广州市住房建设公租房网站手机流畅优化软件
目录
Vision Transformer如何工作
ViT模型架构
ViT工作原理解析
步骤1:将图片转换成patches序列
步骤2:将patches铺平
步骤3:添加Position embedding
步骤4:添加class token
步骤5:输入Transformer Encoder
步骤6:分类
总结
Vision Transformer(VIT)与卷积神经网络(CNN)相比
数据效率和泛化能力:
可解释性和可调节性:
Vision Transformer如何工作
我们知道Transformer模型最开始是用于自然语言处理(NLP)领域的,NLP主要处理的是文本、句子、段落等,即序列数据。但是视觉领域处理的是图像数据,因此将Transformer模型应用到图像数据上面临着诸多挑战,理由如下:
- 与单词、句子、段落等文本数据不同,图像中包含更多的信息,并且是以像素值的形式呈现。
- 如果按照处理文本的方式来处理图像,即逐像素处理的话,即使是目前的硬件条件也很难。
- Transformer缺少CNNs的归纳偏差,比如平移不变性和局部受限感受野。
- CNNs是通过相似的卷积操作来提取特征,随着模型层数的加深,感受野也会逐步增加。但是由于Transformer的本质,其在计算量上会比CNNs更大。
- Transformer无法直接用于处理基于网格的数据,比如图像数据。
为了解决上述问题,Google的研究团队提出了ViT模型,它的本质其实也很简单,既然Transformer只能处理序列数据,那么我们就把图像数据转换成序列数据就可以了呗。下面来看下ViT是如何做的。
ViT模型架构
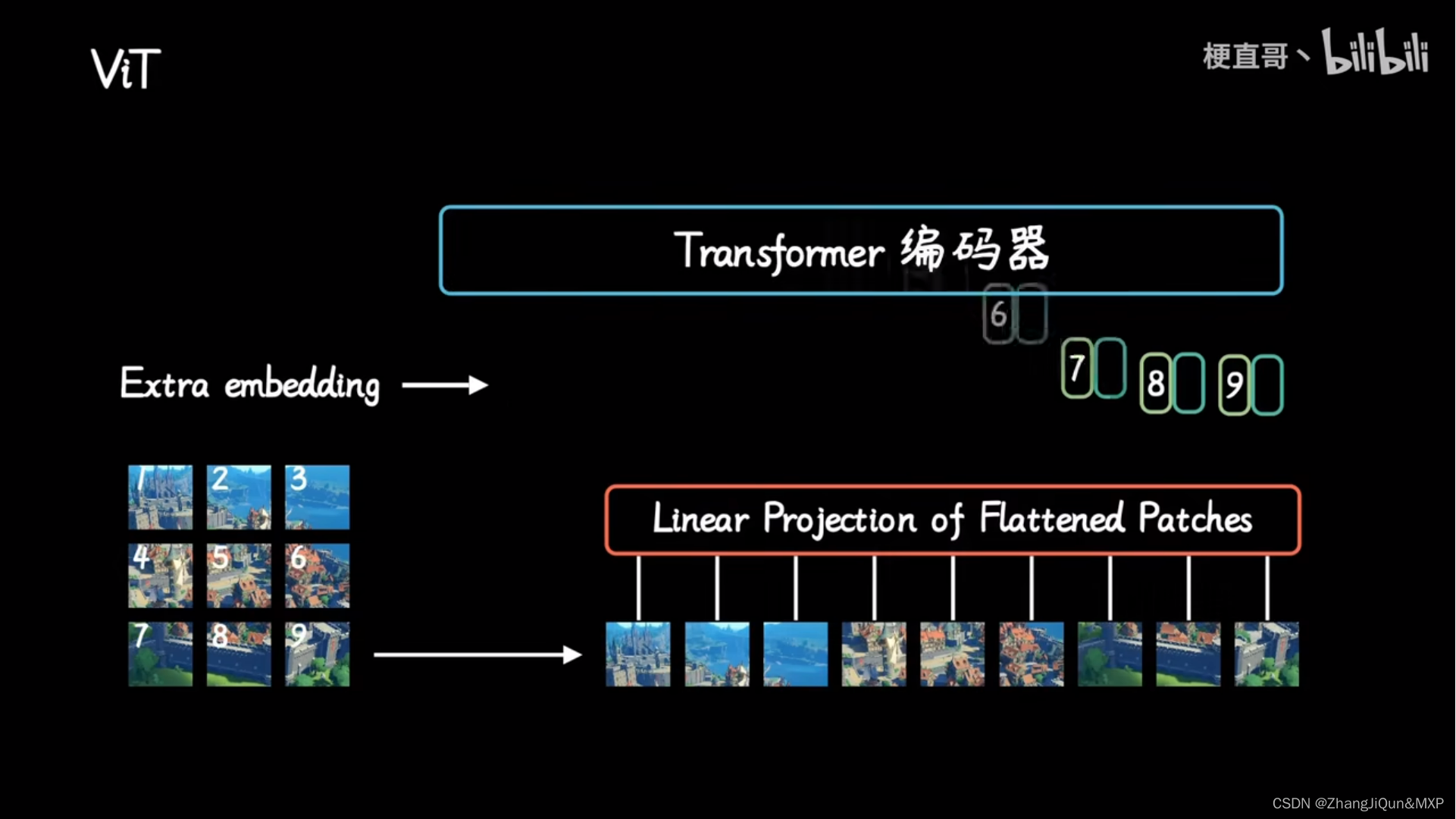
我们先结合下面的动图来粗略地分析一下ViT的工作流程,如下:
- 将一张图片分成patches;
- 将patches铺平;
- 将铺平后的patches的线性映射到更低维的空间;
- 添加位置embedding编码信息;
- 将图像序列数据送入标准Transformer encoder中去;
- 在较大的数据集上预训练;
- 在下游数据集上微调用于图像分类。
ViT工作原理解析
我们将上图展示的过程近一步分解为6步,接下来一步一步地来解析它的原理。如下图:
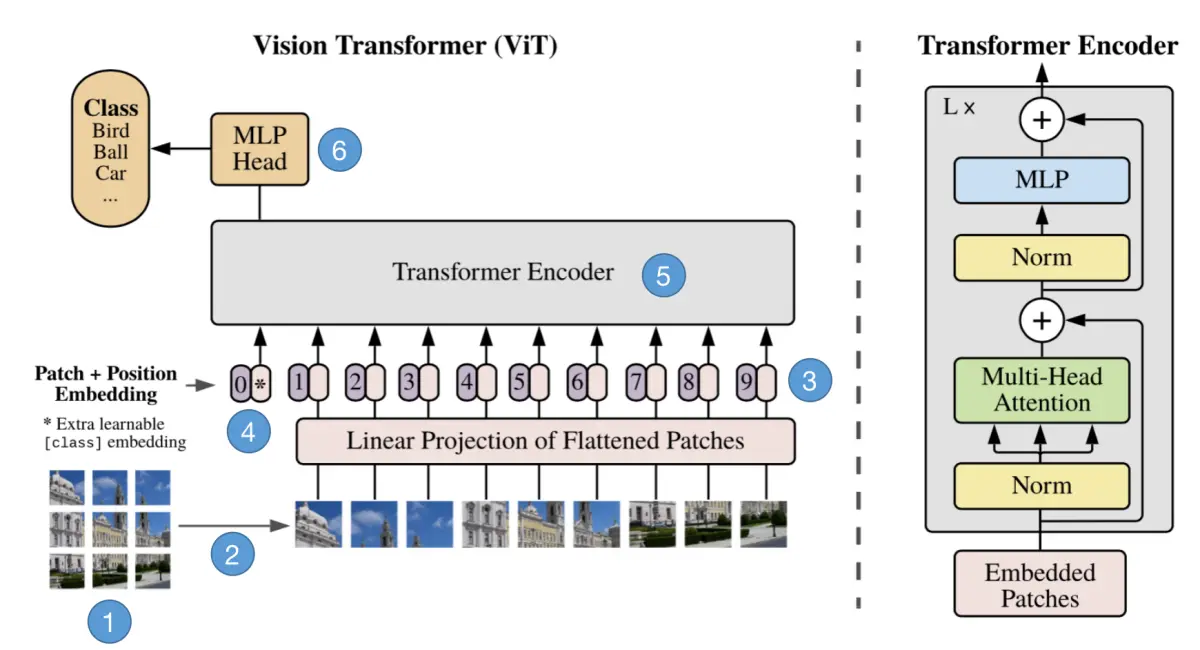
步骤1:将图片转换成patches序列
这一步很关键,为了让Transformer能够处理图像数据,第一步必须先将图像数据转换成序列数据,但是怎么做呢?假如我们有一张图片: x ∈ R H × W × C x \in R^{H \times W \times C} x∈RH×W×C,patch 大小为 p p p,那么我们可以创建 N N N个图像 patches,可以表示为 x p ∈ R ( p 2 C ) x_p \in R^{(p^2C)} xp∈R(p2C),其中 N = H W P 2 N = \frac{HW}{P^2} N=P2HW, N N N就是序列的长度,类似一个句子中单词的个数。在上面的图中,可以看到图片被分为了9个patches。
步骤2:将patches铺平
在原论文中,作者选用的 patches 大小为16,那么一个 patch 的 shape 为(3, 16, 16),维度为3,将它铺平之后大小为3x16x16=768。即一个 patch 变为长度为 768 的向量。
不过这看起来还是有点大,此时可以使用加一个 Linear transformation,即添加一个线性映射层,将 patch 的维度映射到我们指定的 embedding 的维度,这样就和NLP中的词向量类似了。
步骤3:添加Position embedding
与 CNNs 不同,此时模型并不知道序列数据中的 patches 的位置信息。所以这些 patches 必须先追加一个位置信息,也就是图中的带数字的向量。
实验表明,不同的位置编码 embedding 对最终的结果影响不大,在 Transformer 原论文中使用的是固定位置编码,在 ViT 中使用的可学习的位置 embedding 向量,将它们加到对应的输出 patch embeddings 上。文章来源地址https://www.yii666.com/blog/433888.html
步骤4:添加class token
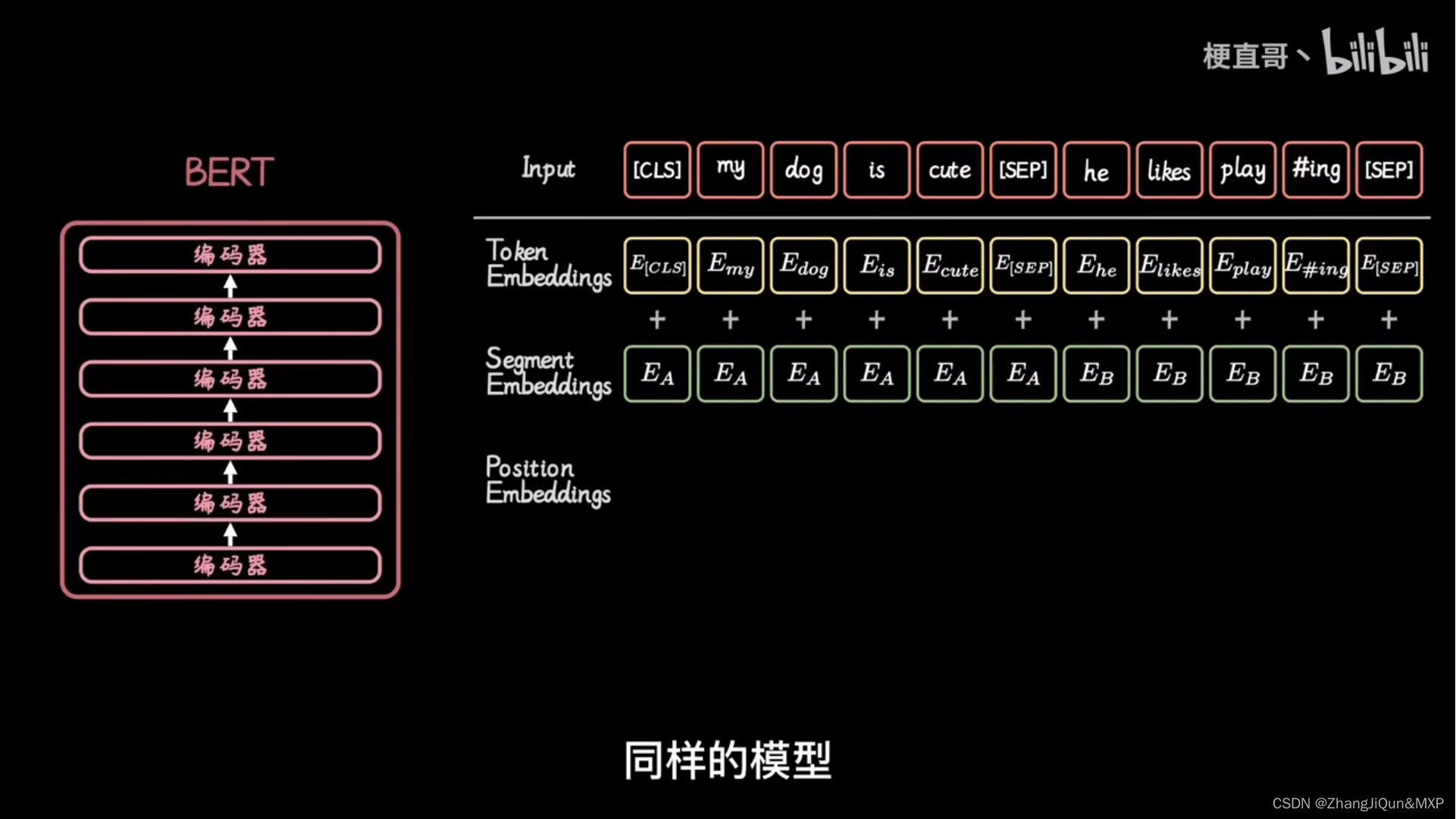
在输入到Transformer Encoder之前,还需要添加一个特殊的 class token,这一点主要是借鉴了 BERT 模型。
添加这个 class token 的目的是因为,ViT 模型将这个 class token 在 Transformer Encoder 的输出当做是模型对输入图片的编码特征,用于后续输入 MLP 模块中与图片 label 进行 loss 计算。
步骤5:输入Transformer Encoder
将 patch embedding 和 class token 拼接起来输入标准的Transformer Encoder中。
步骤6:分类
注意 Transformer Encoder 的输出其实也是一个序列,但是在 ViT 模型中只使用了 class token 的输出,将其送入 MLP 模块中,去输出最终的分类结果。
总结
ViT的整体思想还是比较简单,主要是将图片分类问题转换成了序列问题。即将图片patch转换成 token,以便使用 Transformer 来处理。
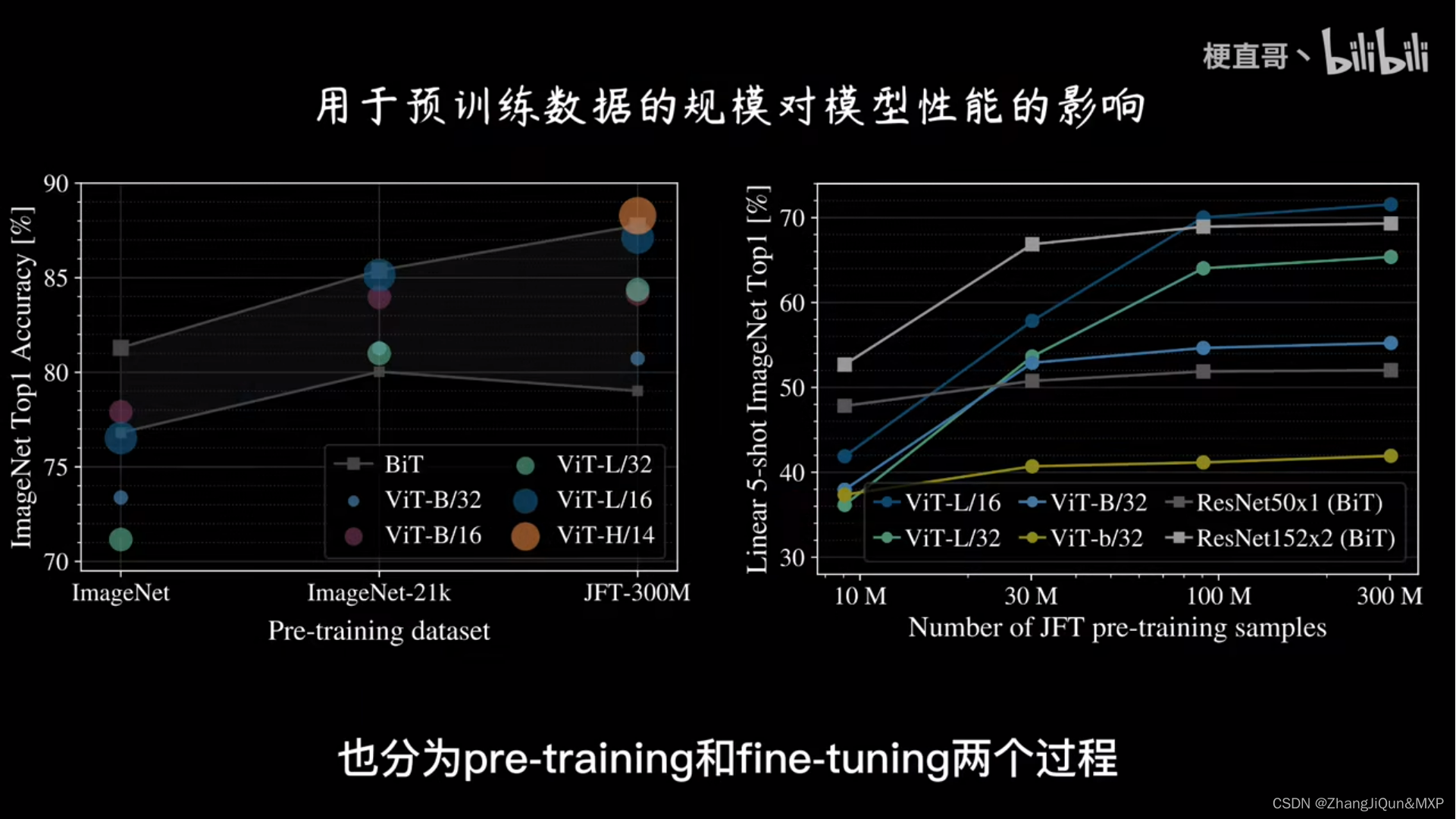
听起来很简单,但是 ViT 需要在海量数据集上预训练,然后在下游数据集上进行微调才能取得较好的效果,否则效果不如 ResNet50 等基于 CNN 的模型。
Vision Transformer(VIT)与卷积神经网络(CNN)相比
在某些情况下可以表现出更强的性能,这是由于以下几个原因:
全局视野和长距离依赖:ViT引入了Transform模型的注意力机制,可以对整个图像的全局信息进行建模。相比之下,CNN在处理图像时使用局部感受野,只能捕捉图像的局部特征。
ViT通过自注意力层可以建立全局关系,并学习图像中不同区域之间的长距离依赖关系,从而更好地理解图像的结构和语义。
可学习的位置编码:ViT通过对输入图像块进行位置编码,将位置信息引入模型中。这使得ViT可以处理不同位置的图像块,并学习它们之间的位置关系,
相比之下,CNN在卷积和池化过程中会导致空间信息的丢失,对位置不敏感。
数据效率和泛化能力:
ViT在大规模数据集上展现出出色的泛化能力。由于ViT基于Transform模型,它可以从大量的数据中学习到更丰富、更复杂的图像特征表示。
相比之下,CNN在小样本数据集上可能需要更多的数据和调优才能取得好的结果。
可解释性和可调节性:
ViT的自注意机制使其在解释模型预测和注意力权重时具有优势。
相比之下,CNN的特征表示通常较难解释,因为它们是通过卷积和池化操作获得的。