青岛做网站seo搜索优化推广
链接到文 — https://arxiv.org/pdf/2010.11929.pdf
一、说明
如今,在自然语言处理(NLP)任务中,转换器已成为goto架构(例如BERT,GPT-3等)。另一方面,变压器在计算机视觉任务中的使用仍然非常有限。大多数研究人员直接使用卷积层,或者将某些注意力块与卷积块一起添加到计算机视觉应用(如Xception,ResNet,EfficientNet,DenseNet,Inception等)中。关于视觉转换器(ViT)的论文在图像序列上实现了纯变压器模型,而无需卷积块来对图像进行分类。本文展示了ViT如何在各种图像识别数据集上获得比大多数最先进的CNN网络更好的结果,同时使用更少的计算资源。
二、视觉变压器 (ViT)
转换器是对数据序列进行操作的网络,例如一组单词。这些单词集首先被标记化,然后输入到转换器中。转换器添加 Attention(二次运算 — 计算每对标记化单词之间的成对内积。随着字数的增加,操作数也会增加)。
因此,图像更难在变形金刚上训练。图像由像素组成,每个图像可以包含数千到数百万个像素。因此,在转换器中,每个像素将与图像中的每个其他像素进行成对操作。在大小为 500*500 像素的图像中,即 500^2,因此注意力机制将花费 (500^2)^2 次操作。这是一项艰巨的任务,即使有多个 GPU。因此,对于图像,研究人员大多使用某种形式的局部注意力(像素聚类),而不是使用全局注意力。
ViT的作者通过使用全局注意力来解决这个问题,但不是在整个图像上,而是在多个图像补丁上。因此,首先将大图像分成多个小块(例如 16*16 像素)。如图 1 所示。

图1.图像分为多个补丁(来源:原始论文中的图像)
然后将这些映像修补程序展开为一系列映像,如图 2 所示。这些图像序列具有位置嵌入。

图2.图像补丁展开成一系列图像(来源:原始论文中的图像)
最初,变压器不知道哪个补丁应该去哪里。因此,位置嵌入有助于变压器了解每个补丁应该适合的位置。在论文中,作者使用了简单的编号1,2,3...n,以指定补丁的位置,如图 3 所示。这些不仅仅是数字,而是可学习的向量。也就是说,数字 1 不直接使用,而是存在一个查找表,其中包含表示补丁位置的每个数字的向量。因此,对于第一个补丁,从表中抓取第一个矢量并与补丁一起放入变压器中。同样,对于第二个补丁,从表中抓取第二个矢量并与第二个补丁一起放入变压器中,依此类推。如图 2 所示。

图3.带有位置嵌入的补丁(来源:图片来自原始论文)
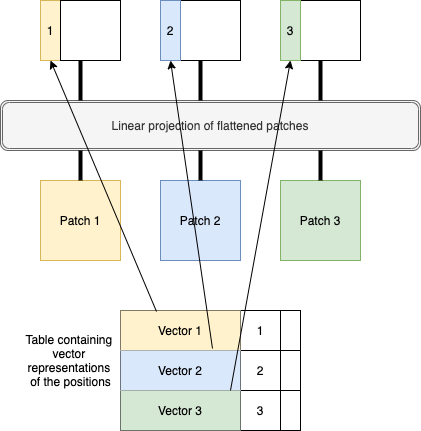
图4.位置嵌入作为向量表示(来源:作者创建的图像)
映像修补程序是小映像(16*16 像素)。这在某种程度上需要以一种变压器理解它的方式馈送。一种方法是将图像展开为 16*16 = 256 维向量。然而,该论文的作者使用了线性投影。这意味着有一个矩阵,表示为“E”(嵌入)。获取单个补丁并首先解卷成线性向量。然后将该向量与嵌入矩阵 E 相乘。然后将最终结果与位置嵌入一起馈送到变压器。
然后将所有补丁(线性投影)及其单独的位置嵌入送入变压器编码器。该变压器是标准的变压器架构(您只需要注意 - 纸)。
还有一个额外的可学习嵌入,标记为位置零,如图 5 所示。此嵌入的输出用于最终对整个图像进行分类。

图5.整个ViT架构,带有额外的可学习嵌入 - 用红色标记,最左边的嵌入(来源:原始论文的图片)
三、结果
表1显示了ViT与各种数据集上最先进的CNN架构的结果比较。ViT是在JFT-300数据集上进行预训练的。下面的结果表明,在所有数据集上,ViT的表现都优于基于ResNet的架构和EfficentNet-L2架构(在嘈杂的学生权重上预训练)。这两种模型都是当前最先进的CNN架构。在表1中,ViT-H指的是ViT-Huge(32层),ViT-L指的是ViT-Large(24层)。ViT-H/L 后面的数字 14 和 16 表示从每个图像创建的补丁大小(14*14 或 16*16)。
该表还显示,与其他 2 个 CNN 模型相比,ViT 需要的计算资源要少得多。

表 1.ViT结果与各种图像数据集上其他CNN架构的比较(来源:原始论文中的表格)
图6显示了变压器在对各种图像进行分类时给予的注意。

图6:从输出标记到输入空间的注意力机制(来源:原始论文图片)
四、结论
4.1 视觉变压器是否会在计算机视觉任务中取代CNN?
到目前为止,CNN已经在计算机视觉任务中占据主导地位。图像基于这样的想法,即一个像素依赖于其相邻像素,下一个像素依赖于其相邻像素(颜色、亮度、对比度等)。CNN对这个想法的研究,并在图像的补丁上使用过滤器来提取重要的特征和边缘。这有助于模型仅从图像中学习必要的重要特征,而不是图像每个像素的细节。
但是,如果将整个图像数据馈送到模型中,而不仅仅是过滤器可以提取的部分(或它认为重要的部分),则模型表现更好的机会更高。这正是视觉转换器内部正在发生的事情。这可能是在这种情况下,视觉变压器比大多数CNN型号工作得更好的原因之一。
4.2 但这是否意味着变压器将来将在计算机视觉任务中取代CNN?
好吧,答案是,不会那么快。就在几天前,EfficientNet V2型号发布,其性能甚至比Vision Transformers更好。这只是意味着,现在我们可以期待来自两种类型(CNN和变形金刚)的新架构将在不久的将来推出更新,更好,更高效的模型。