德州企业网站优化公司杭州网站外包
一、需求背景
基于保密要求,不放原始表,新建测试表用来演示
insert into TEST0221 (采血人, 采血时间, 条码号, 病人ID)
values ('张三', to_date('21-02-2024 12:00:00', 'dd-mm-yyyy hh24:mi:ss'), '2024001', '0001');insert into TEST0221 (采血人, 采血时间, 条码号, 病人ID)
values ('张三', to_date('21-02-2024 12:01:00', 'dd-mm-yyyy hh24:mi:ss'), '2024002', '0001');insert into TEST0221 (采血人, 采血时间, 条码号, 病人ID)
values ('张三', to_date('21-02-2024 12:02:00', 'dd-mm-yyyy hh24:mi:ss'), '2024003', '0001');insert into TEST0221 (采血人, 采血时间, 条码号, 病人ID)
values ('张三', to_date('21-02-2024 14:00:00', 'dd-mm-yyyy hh24:mi:ss'), '2024004', '0001');insert into TEST0221 (采血人, 采血时间, 条码号, 病人ID)
values ('李四', to_date('21-02-2024 12:05:00', 'dd-mm-yyyy hh24:mi:ss'), '2024005', '0002');insert into TEST0221 (采血人, 采血时间, 条码号, 病人ID)
values ('李四', to_date('21-02-2024 12:06:00', 'dd-mm-yyyy hh24:mi:ss'), '2024006', '0002');insert into TEST0221 (采血人, 采血时间, 条码号, 病人ID)
values ('李四', to_date('21-02-2024 12:07:00', 'dd-mm-yyyy hh24:mi:ss'), '2024007', '0002');insert into TEST0221 (采血人, 采血时间, 条码号, 病人ID)
values ('李四', to_date('21-02-2024 12:08:00', 'dd-mm-yyyy hh24:mi:ss'), '2024008', '0003');insert into TEST0221 (采血人, 采血时间, 条码号, 病人ID)
values ('李四', to_date('21-02-2024 12:09:00', 'dd-mm-yyyy hh24:mi:ss'), '2024009', '0003');insert into TEST0221 (采血人, 采血时间, 条码号, 病人ID)
values ('李四', to_date('21-02-2024 12:10:00', 'dd-mm-yyyy hh24:mi:ss'), '2024010', '0003');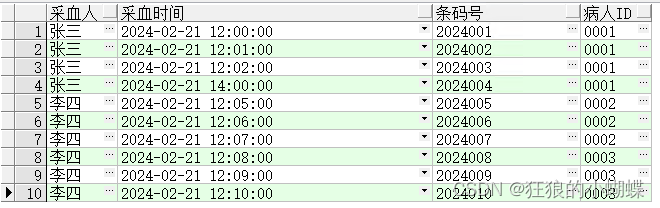
最近工作上接到一个需求,统计采血工作量,按人员统计采血人次,本来很好统计,业务上一个人可能一次采血可能会采集多管,但是只能算作采血人员只采集了一次,那么就按人次来计算,而不是按试管来计算,sql语句如下:
select 采血人,count(distinct 病人ID) as 采血人次 from TEST0221
group by 采血人;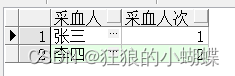
但是很快需求方提出问题,张三的工作量少了1个,因为虽然他只采集了这一个人,但是他最后一次采集与前一次相差了2小时左右,很明显不是一次采集完的,经过一番沟通,确定了统计口径为:如果同一个人的采集时间与上一次间隔超过了10分钟,那么就应该把这次也算作一次工作量。
这样统计思路很清晰,但是SQL语句好像不太好写,或许有其他方式,但最终决定尝试用开窗函数解决。
二、问题解决
为了便于自己理清思路,分步骤写出sql语句。
首先我需要知道同一个采样人对同一个患者,每次采样时间与上一次采样的间隔,也就是需要在两行数据之间做计算,把同一个患者同一个采样人上一次的采样时间获取到,那么使用开窗函数lead来实现。
LEAD函数和 LAG函数主要用于查询当前字段的上一个值或下一个值,若向上取值或向下取值没有数据的时候显示为NULL
- LEAD: 向后偏移
- LAG: 向前偏移
关于开窗函数网上资料很多,可以自行了解。
select t.采血人,t.采血时间,t.条码号,t.病人id, lead(采血时间, 1) OVER(partition by 采血人, 病人id ORDER BY 采血时间 desc) as 前一次采血时间,(t.采血时间 - lead(采血时间, 1)OVER(partition by 采血人, 病人id ORDER BY 采血时间 desc))*24*60 as 间隔分钟数from TEST0221 t;
此处解释下 lead(采血时间, 1) OVER(partition by 采血人, 病人id ORDER BY 采血时间 desc)
其中 lead(采血时间, 1) 的1是偏移量,采血时间是要取的字段
其中 partition by 采血人, 病人id 是在窗口中根据采血人和病人ID分组
ORDER BY 采血时间 desc 则是根据采血时间排序
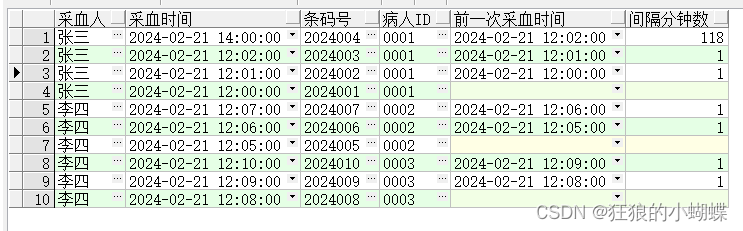
到了这一步之后,思路就很清晰了,只需要在上面的基础上加上10分钟的判断并计数即可
select s.采血人,count(distinct s.计数项 ) as 采血人次 from (
select t.采血人,t.采血时间,t.条码号,case when (t.采血时间 - lead(采血时间, 1)OVER(partition by 采血人, 病人id ORDER BY 采血时间 desc))*24*60>10 then 病人id||'-'||to_char(采血时间,'yyyy-mm-dd hh24:mi:ss') else病人id end as 计数项from TEST0221 t) s group by s.采血人;