网站建设秋实网站seo优化排名
我是标题
- 1.从get?网站获取滑块图片以及token
- 1.1获取fp值
- 1.2 获取cb值
- 1.3 模拟发包
- 2.获取滑块移动距离
- 3.发包获取最终的validate值
- 3.1轨迹生成
- 3.2 check网站发包
- 3.3 获取data值
- 4.结论
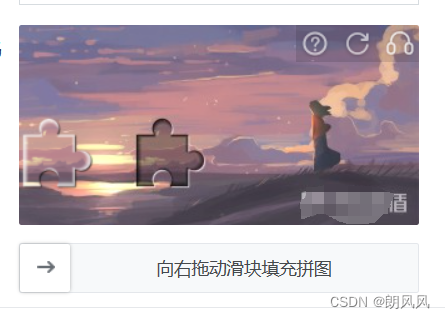
本实验是根据某某盾示例网站
主要分为两个部分
1.从get?网站获取滑块图片以及token
2.根据获取的图片获取滑块移动距离
3.根据移动距离和token发包到check?网站得到validate值
1.从get?网站获取滑块图片以及token
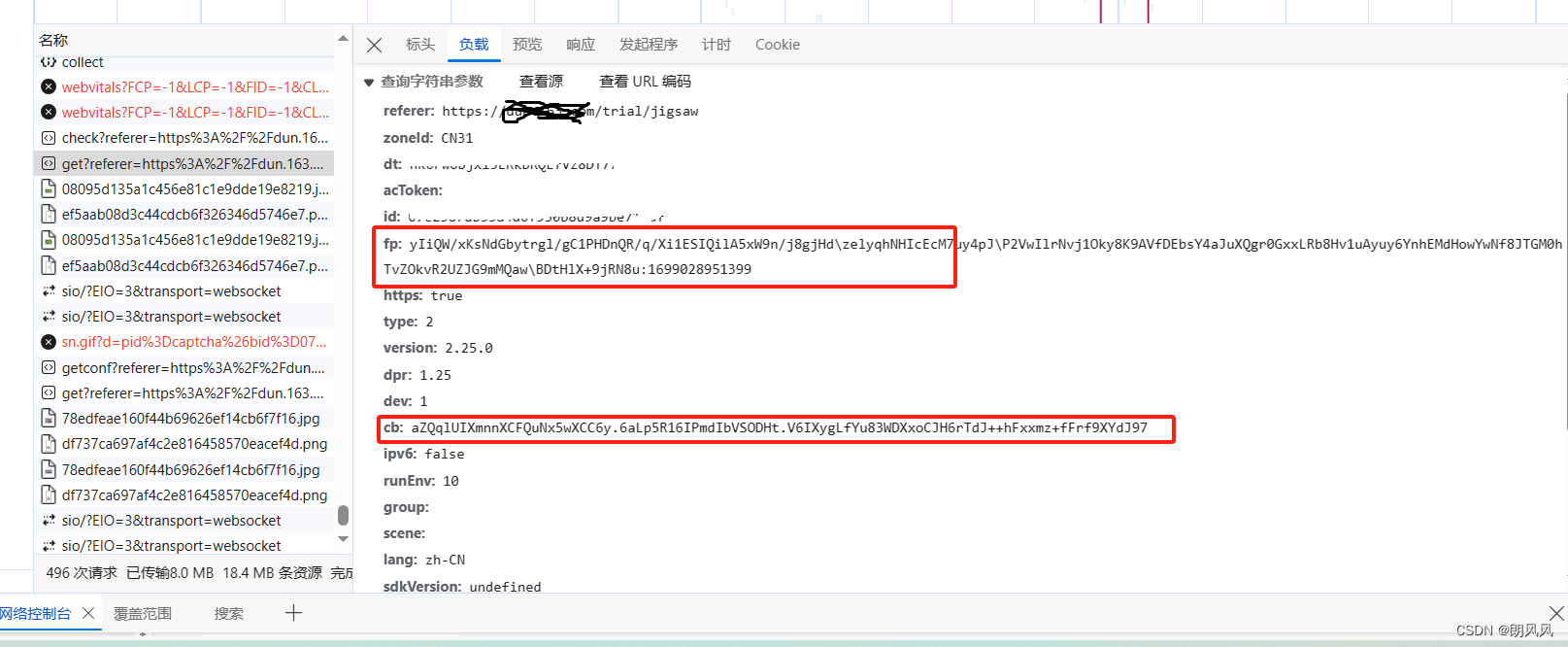
模拟网站发包,需要获取fp值和cb值
1.1获取fp值
网站的js做了混淆,看起来很乱,但是不影响逆向寻找,js代码,具体扣代码的方法就不再介绍了。
可以直接搜索图上关键字可以在网站上找到js具体的位置。
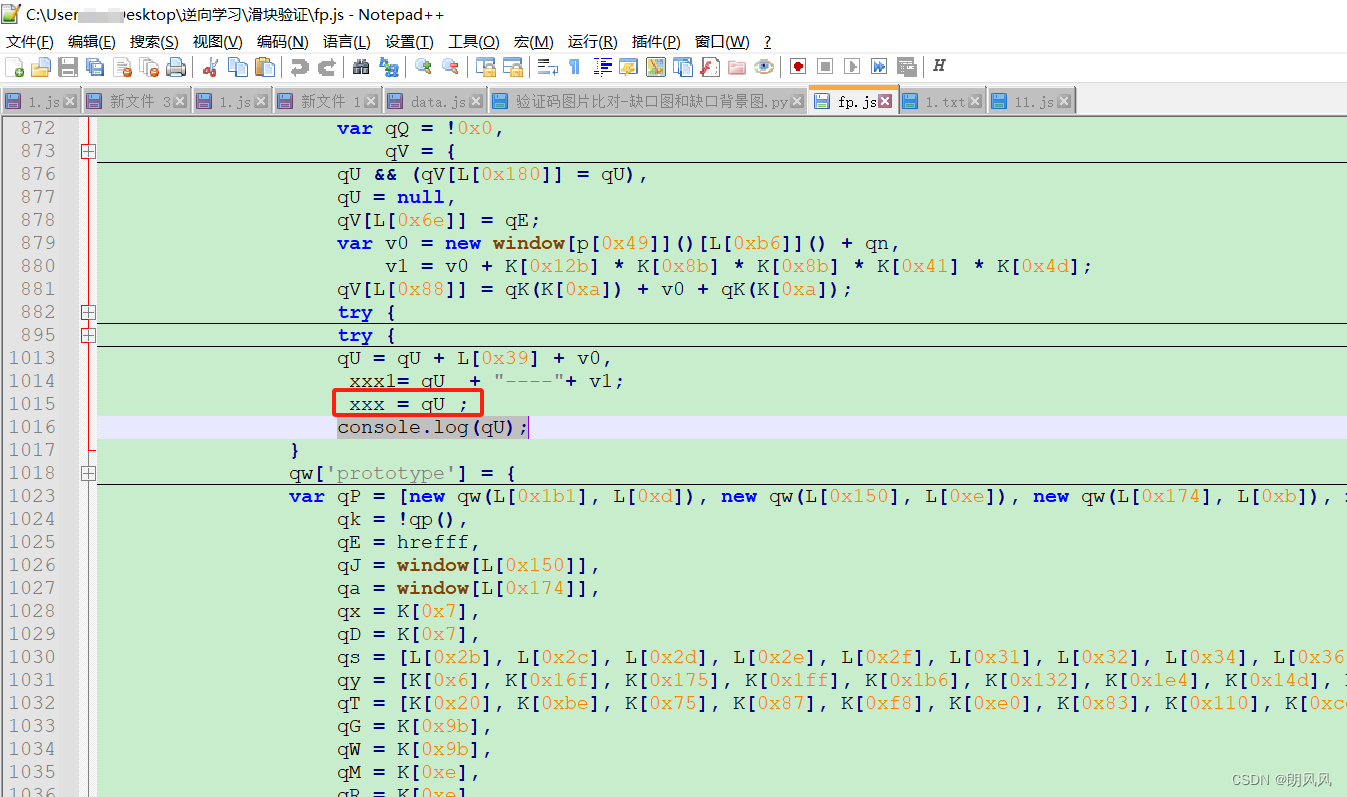
需要注意的是混淆的数组,需要加上下面两个函数,将数组的顺序改为正确的顺序。
还需要注意fp是和网站的域名相关,就是验证应用在的网站域名,设为输入变量hrefff。
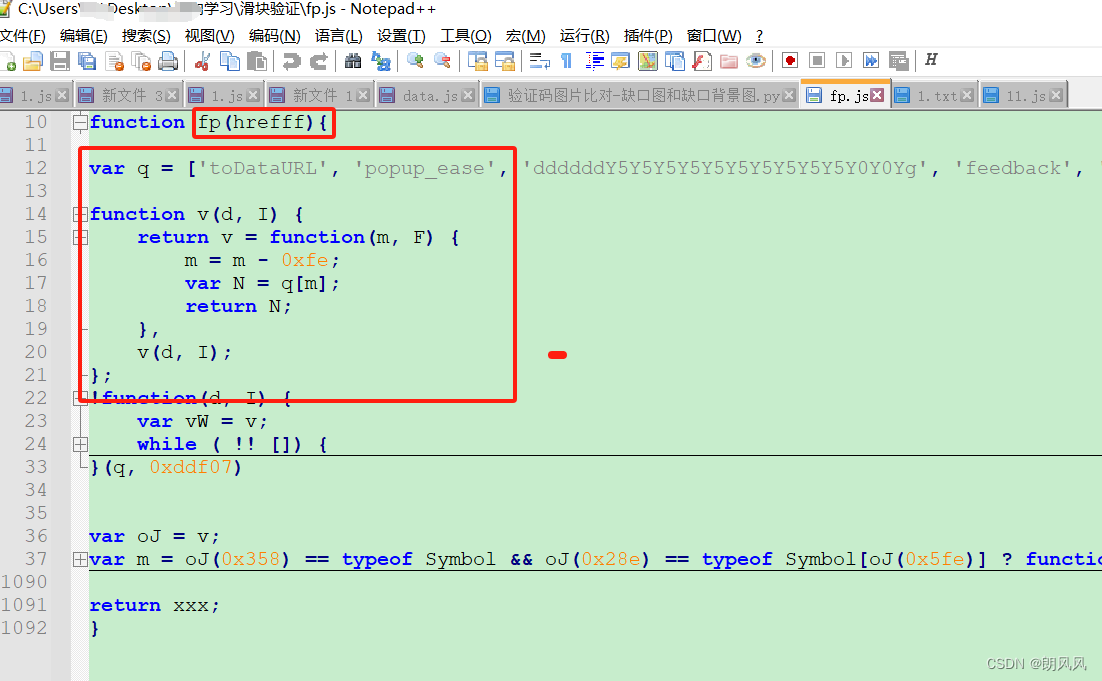
传入变量所在位置
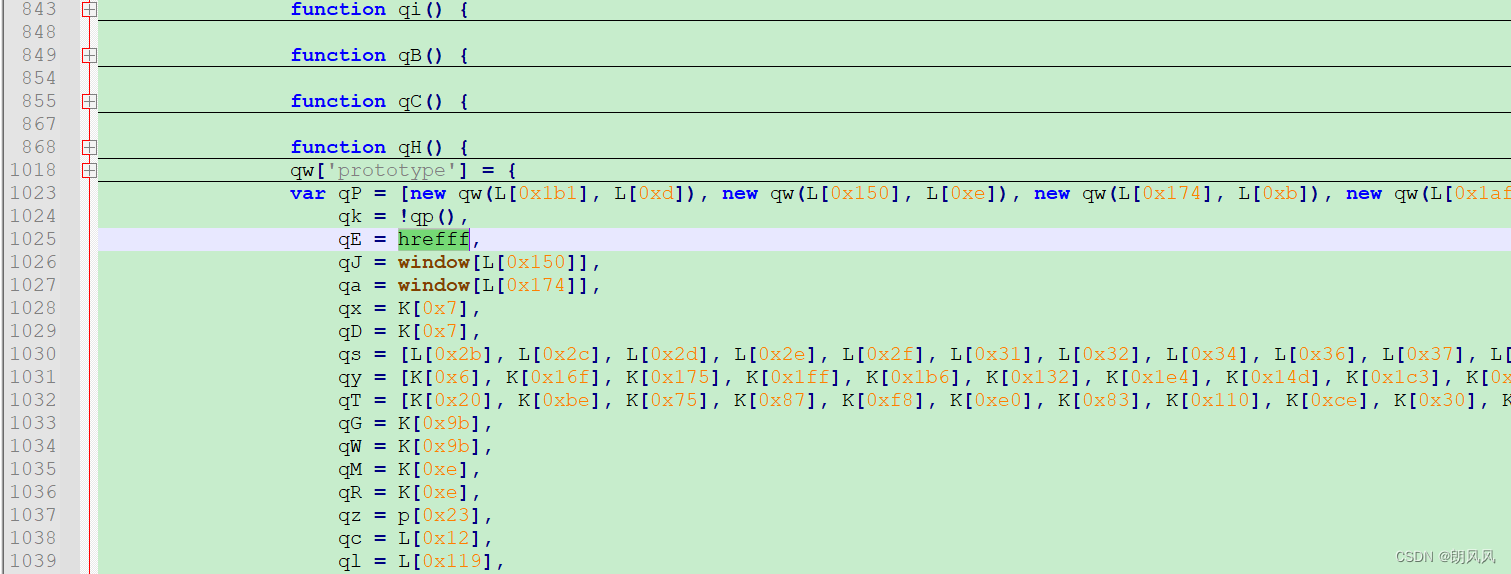
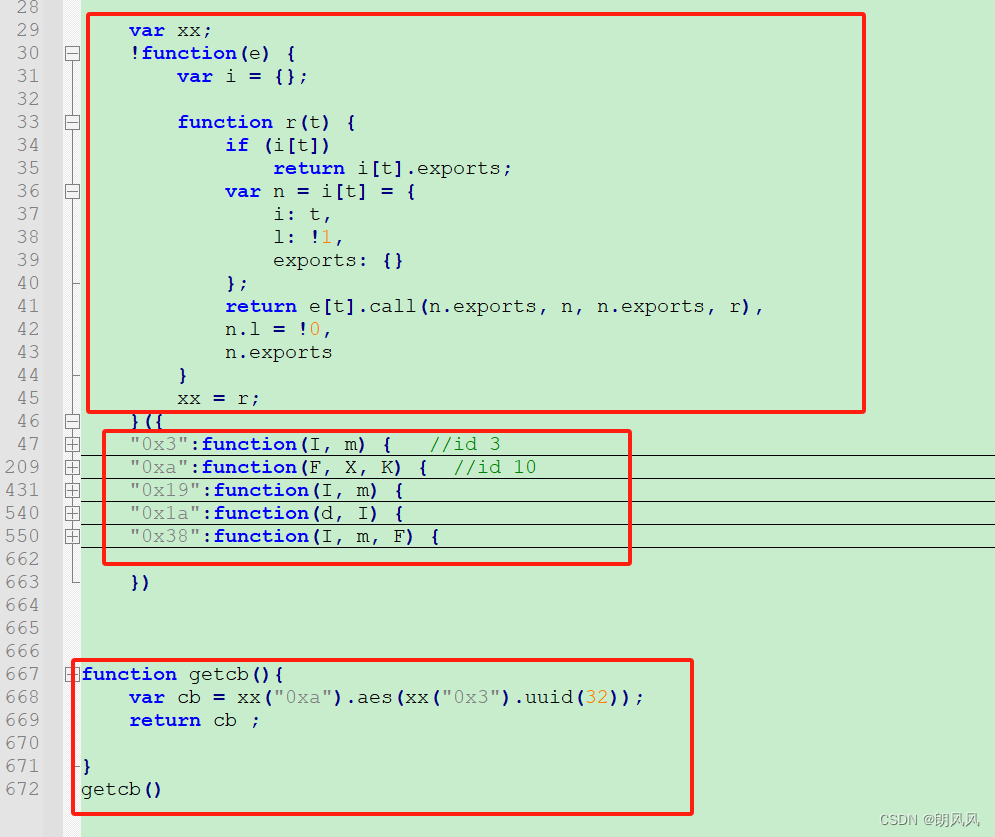
1.2 获取cb值
同样获取cb的js代码也做了混淆,需要加入下面两个函数,注意是两个函数。第二个函数要传入参数。
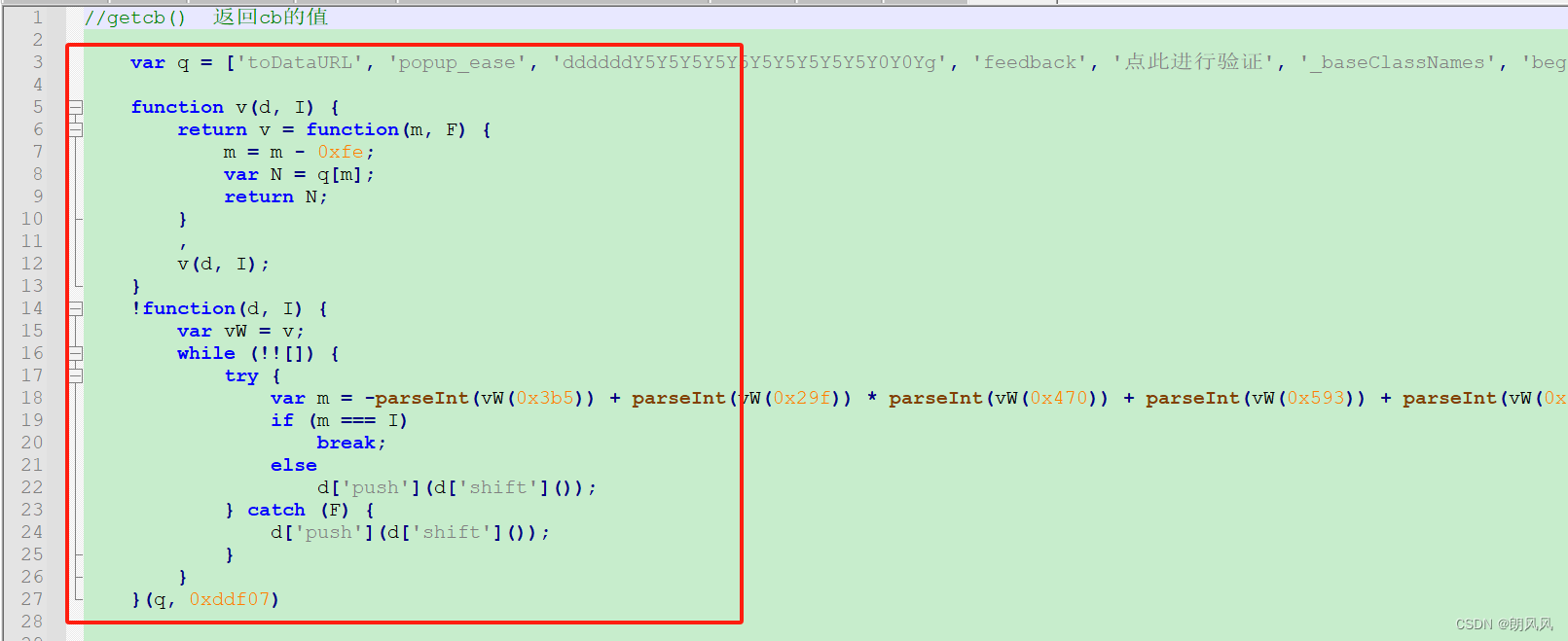
cb原代码在webpack里面,需要加载器。
第一个框为加载器,可以用模板,也可以从源网站拷贝执行器。
第二个框为所需要方法,字典寻找方式。原代码是用十六进制数组方式寻找。具体可以从源代码的加载器寻找0x**,找到具体方法。
第三个框为获取cb执行代码。
1.3 模拟发包
本文中所有用的头文件
import cv2
import numpy as np
import requests
import execjs
import json
import re
import os
import random
import time
用python模拟发包
get_web = 'https://xxxxx/api/v3/get'payload ={"referer":"https://xxxxx/trial/jigsaw","zoneId":"CN31","dt":"yyyyyy","acToken":"undefined","id":"yyyyyy","fp":Get_fp(),"cb":Get_cb(),"https":"true","type":2,"version":"2.25.0","dpr":"1.25","dev":1,"ipv6":"false","runEnv":10,"group":"","scene":"","lang":"zh-CN","sdkVersion":"undefined","iv":3,"width":320,"audio":"false","sizeType":10,"smsVersion":"v3","token":"","callback":"__JSONP_4ti1bll_29"}headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}res = requests.get(get_web, params=payload,headers=headers)print(res.text)res_str = re.search("\((.*?)\);",res.text)#匹配res_json = json.loads(res_str.groups()[0])if (res_json['msg'] == 'ok'):bg_image = res_json['data']['bg']ft_image = res_json['data']['front']token = res_json['data']['token']save_image(bg_image,'bg_image.png')save_image(ft_image,'ft_image.png')
执行js文件
def js_from_file(file_name):"""读取js文件:return:"""with open(file_name, 'r', encoding='UTF-8') as file:result = file.read()string = "\/*解决浏览器环境问题*/\const { JSDOM }= require('jsdom');\const dom = new JSDOM('<!DOCTYPE html><p>Hello world</p>');\const window = dom.window;\const document = window.document;\XMLHttpRequest = window.XMLHttpRequest;\"return (string + result)
def Get_fp():# 编译加载js字符串context1 = execjs.compile(js_from_file('..\\fp.js'),cwd=r'C:\Users\xxx\AppData\Roaming\npm\node_modules') #使用 execjs 类的compile()方法编译加载上面的 JS 字符串,返回一个上下文对象fp = context1.call('fp','dun.163.com')#print(fp)return fpdef Get_cb():# 编译加载js字符串context1 = execjs.compile(js_from_file('..\\cb.js'),cwd=r'C:\Users\xxx\AppData\Roaming\npm\node_modules') #使用 execjs 类的compile()方法编译加载上面的 JS 字符串,返回一个上下文对象cb = context1.eval("getcb()")#print(cb)return cb

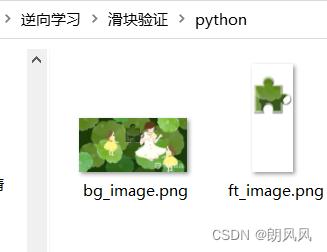
2.获取滑块移动距离
具体不再解释,主要是通过灰度图的边缘化后图片做匹配,直接可以返回两者相差的距离。注意距离是x方向和y方向都有,返回只取了x方向的值。
#获取滑块在背景上位置
def slider_location(slider_img,bg_image):"""TM_SQDIFF 平方差匹配法 该方法采用平方差来进行匹配;最好的匹配值为0;匹配越差,匹配值越大TM_CCORR 相关匹配法 该方法采用乘法操作;数值越大表明匹配程度越好。TM_CCOEFF 相关系数匹配法 1表示完美的匹配;-1表示最差的匹配。TM_SQDIFF_NORMED 归一化平方差匹配法 TM_CCORR_NORMED 归一化相关匹配法 TM_CCOEFF_NORMED 归一化相关系数匹配法"""res = cv2.matchTemplate(bg_image,slider_img,cv2.TM_CCOEFF_NORMED)threshold = 0.9while (len(np.where(res >= threshold)[1])==0 and threshold!=0):threshold-=0.1if (threshold):return np.where(res >= threshold)[1] #选取x坐标的第0个值else:return 0
#获取滑动距离 返回距离
def get_distance():slider_img =cv2.imread('.\\bg_image.png',0) #0获取灰度值bg_image=cv2.imread('.\\ft_image.png',0)# 识别图片边缘bg_edge = cv2.Canny(bg_image, 100, 200)tp_edge = cv2.Canny(slider_img, 100, 200)cv2.imwrite('sd_image1.png',tp_edge)cv2.imwrite('bg_image1.png',bg_edge)return slider_location(tp_edge,bg_edge)[0]

3.发包获取最终的validate值
3.1轨迹生成
根据滑块移动距离和第一步返回的cookie值发包核对得到validate值。
根据滑块的移动距离需要构造轨迹坐标,我的轨迹坐标方法比较烂,就不贴出来了。是下图这种样子的。

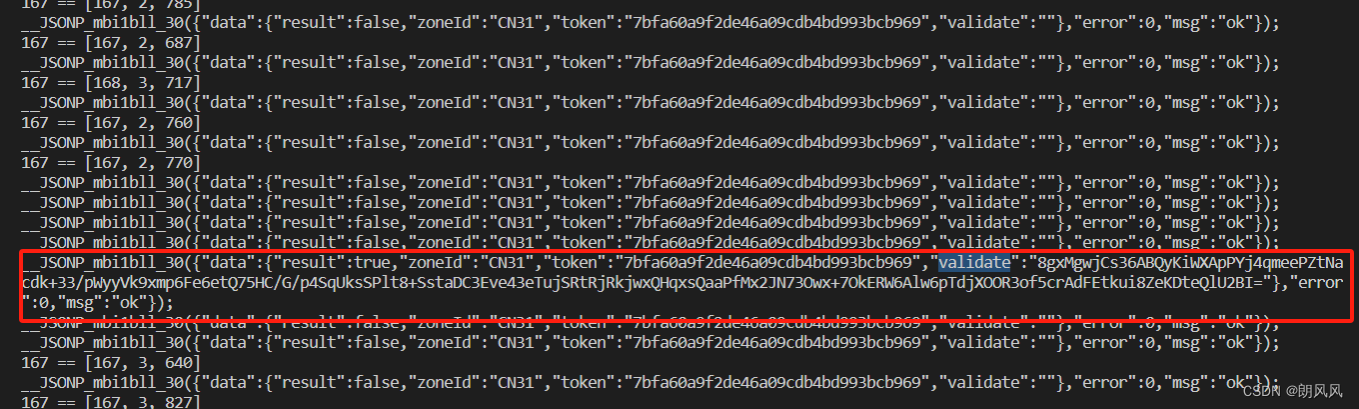
3.2 check网站发包
如下ts_str 就是轨迹的json的转字符串形式
注意token一定要和get?返回的一样。
get_web = 'https://xxxxx/api/v3/check'payload ={"referer":"https://xxxxx/trial/jigsaw","zoneId":"CN31","dt":"yyyyyy","id":"yyyyyyyyyyy","acToken":"undefined","token":token,"data":Get_data(token,ts_str),"width":320,"type":2,"version":"2.25.0","cb":Get_cb(),'extraData':"",'bf':0,"runEnv":10,"sdkVersion":"undefined","iv":3,"callback":"__JSONP_mbi1bll_30"} #随机生成callbackres = requests.get(get_web, params=payload,headers=headers)if len(res.text)> 150:print(res.text)return 1#print(token)return 0

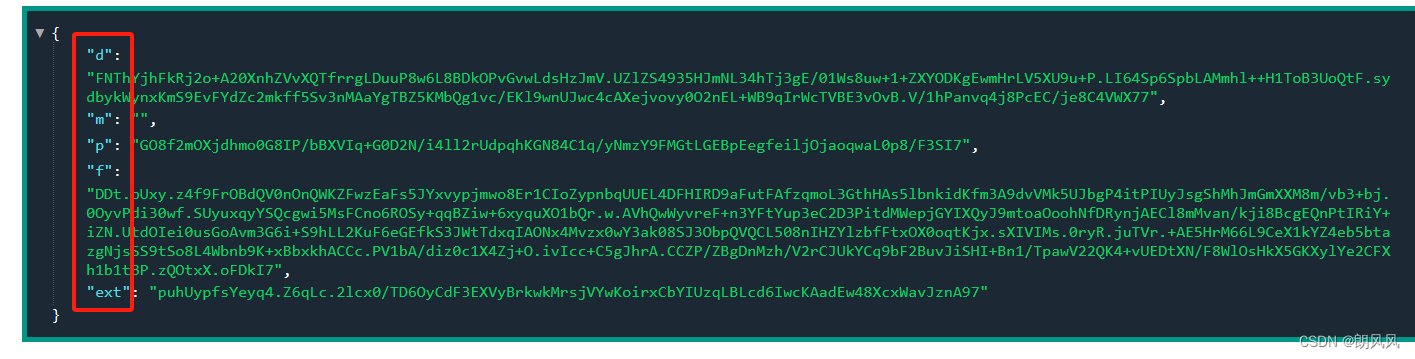
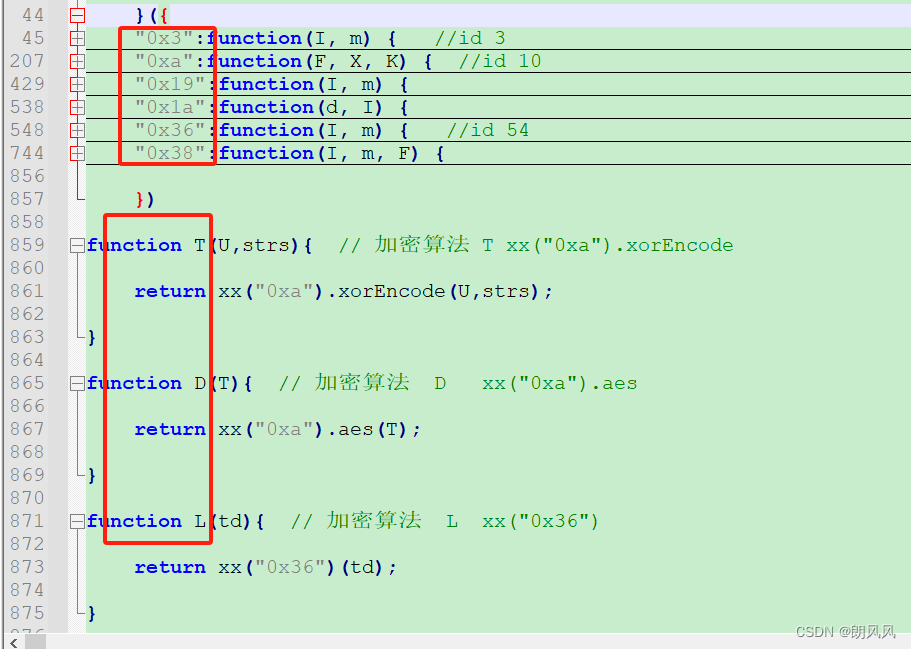
3.3 获取data值
data为字典的转字符串的形式,内包含很多加密变量。

4.结论
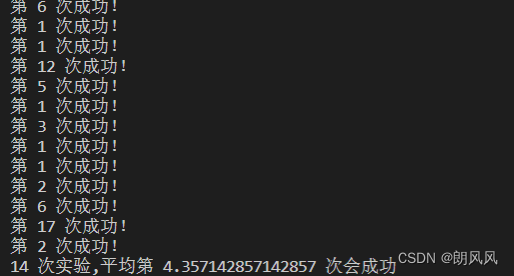
现在的成功率不高,应该是滑块轨迹做的不好,很容易被发现,以后可以再具体研究。
做了20次实验,
6次超过20次以外
14次平均成功次数为小于5次