农产品销售网站建设方案中国免费网站服务器下载
完整的配置-标注-训练-识别在我这篇博客小白YOLOv5全流程-训练+实现数字识别_yolov5数字识别_牛大了2022的博客-CSDN博客 模型部分剖析可以看我每周深度学习笔记部分。关于训练的数据集怎么搞很多人问过我,我在这篇文章给大家一点我的经验和建议。
数据集是什么
简单来说图像集(.png .jpg)等图片,标注后是图像数据集(.xml)形式,在我上面放的文章链接中有专门画框标注生成.xml的程序。后者是训练时用到训练集。

一、寻找开源的数据集网站
一般百度或者谷歌搜索就行,有的网站上会有打包好的供用户下载。一般训练2 3k张就能达到比较好的效果。(因为我还在读本科,用到的目标检测不追求准确率能演示就行,一般训练几百张)
这种方法适合找常规的、被很多人用的检测数据集,比如行人、火焰、汽车等。
比如m6z.cn/6fzn0f 该数据集由早期火灾和烟雾的图像数据集组成。数据集由在真实场景中使用手机拍摄的早期火灾和烟雾图像组成。提供了大约有7000张图像数据。

但如果有特殊diy需求,一般没法从网上找到现成的数据集。就要考虑接下来的方法。
二、爬虫爬取
爬虫爬取图片的python代码很多,这里放置一个供参考。忘了从哪个大佬那里copy的了(仅供参考侵删) 里面 ’地面‘ 是搜索词,替换即可,倒数第三行改一下存放路径即可。
import time
import requests
import urllibpage = input("请输入要爬取多少页:")
page = int(page) + 1 # 确保其至少是一页,因为 输入值可以是 0
header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
n = 0 # 图片的前缀 如 0.png
pn = 1 # pn是从第几张图片获取 百度图片下滑时默认一次性显示30张
for m in range(1, page):url = 'https://image.baidu.com/search/acjson?'param = {'tn': 'resultjson_com','logid': '8846269338939606587','ipn': 'rj','ct': '201326592','is': '','fp': 'result','queryWord': '地面','cl': '2','lm': '-1','ie': 'utf-8','oe': 'utf-8','adpicid': '','st': '-1','z': '','ic': '','hd': '','latest': '','copyright': '','word': '地面','s': '','se': '','tab': '','width': '','height': '','face': '0','istype': '2','qc': '','nc': '1','fr': '','expermode': '','force': '','cg': 'girl','pn': pn,'rn': '30','gsm': '1e',}page_info = requests.get(url=url, headers=header, params=param)page_info.encoding = 'utf-8' # 确保解析的格式是utf-8的page_info = page_info.json() # 转化为json格式在后面可以遍历字典获取其值info_list = page_info['data'] # 观察发现data中存在 需要用到的url地址del info_list[-1] # 每一页的图片30张,下标是从 0 开始 29结束 ,那么请求的数据要删除第30个即 29为下标结束点img_path_list = []for i in info_list:img_path_list.append(i['thumbURL'])for index in range(len(img_path_list)):print(img_path_list[index]) # 所有的图片的访问地址time.sleep(1)urllib.request.urlretrieve(img_path_list[index], "D:/Awangyefu/" + str(n) + '.jpg')n = n + 1pn += 29例如我想做一个魔方的目标检测,我那上面的程序爬取的百度图片(但上面的代码爬取速度有点慢,1k张好像爬了好几个小时)

但是也有很少一部分物体,百度图片爬取的可能千奇百怪(比如海面石油)黑的红的黄的都有,不适合进行目标检测训练(我菜也是一方面)自己一张张找也不现实,就要用到最后的方法了。
三、视频抽帧图片集
需要用到Adobe Premiere Pro,一款视频剪辑后期软件,网上一搜一大把破解的,下文称为pr。
视频的每一秒都是由图片组成的,又称为帧,一般我们看的视频都是30帧60帧每秒。所以每个视频转成图片就是庞大的数据集。
首先上b站油管等找到自己需要的视频,录下来或者通过第三方网站下载下来。
进入pr,新建项目,左下角导入刚才准备好的视频。再将左下角的视频拖入中间框,可以进行简单的长度裁剪
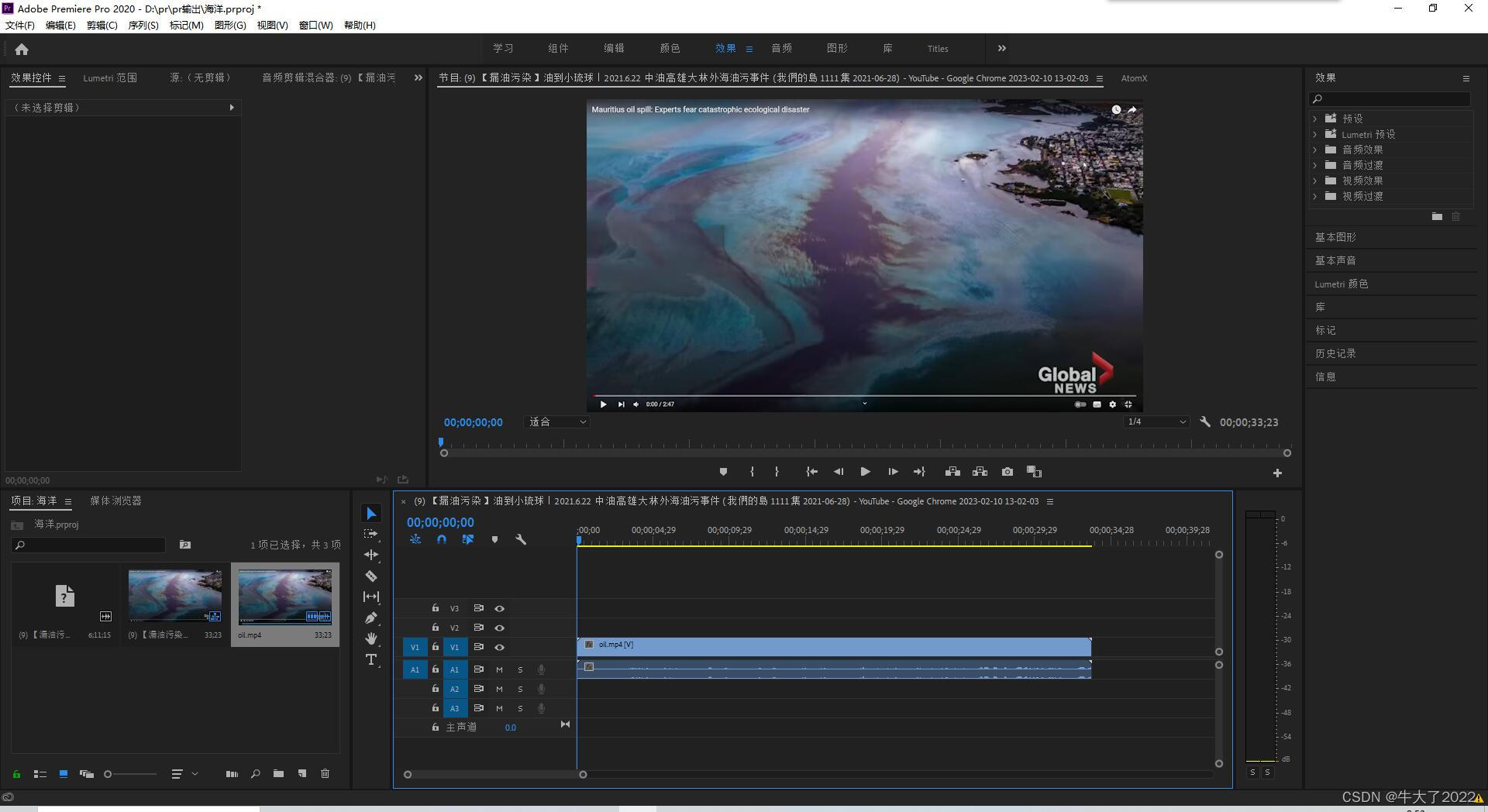
上图中间键选择第四个小刀片就可以裁剪了。
完成后点击左上角-文件-导出
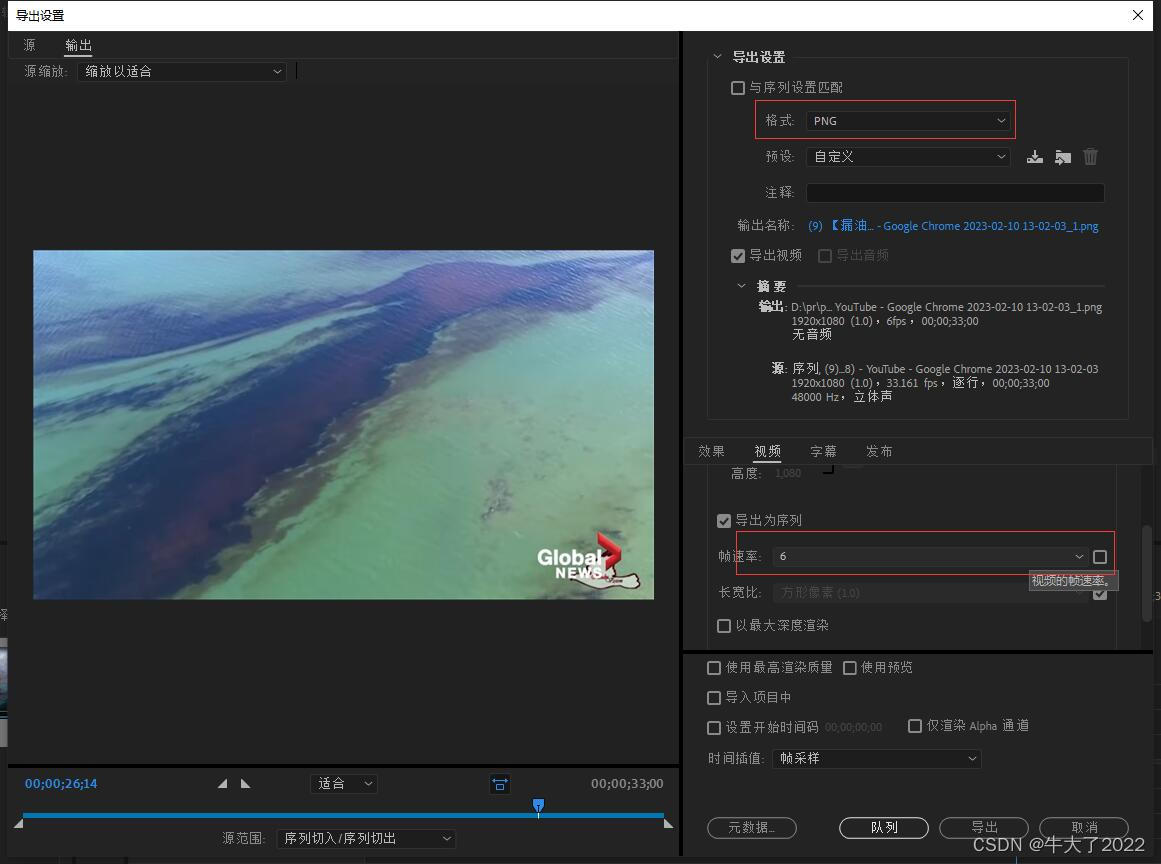
格式选择png(图片),帧速率就是一秒会生成几张图片,比如1分钟的视频,帧速率为6,则一共会生成360张图片。
生成后去生成路径里找图片就行了,然后就是痛苦的标注time
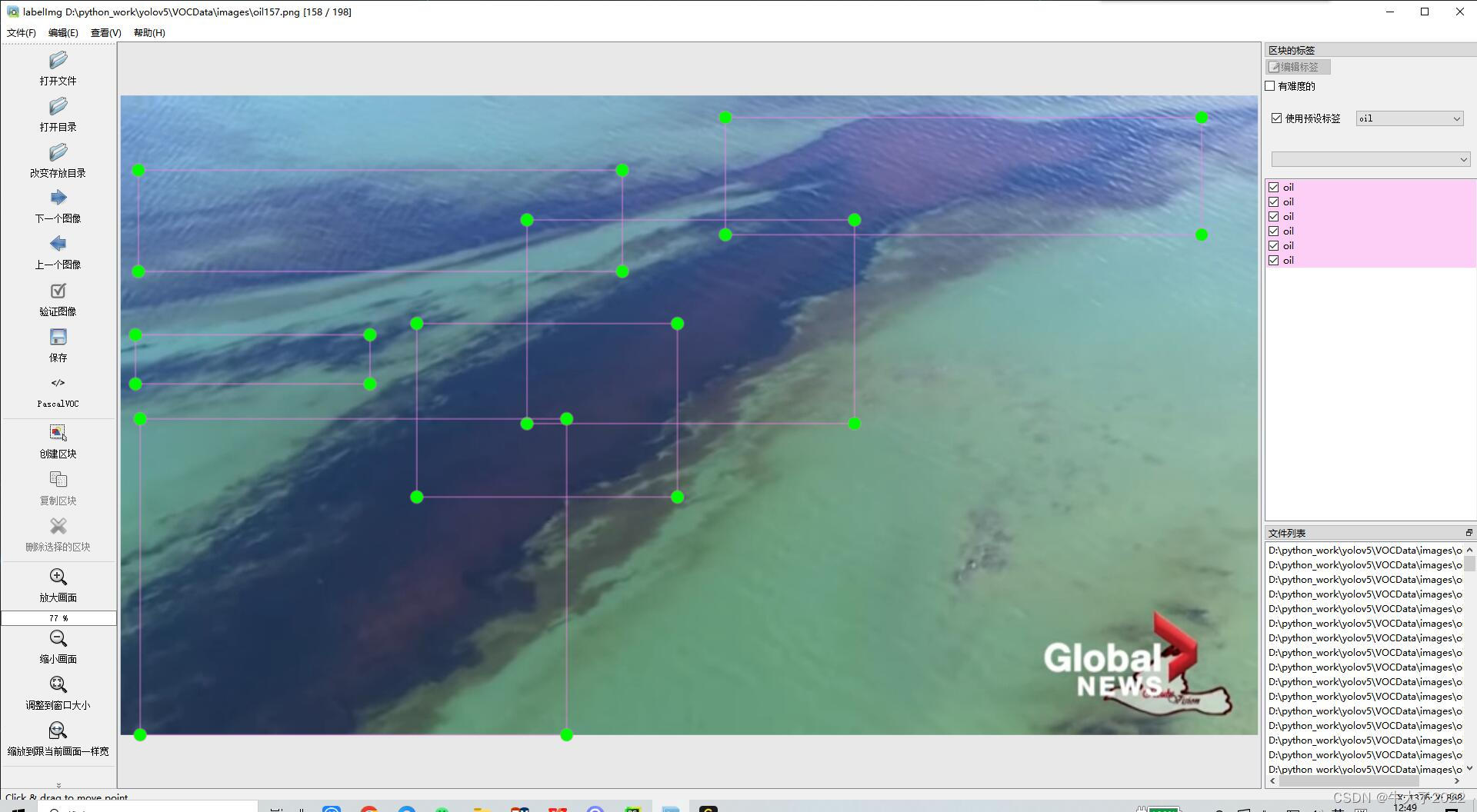
四、拍照
最简单粗暴的方法