从属服务器)
replicaof 127.0.0.1 6379 - 在主库上可以写入数据,从库不能写入数据
- 主库和从库都可以读数据
8.3 服务器宕机演示
8.3.1 从服务器宕机
- 6381上调用shutdown
- 在主服务器上写入数据
- 6381重新连上时,仍然可以接收到主服务器的数据
8.3.2 主服务器宕机
- 6379服务器调用shutdown
- 在从服务器上仍然可以读取数据
- 从服务器显示主服务器的状态为down
- 当主服务器重新启动,从服务器显示主服务器的状态是up
8.4 主从同步原理
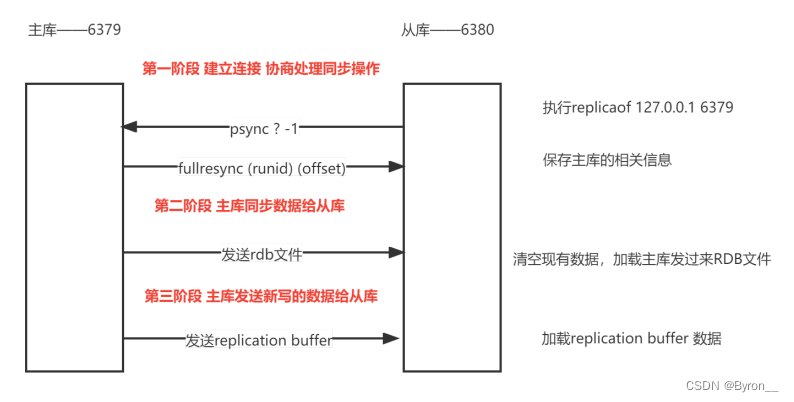
第一阶段
- 主从建立连接,协商同步。从库和主库建立连接,告诉主库即将进行同步操作。主库需要确认并回复,主从就可以开始进行同步处理了。
- 从库向主库发送一个psync指令,包含两个参数。一个是主库的runID,另一个是复制进度offset。
- runID是每个redis实例启动时生成的一个随机ID,唯一标识。第一次复制时,从库不知道主库的runid,所以设为一个"?"。
- offset,-1表示第一次复制
- 主库收到指令后,会发送给从库fullresync指令去响应,带着主库的runid,还有目前复制进度offset。
- 从库会记录下这两个参数。fullresync表示全量复制。主库把所有内容都复制给从库
第二阶段
- 主库将所有数据发送给从库进行同步。从库收到rdb文件后,在本地把原有的数据清除,同步从主库接收到的rdb文件 。
- 如果在主库把数据跟从库同步的过程中,主库还有数据写入,为了保证主从数据的一致性,主库会在内
- 存中给一块空间replication buffer,专门记录rdb文件生成后收到的所有写操作
第三阶段
- 主库把第二阶段执行过程中新收到的操作,再发送给从库,从库再加载执行这些操作,就实
现同步处理了。
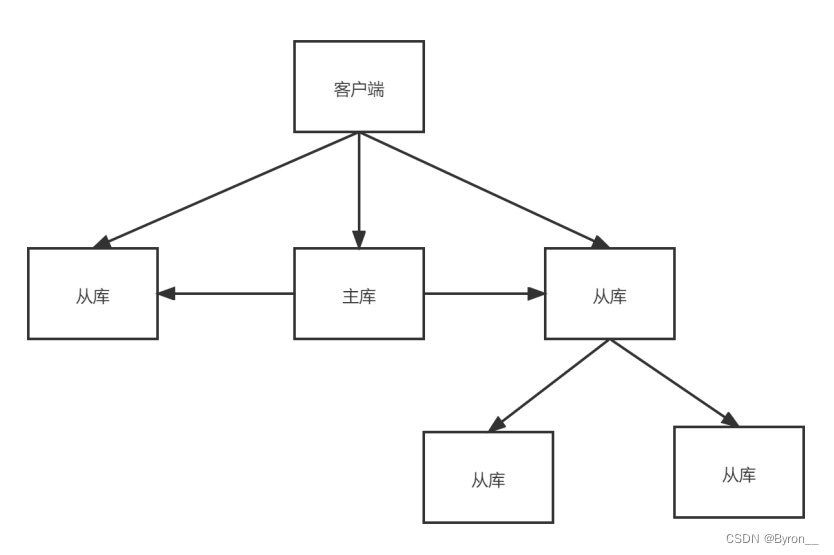
8.5 主-从-从模式
采用主-从-从模式,将主库生成和传输rdb文件的压力,以级联方式分散到从库上。
8.6 网络连接异常情况
在redis2.8之前,如果网络异常,再次连接后,需要做全量复制
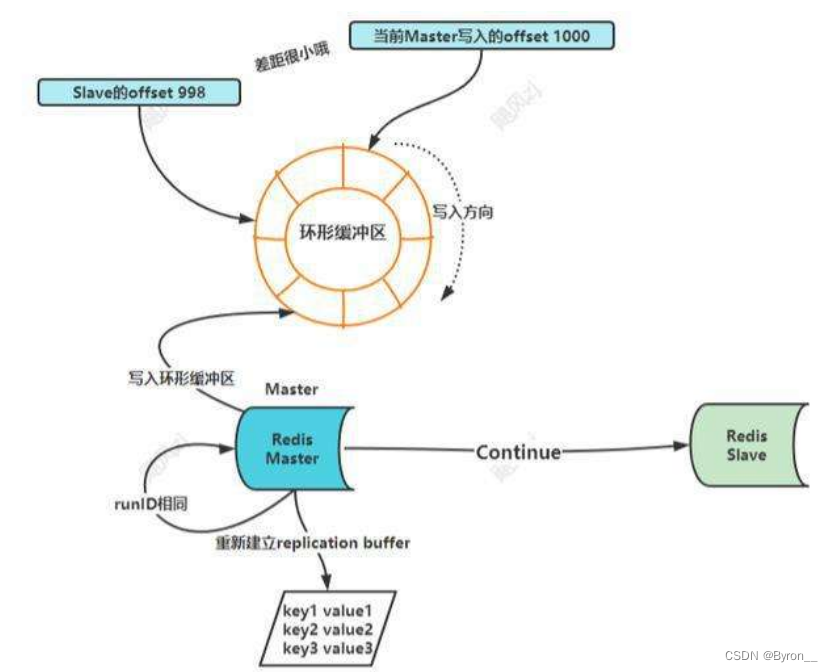
从redis2.8之后,采用增量复制方式。repl_backlog_buffer缓冲区。当主从网络断开后,主库把收到写
操作,写入replication buffer,同时,也写入到repl_backlog_buffer缓冲区.
这个缓冲区,是一个环形缓冲区,主库会记录自己写到的位置,从库会记录自己读到的位置。
在之前还是会识别一下环形缓冲区还能不能够提供完整的数据,如果不能就进行全量同步了
- repl_backlog_size参数
- 缓冲空间大小=主库写入速度 * 操作大小-主从库网络传输速度 * 操作大小
- repl_backlog_size=缓冲空间大小*2
- 2000 * 2-1000 * 2=2000 大约为2M 乘2 所以repl_backlog_size值为4M