wordpress新建独立网页百中搜优化软件
机器学习
1.两位同事从上海出发前往深圳出差,他们在不同时间出发,搭乘的交通工具也不同,能准确描述两者“上海到深圳”距离差别的是:
A.欧式距离 B.余弦距离 C.曼哈顿距离 D.切比雪夫距离
S:D
1. 欧几里得距离
计算公式(n维空间下)
二维:dis=sqrt( (x1-x2)^2 + (y1-y2)^2 )
三维:dis=sqrt( (x1-x2)^2 + (y1-y2)^2 + (z1-z2)^2 )
2.余弦距离:余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。公式如下:
![]()
3.曼哈顿距离:两个点在标准坐标系上的绝对轴距总和
dis=abs(x1-x2)+abs(y1-y2)
4.切比雪夫距离:各坐标数值差的最大值
dis=max(abs(x1-x2),abs(y1-y2))
2.通过监督学习进行二分类模型训练过程中,可能会遇到正负样本数量不平衡的情况(比如正样本有50万但是负样本有100万),以下哪些方法可以对此进行恰当的处理?
A.将所有数据加入训练集,充分利用全部数据
B.从100万负样本中随机抽取50万
C.正样本的权重设置为2,负样本权重设置为1
D.复制两份正样本参与到训练中
S: BCD.
3.在高斯混合分布中,其隐变量的含义是:
A.表示高斯分布的方差 B.表示高斯分布的均值
C.表示数据分布的概率 D.表示数据从某个高斯分布中产生
S: D.
首选依赖GMM的某个高斯分量的系数概率(因为系数取值在0~1之间,因此可以看做是一个概率取值)选择到这个高斯分量,
然后根据这个被选择的高斯分量生成观测数据。然后隐变量就是某个高斯分量是否被选中:选中就为1,否则为0。
4.当训练样本数量趋向于无穷大时,在该数据集上训练的模型变化趋势,对于其描述正确的是()
A.偏差(bias)变小 B.偏差变大 C.偏差不变 D.不变
S: C
偏差大是欠拟合,方差大是过拟合。增大样本数量会降低方差,和偏差没关系。
5.通常来说,哪个模型被认为易于解释? ()
A.SVM B.Logistic Regression C.Decision Tree D.K-nearest Neghbor
S: C
6.假如你使用EM算法对一个有潜变量的模型进行最大似然估计(Maximum likelihood estimate)。这时候要求你将算法进行修改,使得其能找到最大后验分布(Maximum a Posteriori estimation, MAP),你需要修改算法的哪个步骤?
A.Expection B.Maimization C.不需要修改 D.都需要修改
S:A
E step根据当前参数进行估算,M step根据估算结果更新参数。那么修改估算方法自然在E step中。
7.影响基本K-均值算法的主要因素有()
A.样本输入顺序
B.模式相似性测度
C.聚类准则
D.初始类中心的选取
S:ABD
关于A,具体推导详见《模式识别》的动态聚类算法,书中提到,这是一个局部搜索算法,不能保证得到全局最优解,算法结果受初始值和样本调整顺序的影响。也就是说如果在迭代的过程中,数据集不够随机,很容易陷入局部最优。
8.以下哪些函数是凸函数?()
A. f(x) = x
B.f(x) = x^3
C.f(x) = x^4
D.f(x) = x^3+x^4
S: AC.
二阶导数非负
9.假设你有一个非常大的训练集合,如下机器学习算法中,你觉着有哪些是能够使用map-reduce框架并能将训练集划分到多台机器上进行并行训练的()
A.逻辑斯特回归(LR),以及随机梯度下降(SGD)
B.线性回归及批量梯度下降(BGD)
C.神经网络及批量梯度下降(BGD)
D.针对单条样本进行训练的在线学习
S: BC.
LR,SVM,NN,KNN,KMeans,DT,NB都可以用map reduce并行.
10.下列哪几个优化算法适合大规模训练集的场景:
A.minibatch sgd
B.Adam
C.LBFSG
D.FTRL
S: ABD.
FTRL是对每一维单独训练,属于一种在线学习优化算法。由于对参数的每一维单独训练,所以可以用于大规模数据训练。
11.随机变量X ~ N(1, 2),Y ~ N(3, 5),则X+Y ~()
A.N(4, 7) B.N(4,√2+ √5) C.N(1 + √3,7) D.不确定
S:D
主要看两个变量是否独立。独立条件下,正态加正态还是正态。Z=X+Y。均值加均值,方差加方差.
12.下列模型属于机器学习生成式模型的是()
A.朴素贝叶斯
B.隐马尔科夫模型(HMM)
C.马尔科夫随机场(Markov Random Fields)
D.深度信念网络(DBN)
S.ABCD
13.下列关于线性回归说法错误的是()
A.在现有模型上,加入新的变量,所得到的R^2的值总会增加
B.线性回归的前提假设之一是残差必须服从独立正态分布
C.残差的方差无偏估计是SSE/(n-p)
D.自变量和残差不一定保持相互独立
S: D.
R^2越大,拟合效果越好,因此A对。R^2=1-RSS/TSS
RSS数残差平方和 TSS是总的平方和
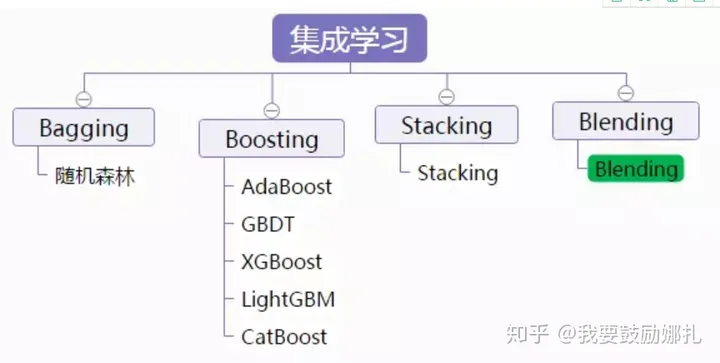
14.以下方法属于集成方法的是()
A. bagging B.stacking C.blending D.boosting
S: ABCD.
15.SVM(支持向量机)与LR(逻辑回归)的数学本质上的区别是什么?
A.损失函数 B.是否有核技巧 C.是否支持多分类 D.其余选项皆错
S: A
LR的损失函数从最大似然的角度理解;
SVM损失函数的原始形式则是从最大化分类间隔的角度出发。
16.SVM(支持向量机)为什么会使用替代损失函数(如hinge损失,指数损失等)?
A.替代损失函数可以扩大SVM的应用场景
B.0/1损失函数非凸、不连续
C.替代损失函数可以减少过拟合
D.其余选项皆错
S: B
直接使用0/1损失函数的话其非凸、非连续,数学性质不好优化起来比较复杂,因此需要使用其他的数学性能较好的函数进行替换,替代损失函数一般有较好的数学性质。常用的三种替代函数:
1、hinge损失;2、指数损失;3、对率损失;
17.L1正则和L2正则的共同点是什么?
A.都会让数据集中的特征数量减少
B.都会增大模型的偏差
C.都会增大模型方差
D.其余选项皆错
S: D
18.以下哪种方法不能防止过拟合?
A.交叉验证 B.低维嵌入 C.剪枝 D.集成学习
S:B
1、交叉检验,通过交叉检验得到较优的模型参数; 2、特征选择,减少特征数或使用较少的特征组合,对于按区间离散化的特征,增大划分的区间。 3、正则化,常用的有 L_1、L_2 正则。而且 L_1 正则还可以自动进行特征选择。 4、如果有正则项则可以考虑增大正则项参数 lambda. 5、增加训练数据可以有限的避免过拟合. 6、Bagging ,将多个弱学习器Bagging 一下效果会好很多,比如随机森林等。
From:
https://zhuanlan.zhihu.com/p/88107877