wetest网站开发怎么制作一个简单的网页
1.分组统计groupby()函数
对数据进行分组统计,主要适用DataFrame对象的groupby()函数。其功能如下。
(1)根据特定条件,将数据拆分成组
(2)每个组都可以独立应用函数(如求和函数sum(),均值函数mean()等)
(3)将结果合并到一个数据结构中
示例1:
根据“一级分类”对订单数据进行分组统计求和。
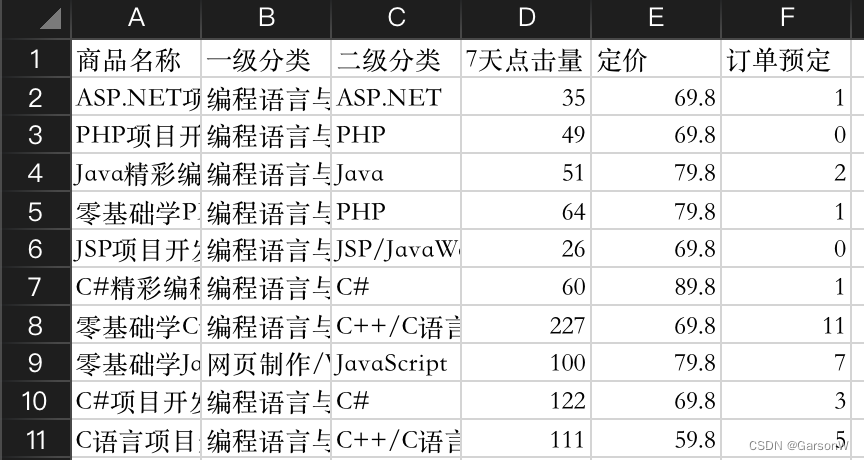
import pandas as pd #导入pandas模块
df=pd.read_csv('JD.csv',encoding='gbk')
#抽取数据
df1=df[['一级分类','7天点击量','订单预定']]
df1=df1.groupby('一级分类').sum() #分组统计求和
示例2:
按照图书“一级分类”和“二级分类”对订单数据进行分组统计求和
import pandas as pd #导入pandas模块
df=pd.read_csv('JD.csv',encoding='gbk')
#抽取数据
df1=df[['一级分类','二级分类','7天点击量','订单预定']]
df2=df1.groupby(['一级分类','二级分类']).sum() #分组统计求和
示例3:
求各二级分类的七天点击量。首先按“二级分类”分类,而后进行分组统计求和。
df1 = df1.groupby('二级分类')['七天点击量'].sum()2.对分组数据进行迭代
示例1:
按照“一级分类”分组,并且输出每一分类中的订单数据
# 抽取数据
df1 = df[['一级分类',‘七天点击量’,‘订单预定’]]
for name, group in df.groupby('一级分类')print(name)print(group)其中name是‘一级分类’, group是其他数据。因此使用groupby()函数对多列进行分组,那么需要在for循环中指定多列。
3.对分组的某列或多列使用聚合函数
Python也可以实现像SQL中的分组聚合运算操作,主要通过groupby()函数与agg()函数实现。
以下代码实现:
1. 以'一级分类'分组,求分组后的平均值与和
2.以'一级分类'分组,求分组后'七天点击量'的平均值与和,求'订单预定'的和
df1.groupby('一级分类').agg(['mean','sum'])df1.groupby('一级分类').agg({'七天点击量':['mean','sum'],'订单预定':['sum']})我们可以通过自定义函数实现数组分组统计。书本p110
以下代码实现:
1.统计一月份销售数据中,购买次数最多的产品,及其人均购买数,人均花费,总购买数,总花费。
df = pd.read_excel('1月.xlsx')
max1 = lambda x: x.value_counts(dropna=false).index[0]
df1 = df.agg({'宝贝标题':[max1],'数量':['sum','mean'],'卖家实际支付金额':['sum','mean']})
print(df1)4.通过字典和Series对象进行分组统计
1.通过字典进行分组统计
创建字典,df.groupby()函数通过字典内信息分组。
import pandas as pd #导入pandas模块
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df=pd.read_csv('JD.csv',encoding='gbk') #导入csv文件
df=df.set_index(['商品名称'])
#创建字典
mapping={'北京出库销量':'北上广','上海出库销量':'北上广','广州出库销量':'北上广','成都出库销量':'成都','武汉出库销量':'武汉','西安出库销量':'西安'}
df1=df.groupby(mapping,axis=1).sum()
print(df1)
2.通过Series对象进行分组统计
创建一个Series对象,然后将Series对象传给groupby()函数实现数据分组。Series对象内放索引+值:如'北京出库销量',对应值'北上广'。
import pandas as pd #导入pandas模块
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.east_asian_width', True)
df=pd.read_csv('JD.csv',encoding='gbk') #导入csv文件
df=df.set_index(['商品名称'])
data={'北京出库销量':'北上广','上海出库销量':'北上广','广州出库销量':'北上广','成都出库销量':'成都','武汉出库销量':'武汉','西安出库销量':'西安',}
s1=pd.Series(data)
print(s1)
df1=df.groupby(s1,axis=1).sum()
print(df1)