深圳图派做的网站后台加什么百度推广客服人工电话多少
CGAN通过在生成器和判别器中均使用标签信息进行训练,不仅能产生特定标签的数据,还能够提高生成数据的质量;SGAN(Semi-Supervised GAN)通过使判别器/分类器重建标签信息来提高生成数据的质量。既然这两种思路都可以提高生成数据的质量,于是ACGAN综合了以上两种思路,既使用标签信息进行训练,同时也重建标签信息,结合CGAN和SGAN的优点,从而进一步提升生成样本的质量,并且还能根据指定的标签相应的样本。
1. ACGAN的网络结构为:
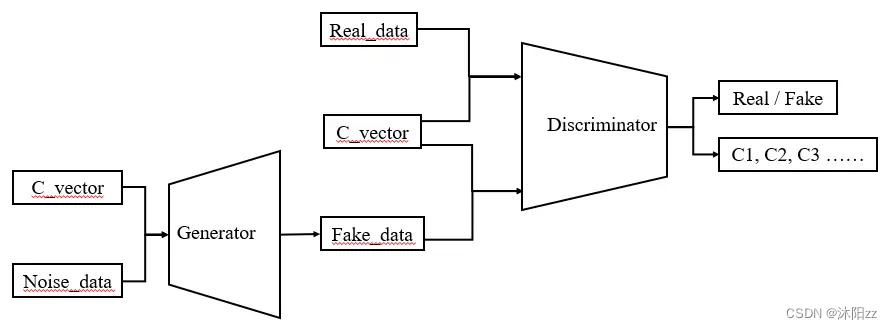
ACGAN的网络结构框图
生成器的输入包含C_vector和Noise_data两个部分,其中C_vector为训练数据标签信息的One-hot编码张量,其形状为:(batch_size, num_class) ;Noise_data的形状为:(batch_size, latent_dim)。然后将两者进行拼接,拼接完成后,得到的输入张量为:(batch_size, num_class + latent_dim)。生成器的的输出张量为:(batch_size, channel, Height, Width)。
判别器的输入为:(batch_size, channel, Height, Width); 判别的器的输出为两部分,一部分是源数据真假的判断,形状为:(batch_size, 1),一部分是输入数据的分类结果,形状为:(batch_size, class_num)。因此判别器的最后一层有两个并列的全连接层,分别得到这两部分的输出结果,即判别器的输出有两个张量(真假判断张量和分类结果张量)。
2. ACGAN的损失函数:
对于判别器而言,既希望分类正确,又希望能正确分辨数据的真假;对于生成器而言,也希望能够分类正确,当时希望判别器不能正确分辨假数据。
D_real, C_real = Discriminator( real_imgs) # real_img 为输入的真实训练图片
D_real_loss = torch.nn.BCELoss(D_real, Y_real) # Y_real为真实数据的标签,真数据都为-1,假数据都为+1
C_real_loss = torch.nn.CrossEntropyLoss(C_real, Y_vec) # Y_vec为训练数据One-hot编码的标签张量
gen_imgs = Generator(noise, Y_vec)
D_fake, C_fake = Discriminator(gen_imgs)
D_fake_loss = torch.nn.BCELoss(D_fake, Y_fake)
C_fake_loss = torch.nn.CrossEntropyLoss(C_fake, Y_vec)
D_loss = D_real_loss + C_real_loss + D_fake_loss + C_fake_loss
生成器的损失函数:
gen_imgs = Generator(noise, Y_vec)
D_fake, C_fake = Discriminator(gen_imgs)
D_fake_loss = torch.nn.BCELoss(D_fake, Y_real)
C_fake_loss = torch.nn.CrossEntropyLoss(C_fake, Y_vec)
G_loss = D_fake_loss + C_fake_loss
class Discriminator(nn.Module): # 定义判别器def __init__(self, img_size=(64, 64), num_classes=2): # 初始化方法super(Discriminator, self).__init__() # 继承初始化方法self.img_size = img_size # 图片尺寸,默认为(64.64)三通道图片self.num_classes = num_classes # 类别数self.conv1 = nn.Conv2d(3, 128, 4, 2, 1) # conv操作self.conv2 = nn.Conv2d(128, 256, 4, 2, 1) # conv操作self.bn2 = nn.BatchNorm2d(256) # bn操作self.conv3 = nn.Conv2d(256, 512, 4, 2, 1) # conv操作self.bn3 = nn.BatchNorm2d(512) # bn操作self.conv4 = nn.Conv2d(512, 1024, 4, 2, 1) # conv操作self.bn4 = nn.BatchNorm2d(1024) # bn操作self.leakyrelu = nn.LeakyReLU(0.2) # leakyrelu激活函数self.linear1 = nn.Linear(int(1024 * (self.img_size[0] / 2 ** 4) * (self.img_size[1] / 2 ** 4)), 1) # linear映射self.linear2 = nn.Linear(int(1024 * (self.img_size[0] / 2 ** 4) * (self.img_size[1] / 2 ** 4)),self.num_classes) # linear映射self.sigmoid = nn.Sigmoid() # sigmoid激活函数self.softmax = nn.Softmax(dim=1) # softmax激活函数self._init_weitghts() # 模型权重初始化def _init_weitghts(self): # 定义模型权重初始化方法for m in self.modules(): # 遍历模型结构if isinstance(m, nn.Conv2d): # 如果当前结构是convnn.init.normal_(m.weight, 0, 0.02) # w采用正态分布初始化nn.init.constant_(m.bias, 0) # b设为0elif isinstance(m, nn.BatchNorm2d): # 如果当前结构是bnnn.init.constant_(m.weight, 1) # w设为1nn.init.constant_(m.bias, 0) # b设为0elif isinstance(m, nn.Linear): # 如果当前结构是linearnn.init.normal_(m.weight, 0, 0.02) # w采用正态分布初始化nn.init.constant_(m.bias, 0) # b设为0def forward(self, x): # 前传函数x = self.conv1(x) # conv,(n,3,64,64)-->(n,128,32,32)x = self.leakyrelu(x) # leakyrelu激活函数x = self.conv2(x) # conv,(n,128,32,32)-->(n,256,16,16)x = self.bn2(x) # bn操作x = self.leakyrelu(x) # leakyrelu激活函数x = self.conv3(x) # conv,(n,256,16,16)-->(n,512,8,8)x = self.bn3(x) # bn操作x = self.leakyrelu(x) # leakyrelu激活函数x = self.conv4(x) # conv,(n,512,8,8)-->(n,1024,4,4)x = self.bn4(x) # bn操作x = self.leakyrelu(x) # leakyrelu激活函数x = torch.flatten(x, 1) # 三维特征压缩至一位特征向量,(n,1024,4,4)-->(n,1024*4*4)# 根据特征向量x,计算图片真假的得分validity = self.linear1(x) # linear映射,(n,1024*4*4)-->(n,1)validity = self.sigmoid(validity) # sigmoid激活函数,将输出压缩至(0,1)# 根据特征向量x,计算图片分类的标签label = self.linear2(x) # linear映射,(n,1024*4*4)-->(n,2)label = self.softmax(label) # softmax激活函数,将输出压缩至(0,1)return (validity, label) # 返回(图像真假的得分,图片分类的标签)class Generator(nn.Module): # 定义生成器def __init__(self, img_size=(64, 64), num_classes=2, latent_dim=100): # 初始化方法super(Generator, self).__init__() # 继承初始化方法self.img_size = img_size # 图片尺寸,默认为(64.64)三通道图片self.num_classes = num_classes # 类别数self.latent_dim = latent_dim # 输入噪声长度,默认为100self.linear = nn.Linear(self.latent_dim, 4 * 4 * 1024) # linear映射self.bn0 = nn.BatchNorm2d(1024) # bn操作self.deconv1 = nn.ConvTranspose2d(1024, 512, 4, 2, 1) # transconv操作self.bn1 = nn.BatchNorm2d(512) # bn操作self.deconv2 = nn.ConvTranspose2d(512, 256, 4, 2, 1) # transconv操作self.bn2 = nn.BatchNorm2d(256) # bn操作self.deconv3 = nn.ConvTranspose2d(256, 128, 4, 2, 1) # transconv操作self.bn3 = nn.BatchNorm2d(128) # bn操作self.deconv4 = nn.ConvTranspose2d(128, 3, 4, 2, 1) # transconv操作self.relu = nn.ReLU(inplace=True) # relu激活函数self.tanh = nn.Tanh() # tanh激活函数self.embedding = nn.Embedding(self.num_classes, self.latent_dim) # embedding操作self._init_weitghts() # 模型权重初始化def _init_weitghts(self): # 定义模型权重初始化方法for m in self.modules(): # 遍历模型结构if isinstance(m, nn.ConvTranspose2d): # 如果当前结构是transconvnn.init.normal_(m.weight, 0, 0.02) # w采用正态分布初始化nn.init.constant_(m.bias, 0) # b设为0elif isinstance(m, nn.BatchNorm2d): # 如果当前结构是bnnn.init.constant_(m.weight, 1) # w设为1nn.init.constant_(m.bias, 0) # b设为0elif isinstance(m, nn.Linear): # 如果当前结构是linearnn.init.normal_(m.weight, 0, 0.02) # w采用正态分布初始化nn.init.constant_(m.bias, 0) # b设为0def forward(self, input: tuple): # 前传函数noise, label = input # 从输入的元组中获取噪声向量和标签信息label = self.embedding(label) # 标签信息经过embedding操作,变成与噪声向量尺寸相同的稠密向量z = torch.multiply(noise, label) # 噪声向量与标签稠密向量相乘,得到带有标签信息的噪声向量z = self.linear(z) # linear映射,(n,100)-->(n,1024*4*4)z = z.view((-1, 1024, int(self.img_size[0] / 2 ** 4),int(self.img_size[1] / 2 ** 4))) # 一维特征向量扩展至三维特征,(n,1024*4*4)-->(n,1024,4,4)z = self.bn0(z) # bn操作z = self.relu(z) # relu激活函数z = self.deconv1(z) # trainsconv操作,(n,1024,4,4)-->(n,512,8,8)z = self.bn1(z) # bn操作z = self.relu(z) # relu激活函数z = self.deconv2(z) # trainsconv操作,(n,512,8,8)-->(n,256,16,16)z = self.bn2(z) # bn操作z = self.relu(z) # relu激活函数z = self.deconv3(z) # trainsconv操作,(n,256,16,16)-->(n,128,32,32)z = self.bn3(z) # bn操作z = self.relu(z) # relu激活函数z = self.deconv4(z) # trainsconv操作,(n,128,32,32)-->(n,3,64,64)z = self.tanh(z) # tanh激活函数,将输出压缩至(-1,1)return z # 返回生成图像