网站设计 配色南宁百度快速排名优化
一、需求背景
在截取到浏览器user-agent,并想保存入数据库中,经查询发现展示的为编码后的结果。
现需要经过url解码过程,将解码后的结果保存进数据库,那么有几种实现方式。
二、问题解决
1、百度:url在线解码工具
输入下述内容,得到解码后的结果
Mozilla/5.0%20(Macintosh;%20Intel%20Mac%20OS%20X%2010_6_8)%20AppleWebKit/537.13+%20(KHTML,%20like%20Gecko)%20Version/5.1.7%20Safari/534.57.2
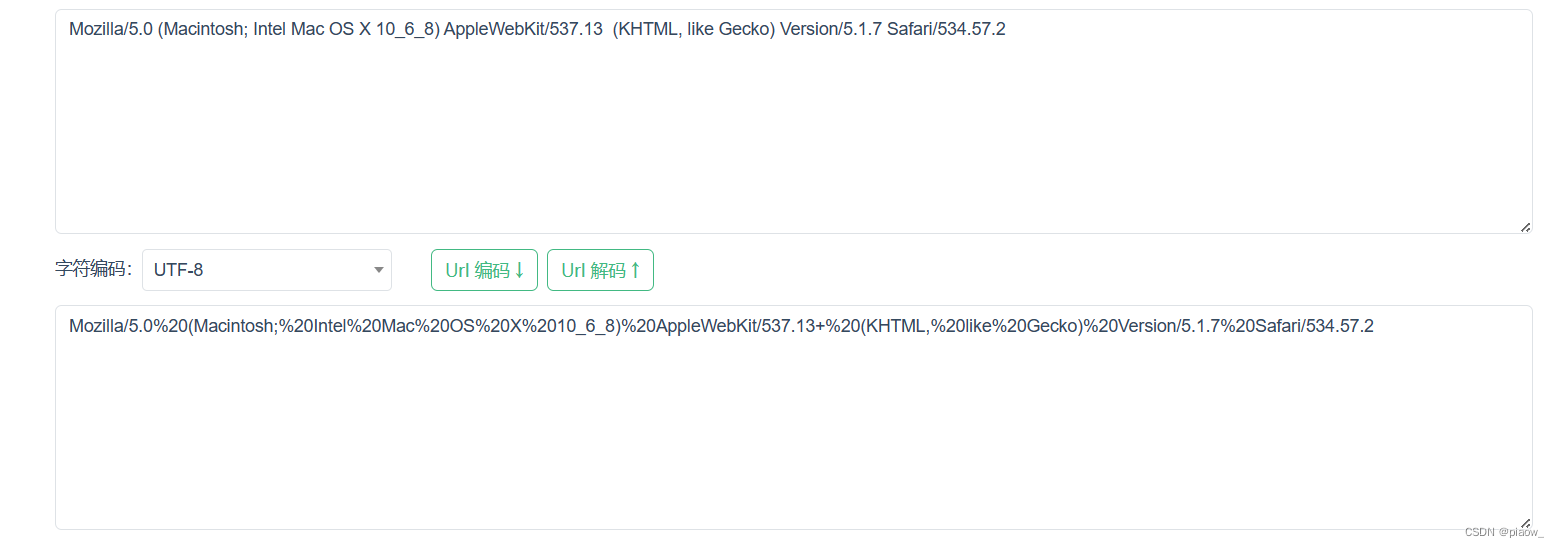
但不能对每一个ua都在线进行完解码后,再存入数据库,操作量太大了,重复!
2、借助java程序实现
通过URLDecoder.decode()方法,将参数填入进去,最后输出解码后的结果来实现。
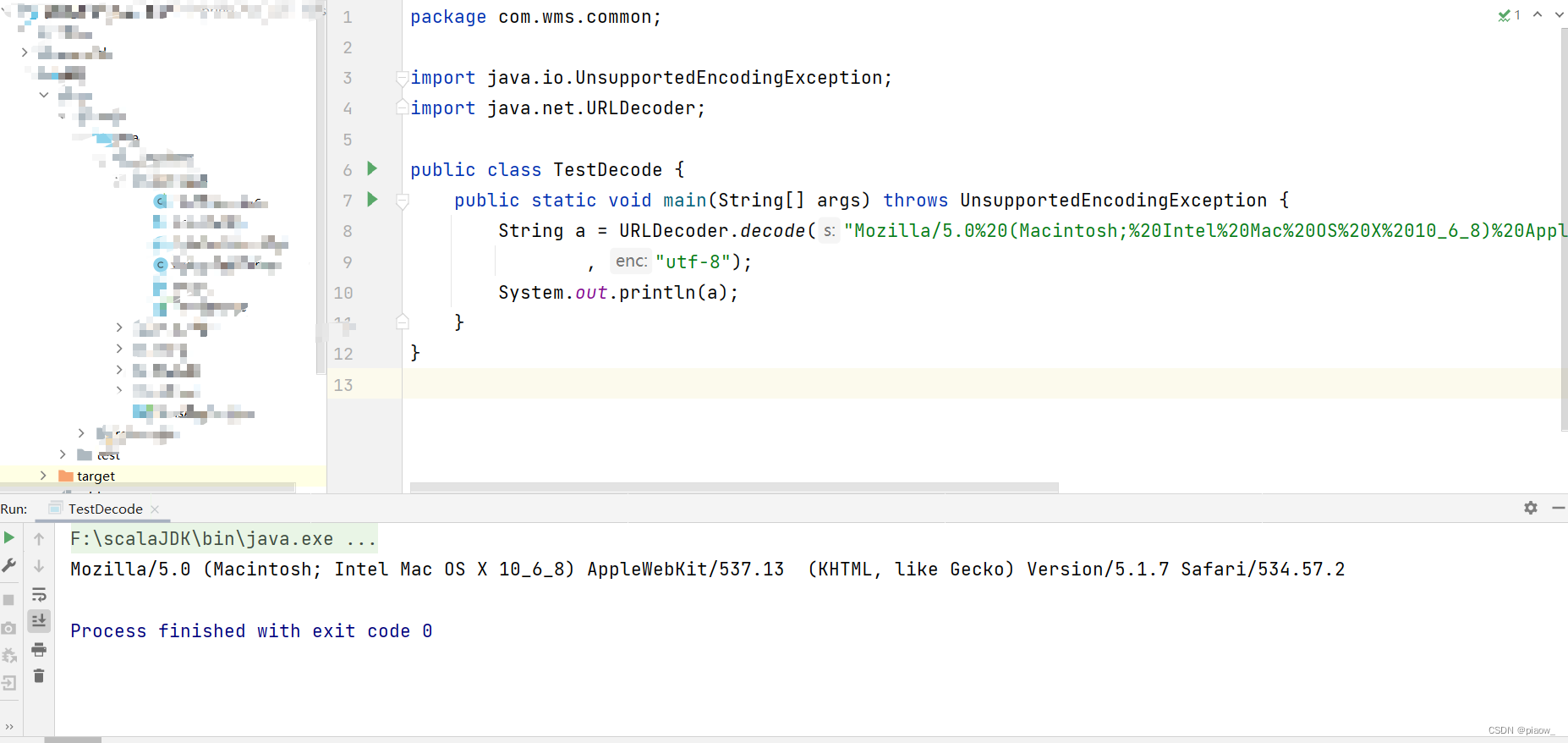
即可以通过Hive自定义UDF函数的形式,将上述方法进行封装使用。
3、借助Hive的反射实现
先看下反射的详细情况
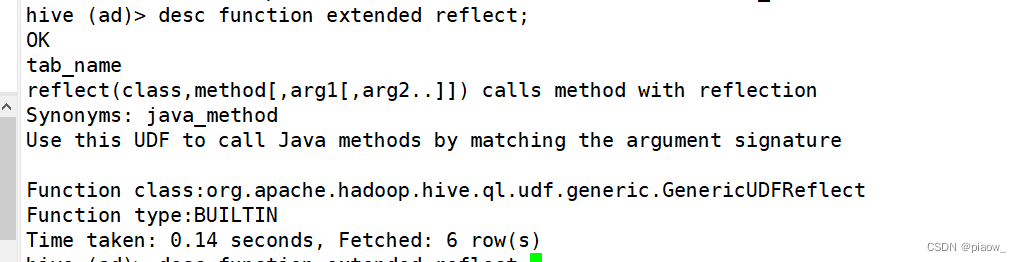
可以看到,先写类名,再写方法名,参数可有可无
运行结果展示,优于自定义UDF函数,更简便:
