公司网站能自己做么黄页网络的推广软件
在昇腾AI处理器上训练PyTorch框架模型时,可能由于环境变量设置问题、训练脚本代码问题,导致打印出的堆栈报错与实际错误并不一致、脚本运行异常等问题,那么本期就分享几个关于PyTorch模型训练问题的典型案例,并给出原因分析及解决方法:
1、在训练模型时报错“Inner Error xxxx”,但打印的堆栈报错信息与实际错误无关
2、在模型训练时报错“terminate called after throwing an instance of 'c10::Error' what(): 0 INTERNAL ASSERT”
3、在模型训练时报错“MemCopySync:drvMemcpy failed.”
01 在训练模型时报错“Inner Error xxxx”,但打印的堆栈报错信息与实际错误无关
问题现象描述
报错截图举例:
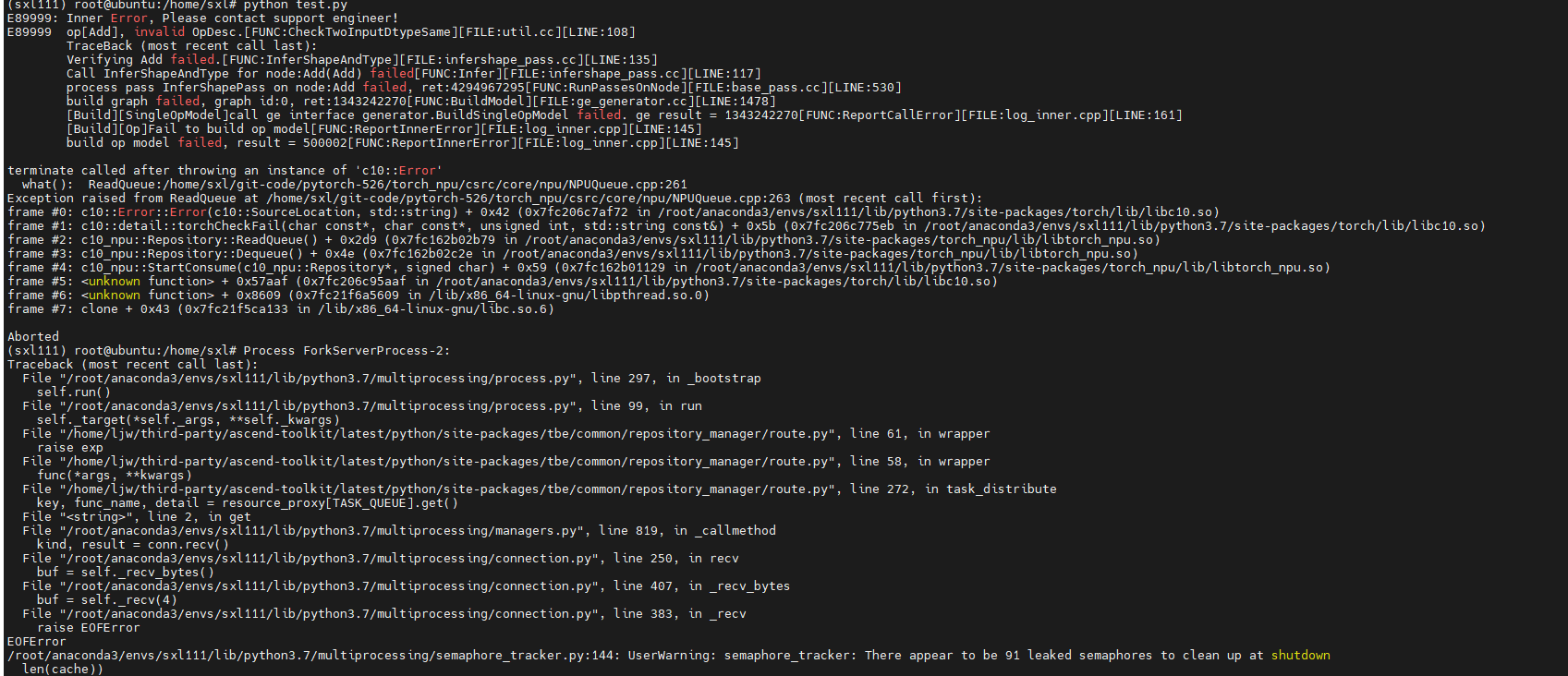
原因分析
NPU模型训练时默认为异步运行,因此打印出的堆栈报错与实际错误并不一致。如果想要打印出与实际错误相对应的堆栈报错信息,需要修改环境变量将运行模式改为同步运行。
解决措施
可以在以下方案中选择一种来解决该问题,然后再次运行模型,即可得到与实际错误一致的堆栈报错信息:
1、将环境变量TASK_QUEUE_ENABLE设置为0:
export TASK_QUEUE_ENABLE=02、若用户使用的PyTorch为2.1版本,也可将环境变量ASCEND_LAUNCH_BLOCKING修改为为1:
export ASCEND_LAUNCH_BLOCKING=102 在模型训练时报错“terminate called after throwing an instance of 'c10::Error' what(): 0 INTERNAL ASSERT”
问题现象描述
报错示例如下:
terminate called after throwing an instance of 'c10::Error' what(): 0 INTERNAL ASSERT FAILED at /***/pytorch/c10/npu/NPUStream.cpp:146, please report a bug to PyTorch. Could not compute stream ID for Oxffff9f77fd28 on device -1 (something has gone horribly wrong!) (NPUStream_getStreamId at /***/pytorch/c10/npu/NPUStream.cpp:146
frame #0: c10::Error::Error(c10::SourceLocation, std::__cxxll::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) + 0x74 (0xffffa0c11fe4 in /usr/local/lib64/python3.7/site.packages/torch/lib/libc10.so)原因分析
执行代码后出现报错。
import torch
import torch_npu
def test_cpu(): input = torch.randn(2000, 1000).detach().requires_grad_() output = torch.sum(input) output.backward(torch.ones_like(output))
def test_npu(): input = torch.randn(2000, 1000).detach().requires_grad_().npu() output = torch.sum(input) output.backward(torch.ones_like(output))
if __name__ == "__main__": test_cpu() torch_npu.npu.set_device("npu:0") test_npu()在运行backward运算时,若没有设置device,程序会自动默认初始化device为0,相当于执行了set_device("npu:0")。由于目前不支持切换device进行计算,若再通过set_decice()方法手动设置device设备,则可能出现该错误。
解决措施
在运行backward运算前,通过set_decice()方法手动设置device。
原代码如下:
if __name__ == "__main__":
test_cpu()
torch_npu.npu.set_device("npu:0")
test_npu()
修改后代码如下:
if __name__ == "__main__":
torch_npu.npu.set_device("npu:0")
test_cpu()
test_npu()
03 在模型训练时报错“MemCopySync:drvMemcpy failed.”
问题现象描述
- shell脚本报错信息如下:
RuntimeError: Run:/usr1/workspace/PyTorch_Apex_Daily_c20tr5/CODE/aten/src/ATen/native/npu/utils/OpParamMaker.h:280 NPU error,NPU error code is:500002
[ERROR] RUNTIME(160809)kernel task happen error, retCode=0x28, [aicpu timeout].
[ERROR] RUNTIME(160809)aicpu kernel execute failed, device_id=0, stream_id=512, task_id=24, fault so_name=, fault kernel_name=, extend_info=.
Error in atexit._run_exitfuncs:
Traceback (most recent call last):
File "/usr/local/python3.7.5/lib/python3.7/site-packages/torch/__init__.py", line 429, in _npu_shutdown torch._C._npu_shutdown()
RuntimeError: npuSynchronizeDevice:/usr1/workspace/PyTorch_Apex_Daily_c20tr5/CODE/c10/npu/NPUStream.cpp:806 NPU error, error code is 0- 日志报错信息如下:
[ERROR] RUNTIME(12731,python3.7):2021-02-02-22:23:56.475.679 [../../../../../../runtime/feature/src/npu_driver.cc:1408]12828 MemCopySync:drvMemcpy failed: dst=0x108040288000, destMax=1240, src=0x7fe7649556d0, size=1240, kind=1, drvRetCode=17!
[ERROR] RUNTIME(12731,python3.7):2021-02-02-22:23:56.475.698 [../../../../../../runtime/feature/src/logger.cc:113]12828 KernelLaunch:launch kernel failed, kernel=140631803535760/ArgMinWithValue_tvmbin, dim=32, stream=0x55b22b3def50
[ERROR] RUNTIME(12731,python3.7):2021-02-02-22:23:56.475.717 [../../../../../../runtime/feature/src/api_c.cc:224]12828 rtKernelLaunch:ErrCode=207001, desc=[module new memory error], InnerCode=0x70a0002原因分析
样例脚本如下:
import torch
import torch_npu
def test_sum(): xs_shape = [22400, 8] ys_shape = [22400, 8] gt_bboxes_shape = [22400, 8,4] xs = torch.rand(xs_shape).npu() ys = torch.rand(ys_shape).npu() gt_bboxes = torch.rand(gt_bboxes_shape).npu().half() left = xs - gt_bboxes[..., 0] right = gt_bboxes[..., 2] - xs top = ys - gt_bboxes[..., 1] bottom = gt_bboxes[..., 3] - ys # stream = torch_npu.npu.current_stream() # stream.synchronize() # left, top 结果是fp32, right, bottom 结果是fp16, # print(left.dtype, top.dtype, right.dtype, bottom.dtype) bbox_targets = torch.stack((left, top, right, bottom), -1) #报错位置在这里 # stream.synchronize() bbox_targets = torch.sum(bbox_targets)根据shell和日志报错信息,两者报错信息不匹配。shell报错是在同步操作中和AI CPU错误,而日志报错信息却是在min算子(内部调用ArgMinWithValue_tvmbin),二者报错信息不对应。一般这类问题出现的原因是由于日志生成的报错信息滞后。报错信息滞后可能是由于AI CPU算子的异步执行,导致报错信息滞后。
解决措施
对于该报错需要根据实际的错误来定位,可参考如下步骤进行处理:
1、通过关闭多任务算子下发后,发现结果不变,推断在shell脚本报错位置和日志报错算子之前就已出现错误。
2、根据报错加上stream同步操作,缩小错误范围,定位错误算子。stream同步操作的作用在于其要求代码所运行到的位置之前的所有计算必须为完成状态,从而定位错误位置。
3、通过在代码中加上stream同步操作,确定报错算子为stack。
4、打印stack所有参数的shape、dtype、npu_format,通过构造单算子用例复现问题。定位到问题原因为减法计算输入参数数据类型不同,导致a - b和b - a结果的数据类型不一致,最终在stack算子中报错。
5、将stack入参数据类型转换为一致即可临时规避问题。