网站专栏的作用广告联盟自动挂机赚钱
我是东哥,一名热爱技术的自媒体创作者。今天,我将为大家介绍一个非常有趣且强大的Python库——NLTK。无论你是刚刚接触Python的小白,还是对自然语言处理(NLP)有些许了解的朋友,NLTK都是一个值得学习的工具。
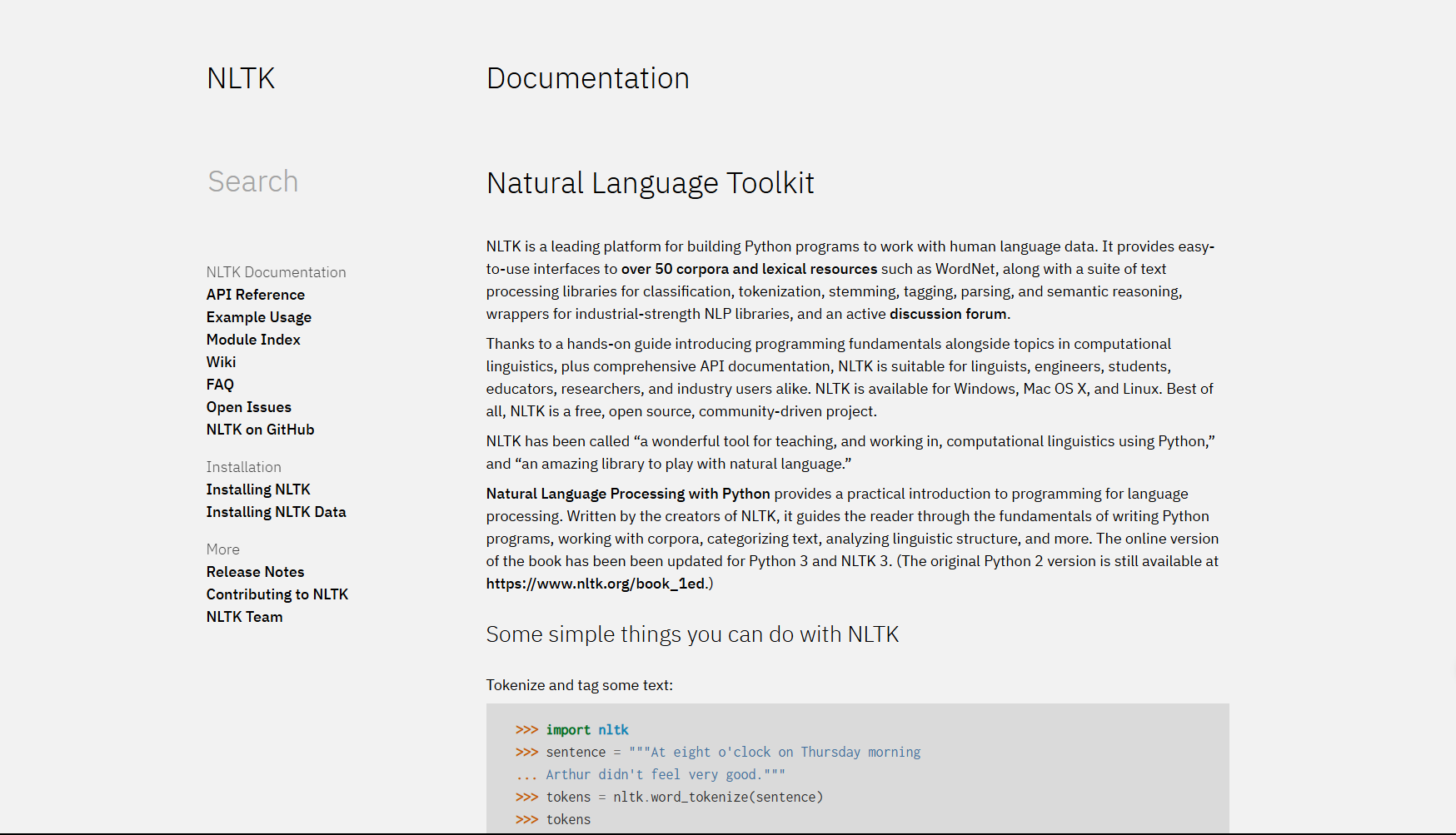
基本介绍
NLTK,全称Natural Language Toolkit,即自然语言处理工具包。它是一个用于构建Python程序以处理人类语言数据的平台。NLTK库包含了大量的语料库、词汇资源、分类器、语法分析器等,可以帮助我们进行文本分类、词性标注、命名实体识别、情感分析等各种自然语言处理任务。
项目地址:https://github.com/nltk/nltk
安装方法
安装NLTK非常简单,只需打开你的命令行工具,输入以下命令即可:
pip install nltk
安装完成后,你可以通过以下代码来下载NLTK的数据包,这些数据包包含了多种语料库和模型,是进行NLP任务的基础:
import nltknltk.download('all')
基本用法
让我们先从一些基础的例子开始,逐步揭开NLTK的神秘面纱。
案例1:分词
from nltk.tokenize import word_tokenize# 示例文本
text = "Hello, how are you doing today?"
# 使用NLTK进行分词
tokens = word_tokenize(text)
print(tokens)
输出将会是文本被分割成单词和标点的列表,如下:
['Hello', ',', 'how', 'are', 'you', 'doing', 'today', '?']
案例2:词性标注
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag# 示例文本
text = "The quick brown fox jumps over the lazy dog."
# 分词
tokens = word_tokenize(text)
# 词性标注
tagged_tokens = pos_tag(tokens)
print(tagged_tokens)
这里,我们会得到每个单词及其对应的词性标签,如下:
[('The', 'DT'), ('quick', 'JJ'), ('brown', 'NN'), ('fox', 'NN'), ('jumps', 'VBZ'), ('over', 'IN'), ('the', 'DT'), ('lazy', 'JJ'), ('dog', 'NN'), ('.', '.')]
高级用法
掌握了基本用法后,让我们来看看NLTK的一些高级功能。
案例3:情感分析
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
# 初始化情感分析器
sia = SentimentIntensityAnalyzer()
# 示例文本
text = "NLTK is amazing and I love using it for natural language processing."
# 进行情感分析
sentiment_score = sia.polarity_scores(text)
print(sentiment_score)
这个案例会输出一个字典,包含文本的负面、中性、正面和综合情绪分数,如下:
{'neg': 0.0, 'neu': 0.432, 'pos': 0.568, 'compound': 0.8885}
案例4:文本分类
import nltk
from nltk.corpus import movie_reviews
from nltk.classify import NaiveBayesClassifier
from nltk.classify.util import accuracy
# 准备数据
documents = [(list(movie_reviews.words(fileid)), category)for category in movie_reviews.categories()for fileid in movie_reviews.fileids(category)]
# 特征提取函数
def document_features(document):document_words = set(document)features = {}for word in word_features:features['contains({})'.format(word)] = (word in document_words)return features
# 选择常用的1000个词作为特征
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
word_features = list(all_words)[:2000]
# 特征化处理
featuresets = [(document_features(d), c) for (d,c) in documents]
# 划分训练集和测试集
train_set, test_set = featuresets[100:], featuresets[:100]
# 训练分类器
classifier = NaiveBayesClassifier.train(train_set)
# 测试分类器准确性
print(accuracy(classifier, test_set))
这个案例展示了如何使用NLTK进行简单的文本分类,虽然代码较长,但通过注释我们可以清晰地理解每一步的操作。输出如下:
0.86
小结
NLTK是一个功能强大的自然语言处理库,它简化了文本分析的流程,使得初学者也能快速上手。无论你是自然语言处理的新手还是有经验的研究者,NLTK都能成为你的得力助手。
希望这篇文章能让你对NLTK有一个基本的了解,并激发你探索更多可能。如果你有任何问题或想要深入探讨NLTK的其他功能,请随时留言。
东哥说AI后台回复008获取文中完整代码~